一、异常处理
1、错误和异常
1.程序中难免出现错误,而错误分成两种
(1)语法错误(这种错误过不了Python解释器的语法检测,必须在程序执行前改正)


#语法错误示范一 if #语法错误示范二 def test: pass #语法错误示范三 class Foo pass #语法错误示范四 print(haha 语法错误示范
(2)逻辑错误
#用户输入不完整(比如输入为空)或者输入非法(输入不是数字) num=input(">>: ") int(num) #无法完成计算 res1=1/0 res2=1+'str' 逻辑错误示范
2.什么是异常
异常就是程序运行时发生错误的信号,在python中,错误触发的异常如下:

3.Python中的异常种类
在python中不同的异常可以用不同的类型(python中统一了类与类型,类型即类)去标识,不同的类对象标识不同的异常,一个异常标识一种错误。
AttributeError 试图访问一个对象没有的树形,比如foo.x,但是foo没有属性x IOError 输入/输出异常;基本上是无法打开文件 ImportError 无法引入模块或包;基本上是路径问题或名称错误 IndentationError 语法错误(的子类) ;代码没有正确对齐 IndexError 下标索引超出序列边界,比如当x只有三个元素,却试图访问x[5] KeyError 试图访问字典里不存在的键 KeyboardInterrupt Ctrl+C被按下 NameError 使用一个还未被赋予对象的变量 SyntaxError Python代码非法,代码不能编译(个人认为这是语法错误,写错了) TypeError 传入对象类型与要求的不符合 UnboundLocalError 试图访问一个还未被设置的局部变量,基本上是由于另有一个同名的全局变量, 导致你以为正在访问它 ValueError 传入一个调用者不期望的值,即使值的类型是正确的 常用异常
ArithmeticError
AssertionError
AttributeError
BaseException
BufferError
BytesWarning
DeprecationWarning
EnvironmentError
EOFError
Exception
FloatingPointError
FutureWarning
GeneratorExit
ImportError
ImportWarning
IndentationError
IndexError
IOError
KeyboardInterrupt
KeyError
LookupError
MemoryError
NameError
NotImplementedError
OSError
OverflowError
PendingDeprecationWarning
ReferenceError
RuntimeError
RuntimeWarning
StandardError
StopIteration
SyntaxError
SyntaxWarning
SystemError
SystemExit
TabError
TypeError
UnboundLocalError
UnicodeDecodeError
UnicodeEncodeError
UnicodeError
UnicodeTranslateError
UnicodeWarning
UserWarning
ValueError
Warning
ZeroDivisionError
#触发IndexError l=['egon','aa'] l[3] #触发KeyError dic={'name':'egon'} dic['age'] #触发ValueError s='hello' int(s)
2、异常处理
2.1什么是异常处理?
python解释器检测到错误,触发异常(也允许程序员自己触发异常)。
程序员编写特定的代码,专门用来捕捉这个异常(这段代码与程序逻辑无关,与异常处理有关)。
如果捕捉成功则进入另外一个处理分支,执行你为其定制的逻辑,使程序不会崩溃,这就是异常处理。
2.2为何要进行异常处理?
python解析器去执行程序,检测到了一个错误时,触发异常,异常触发后且没被处理的情况下,程序就在当前异常处终止,后面的代码不会运行,谁会去用一个运行着突然就崩溃的软件。
所以你必须提供一种异常处理机制来增强你程序的健壮性与容错性 。
2.3 如何进行异常处理?
