介绍
在图像识别和目标分类领域往往存在一些关于图像中虚假相关性的问题,最典型的如将图像中识别的主体(object)和背景(background)之间的相关性考虑成为识别主题类别的一个主要特征。如下图所示,注意力模型将ground作为一个判断为鸟类的标签,在预测地上的熊的时候就做出了错误的判断。这种在不一样的场景下的图片,反而往往是在特殊紧急时,错误会十分致命。

图1
将问题形式化描述:数据集包含输入图像\(X\),标签\(Y\),标签被通用的混淆因子——背景\(S\)所影响,模型学习了潜在的虚假因果,将\(S\)作为识别\(Y\)的特征。
有一种方式是通过因果干预来减轻混淆偏差。例如收集bird类别在所有场景下的图像。这样模型就会只关注于object本身。然而在实际应用中这种方式消耗人力比较大。
在实际应用中,不可能找到某个类别在所有场景下的,如在天空中就不容易找到。而从技术上讲,这种方式违背了混淆的正性原则。因此需要将多个类别混合在一起(如图2中混合地面和水)。
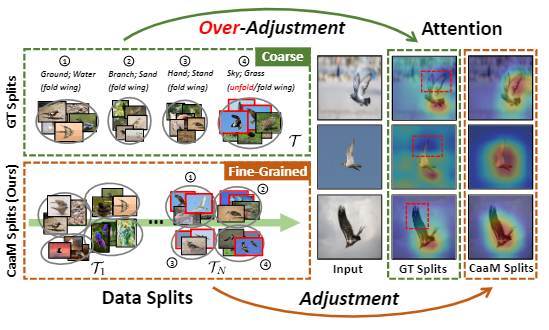
图2
然而这种粗背景的划分方式会导致过度调整(over-adjustment)的问题,这种干预方式不仅会移除背景,还会损伤原本object中有用的特征,图2展示了一个实例,鸟的翅膀在天空的背景下都是打开的,而在陆地等背景下是折叠的,因此陆地背景其实损坏了翅膀这个特征。图中的split 4不仅表达了“天空”和“草地”,也表达了“翅膀”这个信息。将这个问题称为“不合适的因果干预”(improper causal intervention)。
在本文中,作者提出一种因果注意力模型——CaaM,迭代生成数据的每个部分,并且逐渐地自行标注(self-annotates)混淆因子,克服over-adjustment问题。与更粗的上下文相比,多个CaaM分区粒度更细,更准确地描述了全面的混杂。如图2左下所示,最后\(\mathcal{T}_N\)的每一个split都包含展开翅膀的图像,翅膀特征就不再和背景具有相关性了。从技术上讲,除了注意力机制试图学习因果特征,CaaM还具有一种互补的注意,故意捕捉混淆效应(如背景)。两个解纠缠注意以对抗极小极大的方式进行优化,它们逐渐构成混杂集,并以无监督的方式对混杂偏置进行控制。
CaaM:Causal Attention Module
因果知识
有偏情境下的因果视图
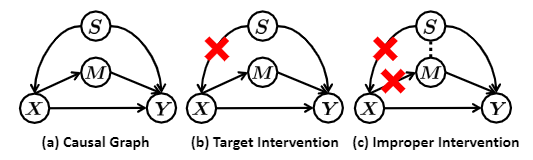
图3
在有偏差的情况下,因果图如图3(a)所示,\(X\)为输入图像,\(Y\)为标签,\(S\)混淆因子,\(M\)中介变量。
- \(X\rightarrow Y\)表示图像内容对\(Y\)的直接影响。
- \(X \leftarrow S \rightarrow Y\),在这里\(S\)不再单纯表示背景,而是图片的上下文混淆,决定图像主题和背景如何在\(X\)上面布局,因此\(S\)决定\(X\),而这种布局和背景不可避免地会影响标签\(Y\)。
- \(X \rightarrow M \rightarrow Y\)表示图像中的有用因果特征,\(M\)表示的特征不会随着域的迁移而产生分布的变化。虽然\(X \rightarrow M \rightarrow Y\)可以被隐藏在\(X \rightarrow Y\)的路径中,但是为了方便推导,我们还是将其分离出来。
基于数据分块的干预
