一 分类概述

二 分类实例
现在我们以宝可梦为例,宝可梦共有18中属性,如下:

上边的宝可梦输入是形象化的表示,我们应该讲宝可梦以计算机可以识别的数值进行输入

那么可能我们会问,为什么我们要预测宝可梦的类型呢,这是因为不同类型的宝可梦相遇时,他们是有属性相克的关系。

那么如何分类呢?我们之前提到过regression,可能会有人会按照regression的思路进行分类。

如果你按照上边的方式进行,你会遇到如下问题

那么我们应该怎么做呢?

本次不采用Perceptron 与 SVM,用另一种方式解决这个问题。
引子:

由上边可以延伸出
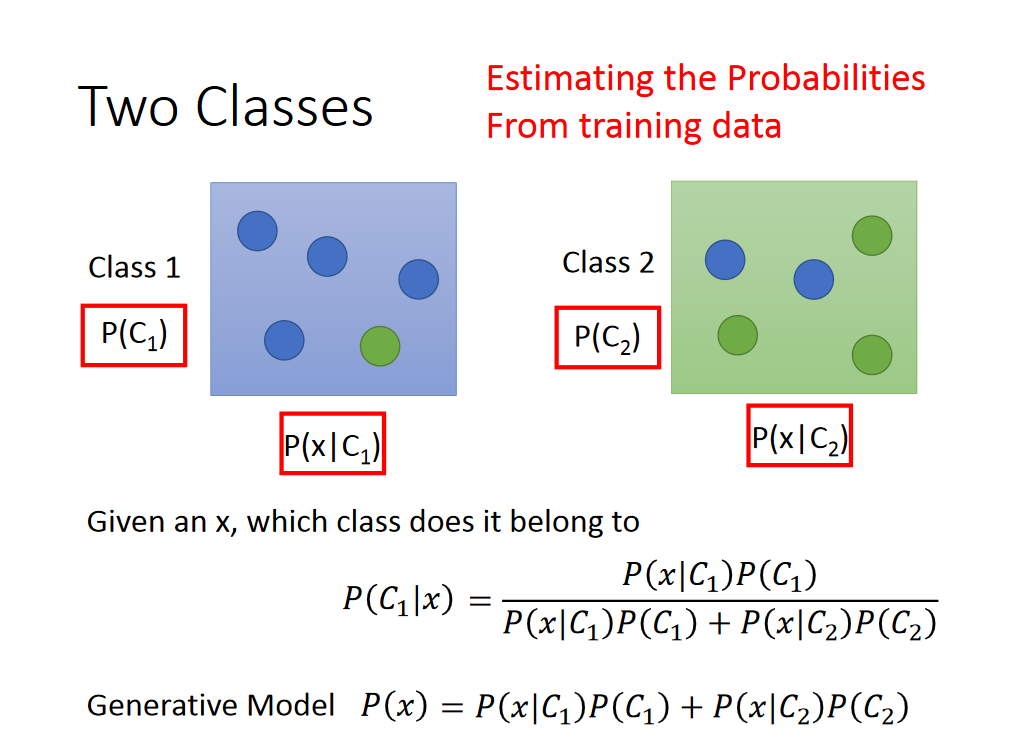
先算p(c1)与p(c2),这一部分叫做prior。

接着算p(x | c1),如下:


