场景:sql server 2008
1 drop table ID 2 CREATE TABLE ID 3 ( 4 id int identity(1,1) not null, 5 code int , 6 D date, 7 PRIMARY KEY (id) 8 ) 9 10 insert into ID(code,D) values(0001,getdate()) 11 insert into ID(code,D) values(0002,getdate()) 12 insert into ID(code,D) values(0002,getdate()) 13 insert into ID(code,D) values(0003,getdate()) 14 insert into ID(code,D) values(0003,'2017-08-02') 15 insert into ID(code,D) values(0003,'2017-08-01') 16 17 select * from ID
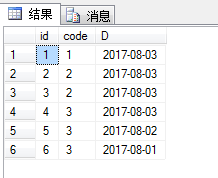
目标:
select COUNT(*) from ID group by code

产生code列唯一的3行数据,并显示最小的D列数据
方案1:
select code,MIN(D)
from ID group by code

方案2:
是否有重复code行
select COUNT(*) from ID where
code in(select code from ID group by code having COUNT(*) > 1)
@1
select * into #a from ID
delete from #a
where code in (select code from #a group by code having count(code) > 1)
and D not in (select min(D) from #a group by code having count(code) > 1)
select * from #a

删掉记录数最多的中一条数据
反复执行
方案3:
select code,D from
(
select MIN(D) from ID where COUNT(code)>1
)t1 right join ID t2 on t1.D=t2.D