标题是浅谈,那么我也就不过多的深入钻研了
顶多算是说说定义,带大家看看代码
首先,AC自动机,很多人看了这个算法名字,就自然的很慌,就不敢学
其实静下心来,慢慢看,会发现其实比KMP还要容易理解(只不过是多模式串匹配,树形结构还很容易看出共同的前缀)
AC自动机其实是在Trie树上进行一个类似于KMP的匹配操作(来自某Dalao)
首先是要建一棵Trie字典树,具体如下:
void pre(){ int c=1; for(int i=1;i<=len;i++){ int f=a[i]-'a'; if(!trie[c][f]) trie[c][f]=++tot;//判断在之前是否出现过 c=trie[c][f]; } vis[c]++;//根据题目描述的不同改变 return ; }
然后是建立nxt数组,听着很难,我们不过多解释,只来说一下表面的意思
我们现在有两个串A,B
A:bb
B:ba
建立Trie树
如下: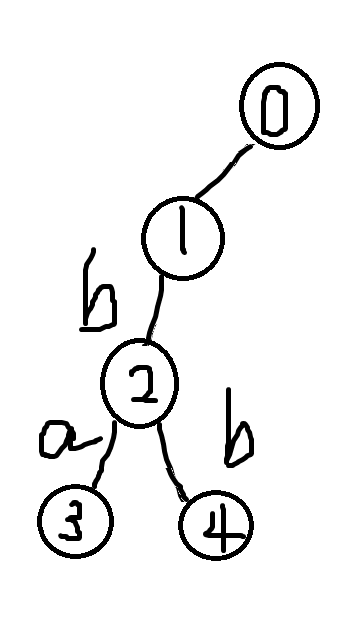
然后我们先不着急,来想一想nxt数组具体代表的是什么,很多博客都只是讲了如何操作,我先省去那一部分,来说说为什么我们要记录一个nxt
nxt[i]所代表的,适当你在节点i失配时,从哪里开始匹配
相当于是在AC自动机上找到一个位置的前缀等于当前匹配到的串的后缀
然后来看样例
2因为没有与之相同的,所以直接指向1
3是a,也没有相同的,也指向1
最后是4,我们发现ab得前缀b是与之对应的,所以4指向2
完成后如下:
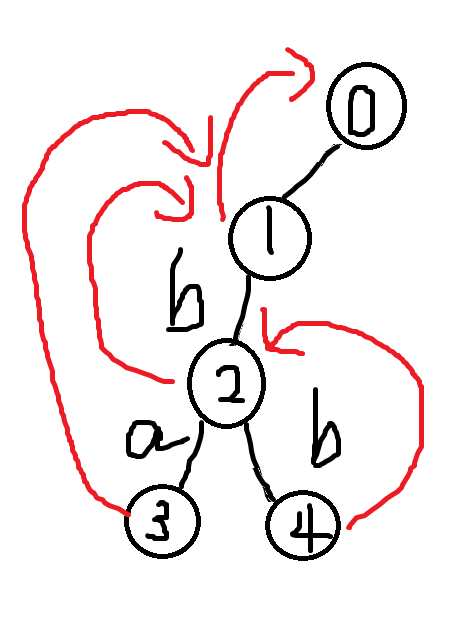
然后就是匹配了,和Trie树差不多,只不过是在失配的时候从nxt所指向的字符开始匹配
上一道板子题
|
试题描述
|
|
给定 n 个长度不超过 50 的由小写英文字母组成的单词准备查询,以及一篇长为 m 的文章,问:文中出现了多少个待查询的单词。多组数据。
|
|
输入
|
|
第一行一个整数 T,表示数据组数;
对于每组数据,第一行一个整数 n,接下去 n 行表示 n 个单词,最后一行输入一个字符串,表示文章。 |
|
输出
|
|
对于每组数据,输出一个数,表示文中出现了多少个待查询的单词。
|
|
输入示例
|
|
1
5 she he say shr her yasherhs |
|
输出示例
|
|
3
|
下面给出代码:
#include<iostream> #include<algorithm> #include<cstdio> #include<cstdlib> #include<cstring> #include<string> #include<cmath> #include<queue> using namespace std; inline long long rd(){ long long x=0,f=1; char ch=getchar(); for(;!isdigit(ch);ch=getchar()) if(ch=='-') f=-1; for(;isdigit(ch);ch=getchar()) x=x*10+ch-'0'; return x*f; } inline void write(long long x){ if(x<0) putchar('-'),x=-x; if(x>9) write(x/10); putchar(x%10+'0'); return ; } int T; char a[10006]; char s[1000006]; int trie[10006][36]; int vis[10006]; int len=0; int tot=1; void pre(){ int c=1; for(int i=1;i<=len;i++){ int f=a[i]-'a'; if(!trie[c][f]) trie[c][f]=++tot; c=trie[c][f]; } vis[c]++; return ; } int nxt[100006]; int ans=0; int q[100006]; int l=0,r=0; void get_next(){ l=0,r=0; for(int i=0;i<=25;i++) trie[0][i]=1; nxt[1]=0; q[++r]=1; while(l<r){ int h=q[++l]; for(int i=0;i<=25;i++){ if(!trie[h][i]) trie[h][i]=trie[nxt[h]][i];//便于查找,我们建立一个虚点, else{ nxt[trie[h][i]]=trie[nxt[h]][i];//一个点的nxt是它的父亲的nxt的和它一样的儿子,至于为什么,画个图就懂了 q[++r]=trie[h][i]; } } } return ; } void solve(){ int c=1; for(int i=1;i<=len;i++){ int f=s[i]-'a'; int k=trie[c][f]; while(k>1){ if(vis[k]){ ans+=vis[k]; vis[k]=0; } k=nxt[k]; } c=trie[c][f]; } return ; } int main(){ T=rd(); while(T--){ memset(vis,0,sizeof(vis)); memset(trie,0,sizeof(trie)); tot=1; ans=0; int n; n=rd(); for(register int i=1;i<=n;i++){ scanf("%s",a+1); len=strlen(a+1); pre();//建立Trie树 } scanf("%s",s+1); len=strlen(s+1); get_next(); solve(); write(ans); puts(""); } return 0; }