首先须知,异常是由程序的错误引起的,语法上的错误跟异常处理无关,必须在程序运行前就修正。
一: 使用if判断式
#_*_coding:utf-8_*_ __author__ = 'Linhaifeng' #第一段代码 num1=input('>>: ') #输入一个字符串试试 int(num1) #第二段代码 num2=input('>>: ') #输入一个字符串试试 int(num2) #第三段代码 num3=input('>>: ') #输入一个字符串试试 int(num3) 正常的代码
#_*_coding:utf-8_*_ __author__ = 'Linhaifeng' num1=input('>>: ') #输入一个字符串试试 if num1.isdigit(): int(num1) #我们的正统程序放到了这里,其余的都属于异常处理范畴 elif num1.isspace(): print('输入的是空格,就执行我这里的逻辑') elif len(num1) == 0: print('输入的是空,就执行我这里的逻辑') else: print('其他情情况,执行我这里的逻辑') #第二段代码 # num2=input('>>: ') #输入一个字符串试试 # int(num2) #第三段代码 # num3=input('>>: ') #输入一个字符串试试 # int(num3) ''' 问题一: 使用if的方式我们只为第一段代码加上了异常处理,针对第二段代码,你得重新写一堆if,elif等 第三段,你还得在写一遍,当然了,你说,可以合在一起啊,没错,你合起来看看,你的代码还能被看懂吗??? 而这些if,跟你的代码逻辑并无关系,这就好比你在你心爱的程序中到处拉屎,拉到最后,谁都不爱看你的烂代码,为啥,因为可读性差,看不懂 问题二: 第一段代码和第二段代码实际上是同一种异常,都是ValueError,相同的错误按理说只处理一次就可以了,而用if,由于这二者if的条件不同,这只能逼着你重新写一个新的if来处理第二段代码的异常 第三段也一样 ''' 使用if判断进行异常处理
总结:
1.if判断式的异常处理只能针对某一段代码,对于不同的代码段的相同类型的错误你需要写重复的if来进行处理。
2.在你的程序中频繁的写与程序本身无关,与异常处理有关的if判断,造成代码可读性极其的差。
3.这是可以解决异常的,只是存在1,2的问题,所以,千万不要妄下定论if不能用来异常处理。
二:python为每一种异常定制了一个类型,然后提供了一种特定的语法结构用来进行异常处理。
part1:基本语法
try: 被检测的代码块 except 异常类型: try中一旦检测到异常,就执行这个位置的逻辑
f=open('a.txt') g=(line.strip() for line in f) ''' next(g)会触发迭代f,依次next(g)就可以读取文件的一行行内容,无论文件a.txt有多大,同一时刻内存中只有一行内容。 提示:g是基于文件句柄f而存在的,因而只能在next(g)抛出异常StopIteration后才可以执行f.close() ''' f=open('a.txt') g=(line.strip() for line in f) for line in g: print(line) else: f.close() try: f=open('a.txt') g=(line.strip() for line in f) print(next(g)) print(next(g)) print(next(g)) print(next(g)) print(next(g)) except StopIteration: f.close()
part2:异常类只能用来处理指定的异常情况,如果非指定异常则无法处理。
# 未捕获到异常,程序直接报错 s1 = 'hello' try: int(s1) except IndexError as e: print e
part3:多分支
s1 = 'hello' try: int(s1) except IndexError as e: print(e) except KeyError as e: print(e) except ValueError as e: print(e)
part4:万能异常 在python的异常中,有一个万能异常:Exception,他可以捕获任意异常,即:
s1 = 'hello' try: int(s1) except Exception as e: print(e)
#可在多分支后面使用Exception s1 = 'hello' try: int(s1) except IndexError as e: print(e) except KeyError as e: print(e) except ValueError as e: print(e) except Exception as e: print(e)
part5:异常的其他结构
s1 = 'hello' try: int(s1) except IndexError as e: print(e) except KeyError as e: print(e) except ValueError as e: print(e) #except Exception as e: # print(e) else: print('try内代码块没有异常则执行我') finally: print('无论异常与否,都会执行该模块,通常是进行清理工作')