数据分块(data partition)是一种进行因果干预的有效方法。首先它将原始硬分割成\(\mathcal{T}=\{t_1, \cdots,t_m\}\),其中每一份都表示一个混淆层,这种方法的效果等同于后门调整:
在每一个split上面训练相当于模拟\(P(Y|X,t)\)的分布,如图3(b)所示,它剪断了\(X \leftarrow S \rightarrow Y\)的后门路径。然而现有的方法在某些split上只有很少的数据,离公式1的要求差距还比较大。
不合适的因果干预
由于现有的标注方法很难解耦混淆(\(S\))和因果特征(\(M\)),因此如公式1所示的基于上下文的干预很难实现。下面作者展示如何正确地使用因果干预。
假设划分\(\mathcal{T}\)只包含混淆,那么我们可以通过屏蔽\(M\)来减轻\(S\)的影响。1式可以写作
然而当每个分割\(\mathcal{T}\)
中既包含\(S\)也包含\(M\),那么就会导致\(S\)与\(M\)不独立。式2演变为式3。
此时\(X \rightarrow M \rightarrow Y\)这条边就收到了损害,如图3(c)所示。
原文说的是剪断这条边,但是我认为这个说法有点奇怪,应该是\(M\)的部分随着\(\mathcal{T}\)的划分,因果特征\(M\)的一部分与\(X\)已经独立了,所以这条边收到损伤)
训练流程
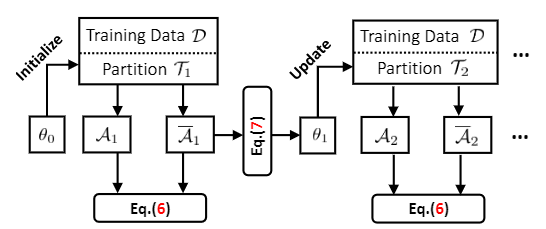
训练流程如图4所示。为了扩大每个split的大小,作者在每一步挖掘部分\(\mathcal{T}_i\),在\(N\)轮迭代之后,我们可以将1式近似为\(P(Y|do(X)) \approx\sum_i^N \sum_{t \in \mathcal{T}_i} P(Y|X, t)P(t)\)。
为了将混淆因子和中介变量\(M\)分开,我们设计两个注意力模块\(A, \overline{A}\),其中\(A\)是为了计算因果特征,而\(\overline{A}\)计算混淆特征,二者角色相反。对抗训练促进解耦,
然后我们使用\(\overline{A}\)来更新\(\mathcal{T}_i\)。下面介绍训练损失的详细内容。
交叉熵损失
这个损失是为了保证\(A\)和\(\overline{A}\)的结合可以捕捉到\(X \rightarrow Y\)的总偏差效应,而不考虑因果或者混淆的影响,否则,他们可能违反图3(a)中的数据生成机制。
注意这种有偏训练广泛应用于无偏模型(没看懂)。
其中\(\tilde{x}=\mathcal{A}(x) \circ \overline{\mathcal{A}}(x)\),\(\circ\)表示特征相加,\(f\)为线性分类器,\(\mathscr{l}\)为交叉熵损失。
不变损失
这个损失是用来学习\(\mathcal{A}\)的,
它是由式1中的因果干预造成的split不变量,通过不完全混杂分区\(\mathcal{T}_i\)计算:
其中\(t\)是数据分组,\(g\)是用来预测鲁棒特征的线性网络,\(\mathrm{w}\)表示一个虚拟用于计算跨越分割的梯度惩罚的分类器,\(\lambda\)是权值。在推理阶段,\(g(\mathcal{A}(x))\)被用于无偏识别。
对抗训练
训练过程通过一个最小化游戏(Mini-Game)和一个最大化游戏(Maxi-Game)来分开\(\mathcal{A}\)和\(\overline{\mathcal{A}}\)。
