论文及代码
论文地址:https://arxiv.org/abs/1904.04402
代码:http://www.svcl.ucsd.edu/projects/universal-detection/
概述
文章提出了一个通用的目标检测系统,适用于不同的图像领域而不需要该领域的先验知识。通过引入一个新的适应层系列(基于SE和新的领域-关注机制)。在所提出的通用检测器中,所有参数和计算都在领域之间共享,并且单个网络始终处理所有领域。作者在新的数据集上做实验(11个不同的目标检测数据集组成),检测效果比一组单领域检测器、一个多领域检测器和通用检测器的baseline都好。
介绍
目标检测任务是多种多样的,有种类差异(人脸、马、医学损伤等等),也有相机视角差异(从飞机、自动驾驶汽车上拍摄的图像等),还有图像风格(比如漫画、剪贴画、水彩画、医学图像等)等。现有的检测器大多是针对某一明确领域的(在单一数据集上进行训练和测试),部分原因是目标检测数据集是多样的且它们之间存在非平凡的领域转换。
众所周知,为不同领域的任务各自设置专门的检测器能达到很好的检测效果。但是实际应用中,系统可能需要处理多个领域的图像。简单粗暴一点的方法,我们要处理D个领域的图像,那么就训练D个检测器分别处理每个领域。但是,系统不一定明确某个时间点出现的是哪个领域的图像,而且模型会很大。所以研究人员提出了两种方案(图像分类),一种是在一个通用模型上解决多任务,另一种是在多个领域解决同一任务。目标检测比分类任务复杂得多。
文中建立了一个新的通用目标检测benckmark(包括11个不同的目标检测数据集),如图1所示:

并提出了一系列系统结构用于通用/多领域的目标检测问题(如图2):
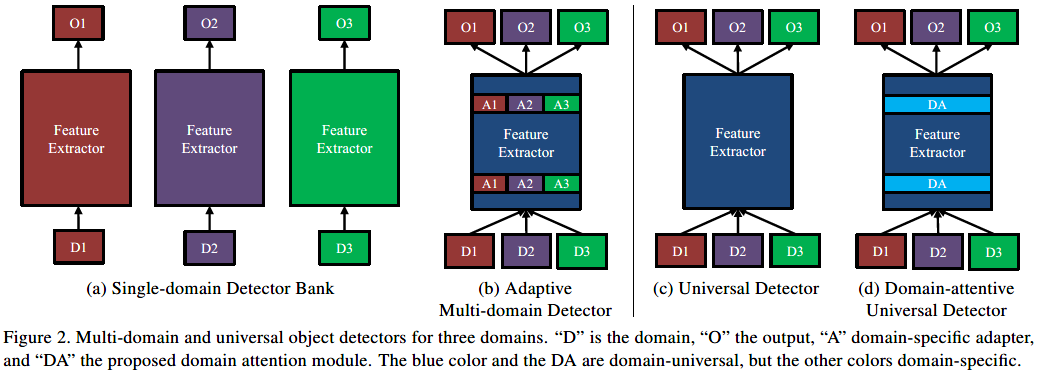
其中D表示不同的领域,O表示输出,A表示领域专用的adapter,DA表示文中提出的领域注意模块,蓝色部分是领域通用,其他颜色表示各领域专用。图2的(a)和(b)是多领域检测器,显然它们都需要领域的先验知识。(a)是一系列领域专用检测器,不共享参数和计算;在(a)的基础上进行卷积层共享以及实现轻量级的领域专用的适应层,即(b)。图2的(c)和(d)是通用检测器,(c)所有领域间参数和计算(除了输出层),很难覆盖所有非平凡转换的领域,所以检测效果比(b)差;(d)是文中提出的方法,加入了DA(domain attention)模块,首先加入一系列通用SE adapter,然后引入基于特征的关注机制以实现对领域的敏感。该模块通过通用SE适配器库学习将网络激活分配给不同的域,并通过领域-注意机制来确定它们的响应,所以adapter可以专注于各自的领域。由于该过程是数据驱动的,所以域的数量不必与数据集的数量相匹配,数据集可以跨越多个域。网络可以利用跨领域的共享知识。