part6:主动触发异常
#_*_coding:utf-8_*_ try: raise TypeError('类型错误') except Exception as e: print(e)
part7:自定义异常
#_*_coding:utf-8_*_ class EgonException(BaseException): def __init__(self,msg): self.msg=msg def __str__(self): return self.msg try: raise EgonException('类型错误') except EgonException as e: print(e)
part8:断言
# assert 条件 assert 1 == 1 #满足assert 的条件才执行后面的代码 assert 1 == 2
part9:try..except的方式比较if的方式的好处
try..except这种异常处理机制就是取代if那种方式,让你的程序在不牺牲可读性的前提下增强健壮性和容错性。
异常处理中为每一个异常定制了异常类型(python中统一了类与类型,类型即类),对于同一种异常,一个except就可以捕捉到,可以同时处理多段代码的异常(无需‘写多个if判断式’)减少了代码,增强了可读性 。
使用try..except的方式
1:把错误处理和真正的工作分开来
2:代码更易组织,更清晰,复杂的工作任务更容易实现;
3:毫无疑问,更安全了,不至于由于一些小的疏忽而使程序意外崩溃了;
try...except应该尽量少用,因为它本身就是你附加给你的程序的一种异常处理的逻辑,与你的主要的工作是没有关系的
这种东西加的多了,会导致你的代码可读性变差。
二、socket编程
1、客户端/服务器架构
即C/S架构,包括
1.硬件C/S架构(打印机)
2.软件C/S架构(web服务)
美好的愿望:
最常用的软件服务器是 Web 服务器。一台机器里放一些网页或 Web 应用程序,然后启动 服务。这样的服务器的任务就是接受客户的请求,把网页发给客户(如用户计算机上的浏览器),然 后等待下一个客户请求。这些服务启动后的目标就是“永远运行下去”。虽然它们不可能实现这样的 目标,但只要没有关机或硬件出错等外力干扰,它们就能运行非常长的一段时间。
生活中的C/S架构:
老男孩是S端,所有的学员是C端
饭店是S端,所有的食客是C端
互联网中处处是C/S架构(黄色网站是服务端,你的浏览器是客户端;腾讯作为服务端为你提供视频,你得下个腾讯视频客户端才能看狗日的视频)
C/S架构与socket的关系:
我们学习socket就是为了完成C/S架构的开发。
2、osi七层
引子:
须知一个完整的计算机系统是由硬件、操作系统、应用软件三者组成,具备了这三个条件,一台计算机系统就可以自己跟自己玩了(打个单机游戏,玩个扫雷啥的)
如果你要跟别人一起玩,那你就需要上网了(访问个黄色网站,发个黄色微博啥的),互联网的核心就是由一堆协议组成,协议就是标准,全世界人通信的标准是英语,如果把计算机比作人,互联网协议就是计算机界的英语。所有的计算机都学会了互联网协议,那所有的计算机都就可以按照统一的标准去收发信息从而完成通信了。人们按照分工不同把互联网协议从逻辑上划分了层级,详见另一篇博客。
参考博客(网络通信原理):
http://www.cnblogs.com/linhaifeng/articles/5937962.html
http://www.cnblogs.com/maple-shaw/p/6891223.html
为何学习socket一定要先学习互联网协议:
1.首先:本节课程的目标就是教会你如何基于socket编程,来开发一款自己的C/S架构软件。
2.其次:C/S架构的软件(软件属于应用层)是基于网络进行通信的
3.然后:网络的核心即一堆协议,协议即标准,你想开发一款基于网络通信的软件,就必须遵循这些标准。
4.最后:就让我们从这些标准开始研究,开启我们的socket编程之旅。
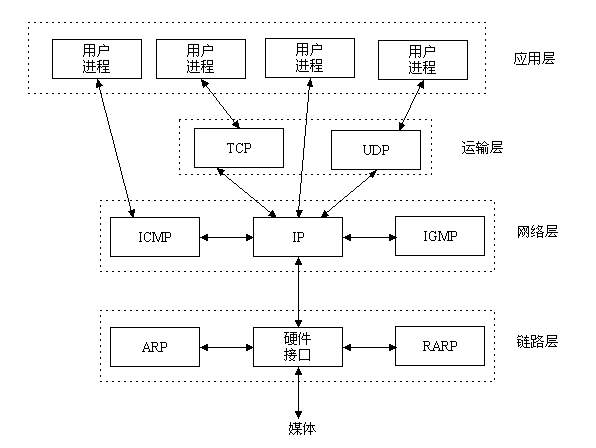
3、socket层

4、socket是什么
ocket是应用层与TCP/IP协议族通信的中间软件抽象层,它是一组接口。在设计模式中,Socket其实就是一个门面模式,它把复杂的TCP/IP协议族隐藏在Socket接口后面,对用户来说,一组简单的接口就是全部,让Socket去组织数据,以符合指定的协议。
所以,我们无需深入理解tcp/udp协议,socket已经为我们封装好了,我们只需要遵循socket的规定去编程,写出的程序自然就是遵循tcp/udp标准的。
也有人将socket说成ip+port,ip是用来标识互联网中的一台主机的位置,而port是用来标识这台机器上的一个应用程序,ip地址是配置到网卡上的,而port是应用程序开启的,ip与port的绑定就标识了互联网中独一无二的一个应用程序。而程序的pid是同一台机器上不同进程或者线程的标识。
5、套接字发展史及分类
套接字起源于 20 世纪 70 年代加利福尼亚大学伯克利分校版本的 Unix,即人们所说的 BSD Unix。 因此,有时人们也把套接字称为“伯克利套接字”或“BSD 套接字”。一开始,套接字被设计用在同 一台主机上多个应用程序之间的通讯。这也被称进程间通讯或 IPC。套接字有两种(或者称为有两个种族),分别是基于文件型的和基于网络型的。