下边简单的介绍高斯分布



那么怎么找到这个高斯分布呢?---->使用Maximum Likelihood


现在我们算我们实例的真正结果

有了上述结果,我们就可以分类了,分类依据如下

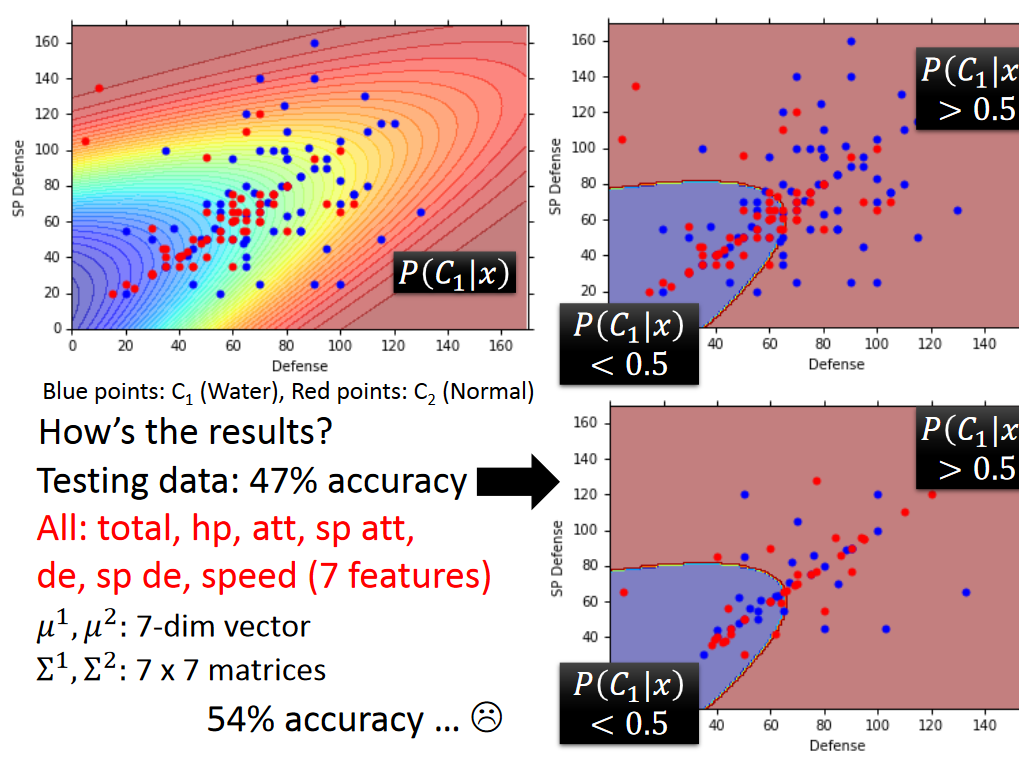
真实结果:从左至右,从上往下,第一张图是water 和normal 宝可梦的分布,第二张图是分类结果,第三个是在测试集上的分类结果,其中正确率只有47%,我们增加特征值,考虑7个维度的特征,最后结果的正确率也只有54%
这时候我们就应该将model优化

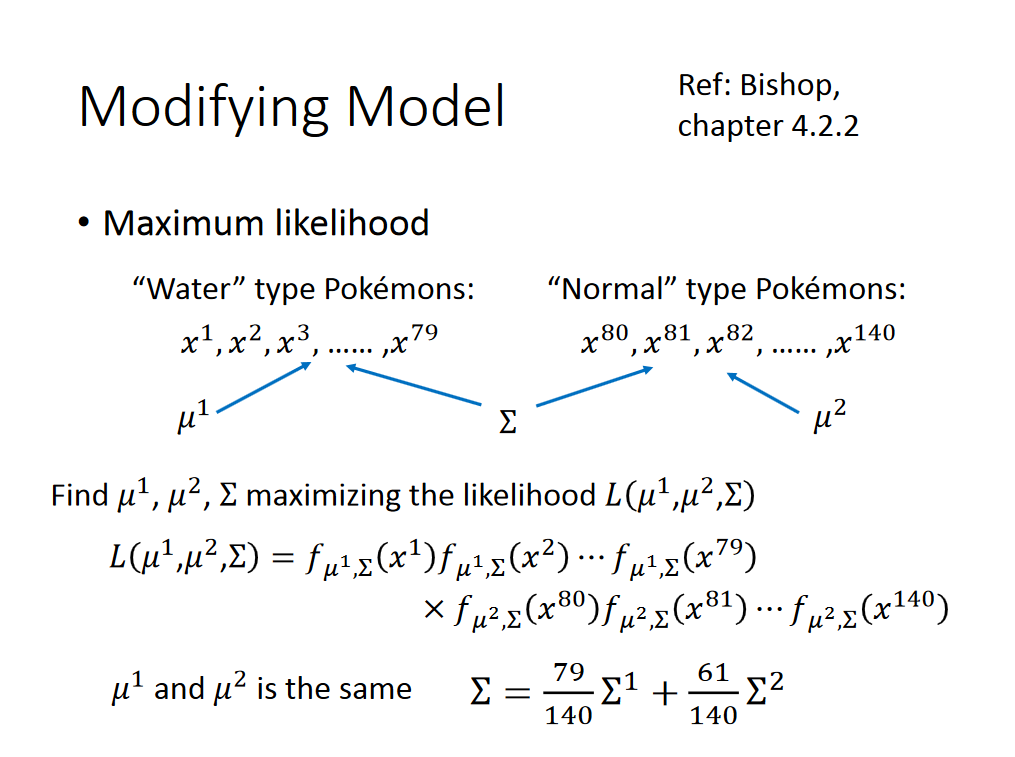
优化后的model结果如下:考虑7个特征,分类准确率由之前的54%上升到73%,确实性能优化。

现在我们回顾整个的思路

可能会有人问,为什么选高斯分布呢,当然也可以选择其他的分布

后验概率

补充一些高数知识



将sigmoid简化

最后可能会有这样的疑惑,在generative model里面,我们找到N1,N2,u1,u2,∑,得到w和b,然后就可以算概率。为什么我们不直接得到w和b呢?---->logistics regression会讲直接得到w 和b。
参考:http://speech.ee.ntu.edu.tw/~tlkagk/courses/ML_2016/Lecture/Classification%20(v3).pdf