Multi-domain Object Detection
通用目标检测benchmark(UODB):Pascal VOC,WiderFace,KITTI,LISA,DOTA、COCO、Watercolor、Clipart、Comic、Kitchen和DeepLesions。
Single-domain Detector Bank
将Faster R-CNN作为Baseline,在每个数据集上分别训练检测器,得到11个检测器。各个检测器对应的卷积激活的均值和方差如下图:
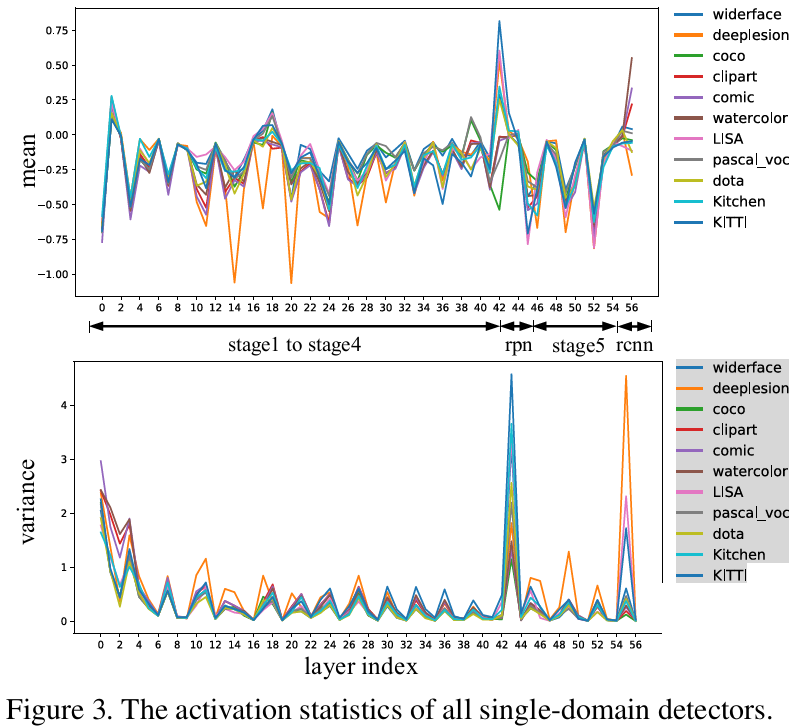
VOC和COCO的激活分布是相似的,而DOTA、DeepLesion和CrossDomain的分布相对差别较大。此外,不同层的统计结果不同。前面的层对校正领域偏移贡献更大,所以比后面的层差异性更明显,RPN层差异也很明显(虽然它们是类别无关的)。而且很多层在不同的数据集上有相似的统计数据,特别是中间层,这表明至少在一些领域它们是可以数据共享的。
Adaptive Multi-domain Detector

该模型中输出层和RPN层是领域专用的,网络区域部分是共享的(如所有的卷积层)。为了适应新的领域,文中提出了一些额外的领域专用层(补偿领域转移、轻量化)。
使用SE模块构建所有的领域适应检测器,原因如下:领域适应与基于特征的注意力机制相关,而SE模块根据各channel的依赖关系来调节channel的响应,这可以看做是一种基于特征的注意力机制;而且基于SE模块的SENet在ImageNet上具有很好的分类效果,而且是一个轻量化模型。
SE Adapters
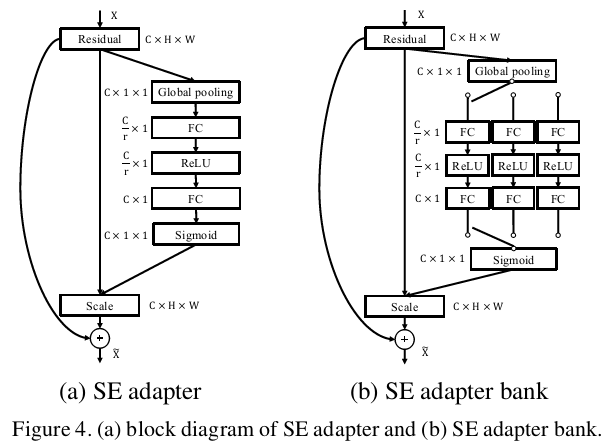
SE adapter包括如下操作:首先使用一个全局池化层进行Squeeze,然后通过两个全连接层组成的bottleneck结构来建模通道之间的相关性(先将特征维度降低到输入的1/r,然后经过ReLU激活后再通过一个全连接层升回原来的维度),这样可以具有更多的非线性、极大减少参数量和计算量。

文中r取16。FSE是指FC+ReLU+FC 。
将其用于多领域的目标检测(称为SE adapter bank),如图4b所示,给每个领域添加一个SE adapter分支和一个领域开关,可以选择领域关联的SE adapter。实现了图2b的结构,模型大小是图2a的1/5.
