motivation
本文研究发现,BERT等预训练模型经常会关注文本的语义特征进行推理,而不是去学习句子表达的逻辑。
COPA
COPA任务关注于寻找给定前提(premise)的情况下的因(causal)或果(effect),如下面的例子。
Premise: The man broke his toe. What was the CAUSE of this?
Alternative 1: He got a hole in his sock.
Alternative 2: He dropped a hammer on his foot.
Premise: I tipped the bottle. What happened as a RESULT?
Alternative 1: The liquid in the bottle froze.
Alternative 2: The liquid in the bottle poured out.
Premise: I knocked on my neighbor's door. What happened as a RESULT?
Alternative 1: My neighbor invited me in.
Alternative 2: My neighbor left his house.
BERT的问题
在下面的例子中,BERT出现了错误。
Premise: The woman banished the children from her property.
ask-for: “cause”
Alt1: The children hit a ball into her yard. × (effect)
Alt2: The children trampled through her garden. √ (cause)
原因是BERT在做选择题的时候,有时会关注选项与问题的语义一致性,而没有真正地去学习因果关系。
Method
作者将损失加了一部分,如下所示。
其中\(L_{CE}\)表示最小化预测损失的交叉熵,\(L_{Reg}\)表示一个正则化损失,这一项使得模型在见到前提和选项,却是相反的问题类型时,保持中立,因为这两个选项都不是正确答案。
The extra regularization loss requires that a model should be neutral when it sees the opposite question type for the same premise and same alternatives, since neither alternative is the correct answer.
通常在实验中设置\(\lambda = 0.01\)。
实验
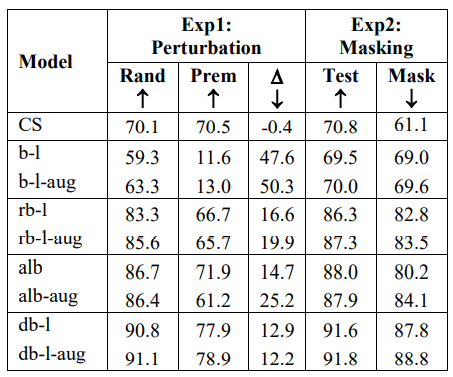
作者为了证明BERT模型对语义相关性的依赖很大,针对COPA任务设计了下面两个实验。
Perturbation
在这个实验中,作者将原来任务中的二选一变成了三选一:每个问题中都把原来的前提premise加到选项里面去,这样模型会发现选项中多了一个和问题语义最接近的选项(完全相同),从而干扰模型。
为了和之前的对比,需要消除任务本省难度的增加程度,毕竟从二选一变成三选一可能会降低准确率,因此作者还设计了另外一种干扰方法:在原来的两个选项的基础上,随机添加一个其他的句子作为新的选项,这样也是三选,可是语义相似度或许会相差很多。
称第一种方法为COPA-premise,第二种称为COPA-random。
Masking Question Type
这个实验随机让一半的问题的类型(问因还是果)反转,这样有些问题就没有正确答案,如果在这种情况下,模型还有很高的准确率,说明不鲁棒。