- 最大化游戏提取\(\overline{\mathcal{A}}(x)\)中的混淆特征,来生成数据块\(\mathcal{T}_i\),因果特征不对最大化产生贡献。
- 最小化游戏排除\(\mathcal{A}(x)\)中的混淆特征,混淆特征不对最小化产生贡献。
最小化游戏(Mini-Game)
这是一个\(\mathrm{XE}\)和\(\mathrm{IL}\)的联合训练过程,加上一个新的对抗分类器\(h\),\(h\)专门用于研究由\(\overline{\mathcal{A}}(x)\)引起的混淆效应。
最大化游戏(Maxi-Game)
一个好的数据块更新应该捕捉那些在split中变化的强混淆。
其中\(\mathcal{T}_i(\theta)\)指的是数据块\(\mathcal{T}_i\)由参数\(\theta \in \mathbb{R}^{K \times m}\),\(K\)为总训练数据量,而\(m\)是一个划分中的split数量。\(\theta_{p,q}\)指的是第\(p\)个sample属于第\(q\)个split的概率。
CaaM的实现
作者将所提出的CaaM实现在两种流行的基于注意力的深度模型上:基于CBAM的CNN、和
Transformer-based T2T-ViT。将结果模型分别称为CNN-CaaM和vt - caam。为了简单起见,在本节中,使用\(\mathbf{c}\)和\(\mathbf{s}\)来表示因果和混杂特征(即,\(\mathbf{c} = \mathcal{A}(x)\)和\(\mathbf{s} = \overline{\mathcal{A}}(x)\))。
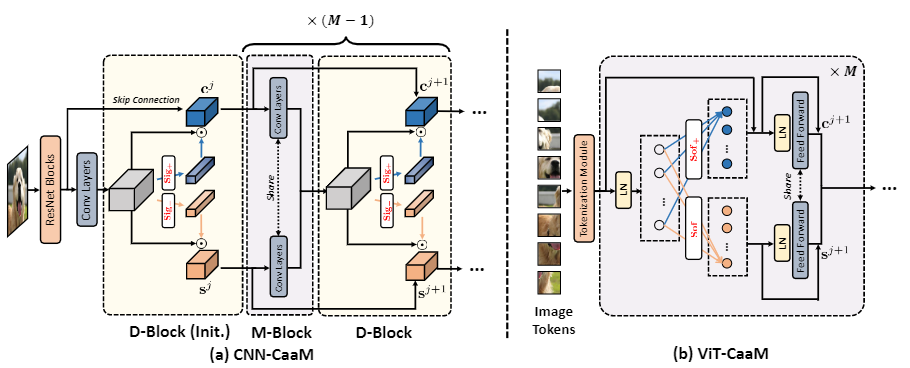
图5 基于CBAM的CNN-CaaM和基于T2T-ViT的ViT-CaaM模型结构。对于CNN-CaaM, D-Block被用来从CNN特征\(\mathbf{x}\)中分离因果特征\(\mathbf{c}\)(蓝色)和混杂特征\(\mathbf{s}\)(橙色)。
D-Block (Init.)表示第一个D-Block。而M-Block将\(\mathbf{c}\)和\(\mathbf{s}\)与卷积层合并。然后将M-Block和D-Block叠加,逐步细化\(\mathbf{c}\)和\(\mathbf{s}\)。
CNN-CaaM
对于输入特征\(x\),注意力计算:
其中\(\mathrm{z} \in \mathbb{R}^{w \times h \times c}\),\(\odot\)指的是元素点乘,因此,CaaM注意力表达如下:
模型结构如图5(a)所示。
D-Block
D-Block是包含CaaM计算的块,可以生成两个注意力特征\(\mathbf{c}\)和\(\mathbf{s}\)。在D-Block之前,可以有很多个标准的残差模块,\(D-Block^{j+1}\)可以表示为:
- skip connection 是由标准ResNet块的输出连接的。
- 在混淆特征\(\mathbf{s}^j\)上移除skip connection,将其与因果特征\(\mathbf{c}^j\)区分开来。
M-Block
在进入D-Block之前,\(\mathbf{c}\)和\(\mathbf{s}\)被输入进M-Block进行特征融合:
迭代10式和11式生成多层CaaM,在推理阶段,最后的因果特征\(\mathbf{c}^{j+M-1}\)作为预测的鲁棒特征。
ViT-CaaM
这个模型请参考原文。