Universal Object Detection
在上述方法中,需要有领域的先验信息,而在自动系统中这是不可取的,比如自动驾驶或机器人系统。作者设计了通用检测器来解决这一问题。
Universal Detector
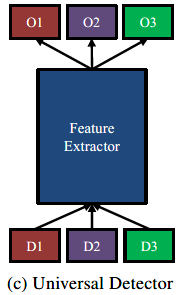
最简单的实现如上图所示,也就是所有task共享同一检测器,而输出层是task-specific的。这种方法简单粗暴,没有特定领域的参数,在所有领域上强制使用相同的参数/表示,检测效果较差。
Domain-attentive Universal Detector
理想情况下,通用检测器应该具有一定的领域敏感性,并且能够适应不同的领域。与多领域检测的区别在于:第一,必须自动推断领域;第二,不需要绑定领域和任务。
而一个常用的领域往往会有很多子领域,以交通场景为例,包含天气条件(晴天、雨天等)、环境(城市、乡村)等子领域。实际上,领域可能没有明确的语义,即它们可以是数据驱动的。在这种情况下,不需要要求每个检测器在单个域中工作,而软域分配更有意义。文章提出DA(domain adaptation)模块来突破网络单独处理单一领域的局限性。如下图所示。
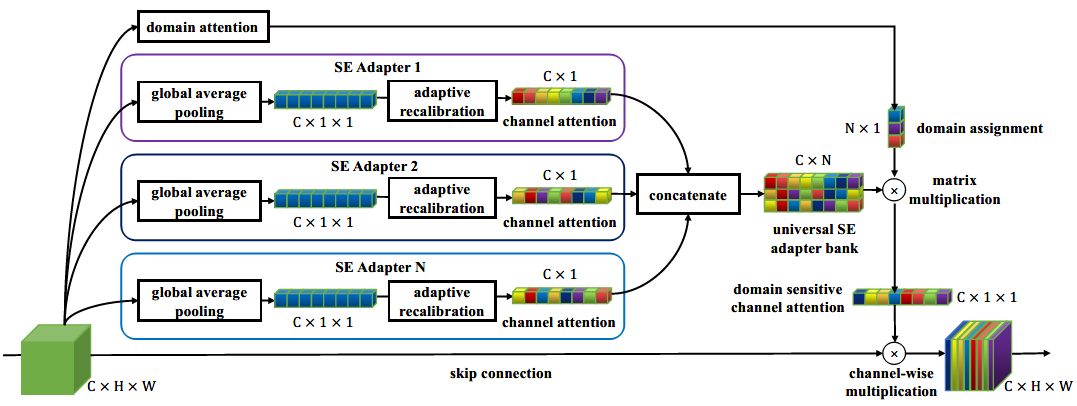
Universal SE Adapter Bank
没有领域switch,通过连接各个域适配器的输出来实现的,以形成一个通用的表示空间。
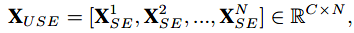
其中N是adapter的数目。
每个分支(非线性)沿着与特定域的统计信息相匹配的子空间映射输入。然后,注意力组件产生一组域敏感的权重,用于以数据驱动的方式组合这些映射。在这种情况下,不需要事先知道操作域,因为输入映像可以激发多个SE适配器分支。
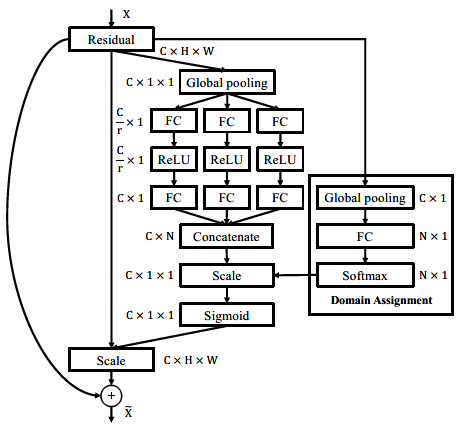
Domain Attention生成一个领域敏感的权重集,用于组合SE bank映射。DA组件首先对输入特征进行全局池化,然后应用Softmax层(线性层加Softmax函数),即