基于文件类型的套接字家族
套接字家族的名字:AF_UNIX
unix一切皆文件,基于文件的套接字调用的就是底层的文件系统来取数据,两个套接字进程运行在同一机器,可以通过访问同一个文件系统间接完成通信
基于网络类型的套接字家族
套接字家族的名字:AF_INET
(还有AF_INET6被用于ipv6,还有一些其他的地址家族,不过,他们要么是只用于某个平台,要么就是已经被废弃,或者是很少被使用,或者是根本没有实现,所有地址家族中,AF_INET是使用最广泛的一个,python支持很多种地址家族,但是由于我们只关心网络编程,所以大部分时候我么只使用AF_INET)
6、套接字工作流程
一个生活中的场景。你要打电话给一个朋友,先拨号,朋友听到电话铃声后提起电话,这时你和你的朋友就建立起了连接,就可以讲话了。等交流结束,挂断电话结束此次交谈。生活中的场景就解释了这工作原理,也许TCP/IP协议族就是诞生于生活中,这也不一定。

先从服务器端说起。服务器端先初始化Socket,然后与端口绑定(bind),对端口进行监听(listen),调用accept阻塞,等待客户端连接。在这时如果有个客户端初始化一个Socket,然后连接服务器(connect),如果连接成功,这时客户端与服务器端的连接就建立了。客户端发送数据请求,服务器端接收请求并处理请求,然后把回应数据发送给客户端,客户端读取数据,最后关闭连接,一次交互结束。
socket()模块函数用法
import socket socket.socket(socket_family,socket_type,protocal=0) socket_family 可以是 AF_UNIX 或 AF_INET。socket_type 可以是 SOCK_STREAM 或 SOCK_DGRAM。protocol 一般不填,默认值为 0。 获取tcp/ip套接字 tcpSock = socket.socket(socket.AF_INET, socket.SOCK_STREAM) 获取udp/ip套接字 udpSock = socket.socket(socket.AF_INET, socket.SOCK_DGRAM) 由于 socket 模块中有太多的属性。我们在这里破例使用了'from module import *'语句。使用 'from socket import *',我们就把 socket 模块里的所有属性都带到我们的命名空间里了,这样能 大幅减短我们的代码。 例如tcpSock = socket(AF_INET, SOCK_STREAM)
服务端套接字函数
s.bind() 绑定(主机,端口号)到套接字
s.listen() 开始TCP监听
s.accept() 被动接受TCP客户的连接,(阻塞式)等待连接的到来
客户端套接字函数
s.connect() 主动初始化TCP服务器连接
s.connect_ex() connect()函数的扩展版本,出错时返回出错码,而不是抛出异常
公共用途的套接字函数
s.recv() 接收TCP数据
s.send() 发送TCP数据(send在待发送数据量大于己端缓存区剩余空间时,数据丢失,不会发完)
s.sendall() 发送完整的TCP数据(本质就是循环调用send,sendall在待发送数据量大于己端缓存区剩余空间时,数据不丢失,循环调用send直到发完)
s.recvfrom() 接收UDP数据
s.sendto() 发送UDP数据
s.getpeername() 连接到当前套接字的远端的地址
s.getsockname() 当前套接字的地址
s.getsockopt() 返回指定套接字的参数
s.setsockopt() 设置指定套接字的参数
s.close() 关闭套接字
面向锁的套接字方法
s.setblocking() 设置套接字的阻塞与非阻塞模式
s.settimeout() 设置阻塞套接字操作的超时时间
s.gettimeout() 得到阻塞套接字操作的超时时间
面向文件的套接字的函数
s.fileno() 套接字的文件描述符
s.makefile() 创建一个与该套接字相关的文件
7、基于TCP的套接字
TCP服务端
ss = socket() #创建服务器套接字 ss.bind() #把地址绑定到套接字 ss.listen() #监听链接 inf_loop: #服务器无限循环 cs = ss.accept() #接受客户端链接 comm_loop: #通讯循环 cs.recv()/cs.send() #对话(接收与发送) cs.close() #关闭客户端套接字 ss.close() #关闭服务器套接字(可选)
TCP客户端
1 cs = socket() # 创建客户套接字 2 cs.connect() # 尝试连接服务器 3 comm_loop: # 通讯循环 4 cs.send()/cs.recv() # 对话(发送/接收) 5 cs.close()
socket通信流程与打电话流程类似,我们就以打电话为例来实现一个low版的套接字通信:
#_*_coding:utf-8_*_ import socket ip_port=('127.0.0.1',9000) #电话卡 BUFSIZE=1024 #收发消息的尺寸 s=socket.socket(socket.AF_INET,socket.SOCK_STREAM) #买手机 s.bind(ip_port) #手机插卡 s.listen(5) #手机待机 conn,addr=s.accept() #手机接电话 # print(conn) # print(addr) print('接到来自%s的电话' %addr[0]) msg=conn.recv(BUFSIZE) #听消息,听话 print(msg,type(msg)) conn.send(msg.upper()) #发消息,说话 conn.close() #挂电话 s.close() #手机关机 服务端
#_*_coding:utf-8_*_ import socket ip_port=('127.0.0.1',9000) BUFSIZE=1024 s=socket.socket(socket.AF_INET,socket.SOCK_STREAM) s.connect_ex(ip_port) #拨电话 s.send('linhaifeng nb'.encode('utf-8')) #发消息,说话(只能发送字节类型) feedback=s.recv(BUFSIZE) #收消息,听话 print(feedback.decode('utf-8')) s.close() #挂电话 客户端
上述流程的问题是,服务端只能接受一次链接,然后就彻底关闭掉了,实际情况应该是,服务端不断接受链接,然后循环通信,通信完毕后只关闭链接,服务器能够继续接收下一次链接,下面是修改版:
#_*_coding:utf-8_*_ import socket ip_port=('127.0.0.1',8081)#电话卡 BUFSIZE=1024 s=socket.socket(socket.AF_INET,socket.SOCK_STREAM) #买手机 s.bind(ip_port) #手机插卡 s.listen(5) #手机待机 while True: #新增接收链接循环,可以不停的接电话 conn,addr=s.accept() #手机接电话 # print(conn) # print(addr) print('接到来自%s的电话' %addr[0]) while True: #新增通信循环,可以不断的通信,收发消息 msg=conn.recv(BUFSIZE) #听消息,听话 # if len(msg) == 0:break #如果不加,那么正在链接的客户端突然断开,recv便不再阻塞,死循环发生 print(msg,type(msg)) conn.send(msg.upper()) #发消息,说话 conn.close() #挂电话 s.close() #手机关机 服务端改进版
#_*_coding:utf-8_*_ import socket ip_port=('127.0.0.1',8081) BUFSIZE=1024 s=socket.socket(socket.AF_INET,socket.SOCK_STREAM) s.connect_ex(ip_port) #拨电话 while True: #新增通信循环,客户端可以不断发收消息 msg=input('>>: ').strip() if len(msg) == 0:continue s.send(msg.encode('utf-8')) #发消息,说话(只能发送字节类型) feedback=s.recv(BUFSIZE) #收消息,听话 print(feedback.decode('utf-8')) s.close() #挂电话 客户端改进版
问题:
有的同学在重启服务端时可能会遇到

这个是由于你的服务端仍然存在四次挥手的time_wait状态在占用地址(如果不懂,请深入研究1.tcp三次握手,四次挥手 2.syn洪水攻击 3.服务器高并发情况下会有大量的time_wait状态的优化方法)
解决方法:
#加入一条socket配置,重用ip和端口 phone=socket(AF_INET,SOCK_STREAM) phone.setsockopt(SOL_SOCKET,SO_REUSEADDR,1) #就是它,在bind前加 phone.bind(('127.0.0.1',8080))
发现系统存在大量TIME_WAIT状态的连接,通过调整linux内核参数解决, vi /etc/sysctl.conf 编辑文件,加入以下内容: net.ipv4.tcp_syncookies = 1 net.ipv4.tcp_tw_reuse = 1 net.ipv4.tcp_tw_recycle = 1 net.ipv4.tcp_fin_timeout = 30 然后执行 /sbin/sysctl -p 让参数生效。 net.ipv4.tcp_syncookies = 1 表示开启SYN Cookies。当出现SYN等待队列溢出时,启用cookies来处理,可防范少量SYN攻击,默认为0,表示关闭; net.ipv4.tcp_tw_reuse = 1 表示开启重用。允许将TIME-WAIT sockets重新用于新的TCP连接,默认为0,表示关闭; net.ipv4.tcp_tw_recycle = 1 表示开启TCP连接中TIME-WAIT sockets的快速回收,默认为0,表示关闭。 net.ipv4.tcp_fin_timeout 修改系統默认的 TIMEOUT 时间 方法二