对于简单、无状态的自定义操作,你也许可以通过 layers.core.Lambda 层来实现。但是对于那些包含了可训练权重的自定义层,你应该自己实现这种层。
这是一个 Keras2.0 中,Keras 层的骨架(如果你用的是旧的版本,请更新到新版)。你只需要实现三个方法即可:
build(input_shape): 这是你定义权重的地方。这个方法必须设self.built = True,可以通过调用super([Layer], self).build()完成。call(x): 这里是编写层的功能逻辑的地方。你只需要关注传入call的第一个参数:输入张量,除非你希望你的层支持masking。compute_output_shape(input_shape): 如果你的层更改了输入张量的形状,你应该在这里定义形状变化的逻辑,这让Keras能够自动推断各层的形状
本文主要讲解Self_attention方面的内容,这方面的知识是建立在attention机制之上的,因此若读者不了解attention mechanism的话,希望你们能去看我的关于深入理解attention机制。本人也将在这里稍微的解释一下。
对于encoder-decoder模型,decoder的输入包括(注意这里是包括)encoder的输出。但是根据常识来讲,某一个输出并不需要所有encoder信息,而是只需要部分信息。这句话就是attention的精髓所在。怎么理解这句话呢?举个例子来说:假如我们正在做机器翻译,将“I am a student”翻译成中文“我是一个学生”。根据encoder-decoder模型,在输出“学生”时,我们用到了“我”“是”“一个”以及encoder的输出。但事实上,我们或许并不需要“I am a ”这些无关紧要的信息,而仅仅只需要“student”这个词的信息就可以输出“学生”(或者说“I am a”这些信息没有“student”重要)。这个时候就需要用到attention机制来分别为“I”、“am”、“a”、“student”赋一个权值了。例如分别给“I am a”赋值为0.1,给“student”赋值剩下的0.7,显然这时student的重要性就体现出来了。具体怎么操作,我这里就不在讲了。
2、self-attention
self-attention显然是attentio机制的一种。上面所讲的attention是输入对输出的权重,例如在上文中,是I am a student 对学生的权重。self-attention则是自己对自己的权重,例如I am a student分别对am的权重、对student的权重。之所以这样做,是为了充分考虑句子之间不同词语之间的语义及语法联系。
那么这个权值应该怎么计算呢?我在别处看到的图片以及我自己的理解如下:

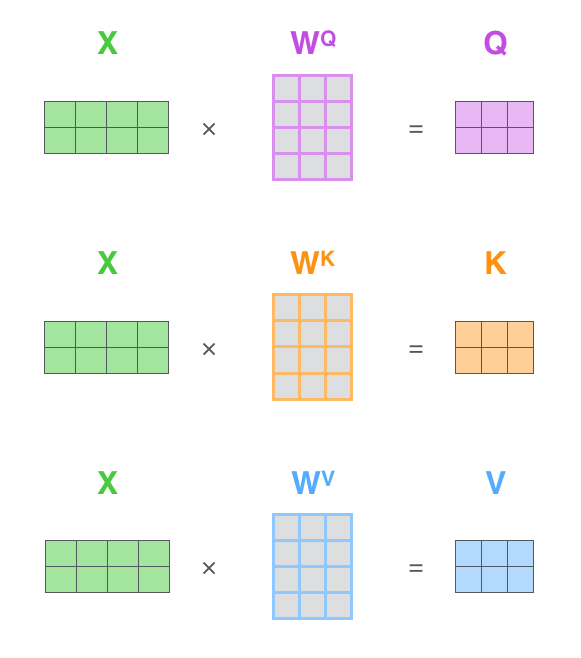
注释:qkv分别对应attention机制中的QKV,它们是通过输入词向量分别和W(Q)、W(K)、W(V)做乘积得到的。其目的主要是计算权值。
注释:q与k做点乘、然后归一化,就得到权值(乘积越大,相似度越高,权值越高)。得到的两个权值分别与v相乘后,再相加就是输出。同理就可以得到另一个单词的输出。
以上是一个单词一个单词的输出,如果写成矩阵形式就是Q*K,得到的矩阵归一化直接得到权值。
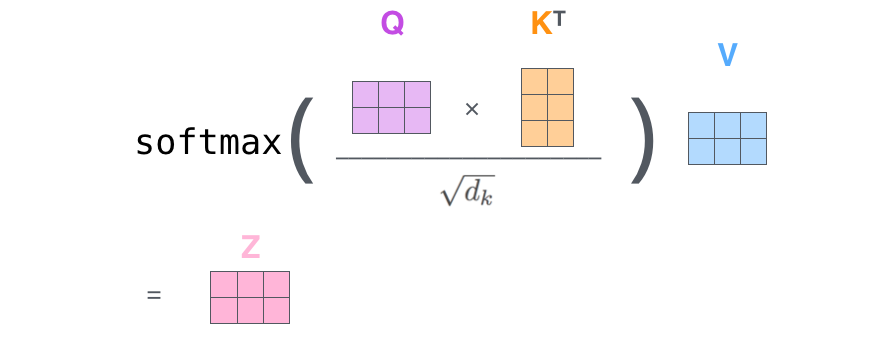
#self-attentiom模型的搭建:
from keras.preprocessing import sequence
from keras.datasets import imdb
from matplotlib import pyplot as plt
import pandas as pd
from keras import backend as K
from keras.engine.topology import Layer
class Self_Attention(Layer):
def __init__(self, output_dim, **kwargs):
self.output_dim = output_dim
super(Self_Attention, self).__init__(**kwargs)
def build(self, input_shape):
# 为该层创建一个可训练的权重
#inputs.shape = (batch_size, time_steps, seq_len)
self.kernel = self.add_weight(name='kernel',