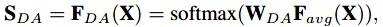
然后将得到的向量SDA给USE的输出XUSE加权,得到领域适应的响应向量:
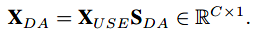
最后逐通道进行激活的rescale,即:
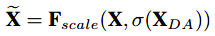
其中Fscale是逐通道乘法。
Experiments
实验backbone:Faster R-CNN + SE-ResNet-50(pretrained on ImageNet)
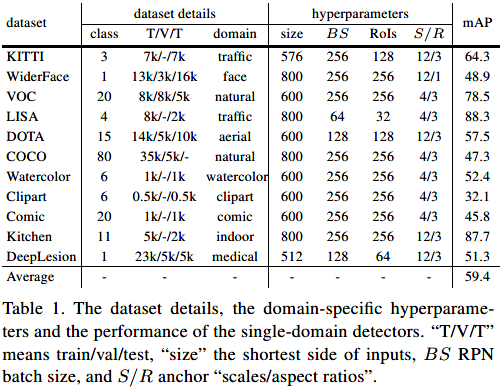
数据集、超参数设置以及单领域检测器的mAP:
mAP比较如下:

只使用了五个数据集。
多领域目标检测器(adaptive)的平均精度相比baseline提升了0.7%,且明显优于BN Adapter和residual adapter(RA)。通用目标检测器只增加了0.5M参数,但平均精度较差(只有72.5%)。领域注意机制的通用检测器效果最好,每个领域参数增加了大约7%,平均精度相对baseline提升了1.6%。如果领域注意机制的参数固定(也就是直接取SE adapter 响应的平均),平均精度则会下降0.5%(相对baseline提升1.1%)。
SE adapter数目的影响
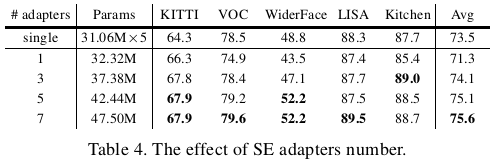
5个adapter左右是最合适的。
实验结果:

domain attention module学到了什么?下图显示了第四和第五个残差块第一阶段残差和最后一阶段残差学到的权重。

official evaluation
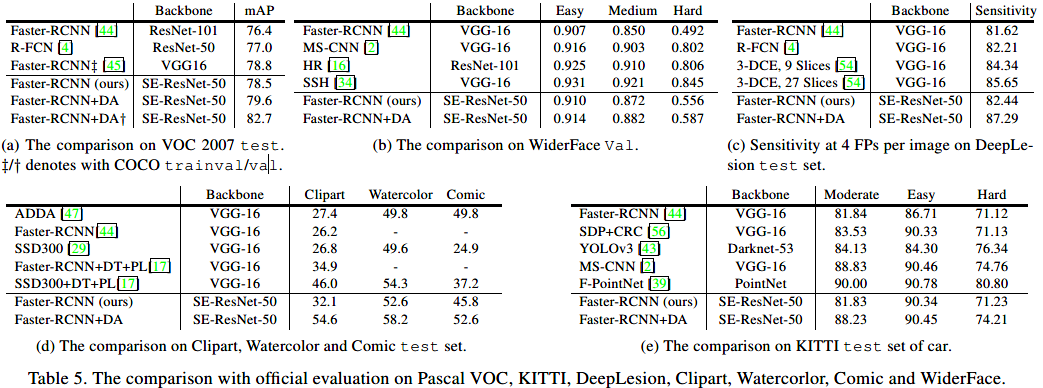
上表显示了universal+DA模型在各个官方测试集上的结果,增加了领域自适应后,在多个数据集上的mAP都有不同程度的提升。