shape=(3,input_shape[2], self.output_dim),
initializer='uniform',
trainable=True)
super(Self_Attention, self).build(input_shape) # 一定要在最后调用它
def call(self, x):
WQ = K.dot(x, self.kernel[0])
WK = K.dot(x, self.kernel[1])
WV = K.dot(x, self.kernel[2])
print("WQ.shape",WQ.shape)
print("K.permute_dimensions(WK, [0, 2, 1]).shape",K.permute_dimensions(WK, [0, 2, 1]).shape)
QK = K.batch_dot(WQ,K.permute_dimensions(WK, [0, 2, 1]))
QK = QK / (64**0.5) #64*5是归一化的值,不同问题不一样
QK = K.softmax(QK)
print("QK.shape",QK.shape)
V = K.batch_dot(QK,WV)
return V
def compute_output_shape(self, input_shape):
return (input_shape[0],input_shape[1],self.output_dim)
在Keras上对IMDB进行简单的测试(不做Mask):
from __future__ import print_function
from keras.preprocessing import sequence
from keras.datasets import imdb
max_features = 20000
maxlen = 80
batch_size = 32
print('Loading data...')
(x_train, y_train), (x_test, y_test) = imdb.load_data(num_words=max_features)
print(len(x_train), 'train sequences')
print(len(x_test), 'test sequences')
print('Pad sequences (samples x time)')
x_train = sequence.pad_sequences(x_train, maxlen=maxlen)
x_test = sequence.pad_sequences(x_test, maxlen=maxlen)
print('x_train shape:', x_train.shape)
print('x_test shape:', x_test.shape)
from keras.models import Model
from keras.layers import *
S_inputs = Input(shape=(None,), dtype='int32')
embeddings = Embedding(max_features, 128)(S_inputs)
# embeddings = Position_Embedding()(embeddings) # 增加Position_Embedding能轻微提高准确率
O_seq = Attention(8,16)([embeddings,embeddings,embeddings])
O_seq = GlobalAveragePooling1D()(O_seq)
O_seq = Dropout(0.5)(O_seq)
outputs = Dense(1, activation='sigmoid')(O_seq)
model = Model(inputs=S_inputs, outputs=outputs)
# try using different optimizers and different optimizer configs
model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy'])
print('Train...')
model.fit(x_train, y_train,
batch_size=batch_size,
epochs=5,
validation_data=(x_test, y_test))
参考博客:
https://blog.csdn.net/xiaosongshine/article/details/90600028