简单一点说,装箱就是自动将基本数据类型转换为包装器类型;拆箱就是自动将包装器类型转换为基本数据类型。
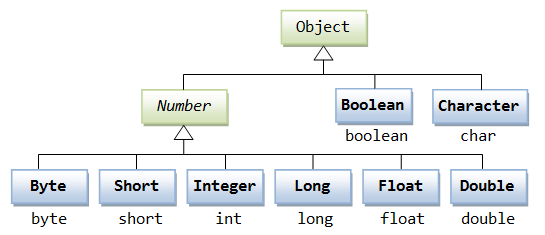
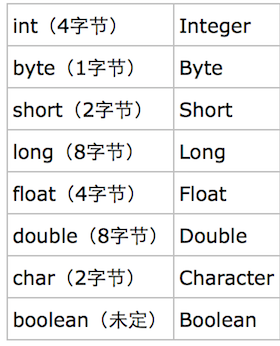
下面我们来看看需要装箱拆箱的类型有哪些:
这个过程是自动执行的,那么我们需要看看它的执行过程:
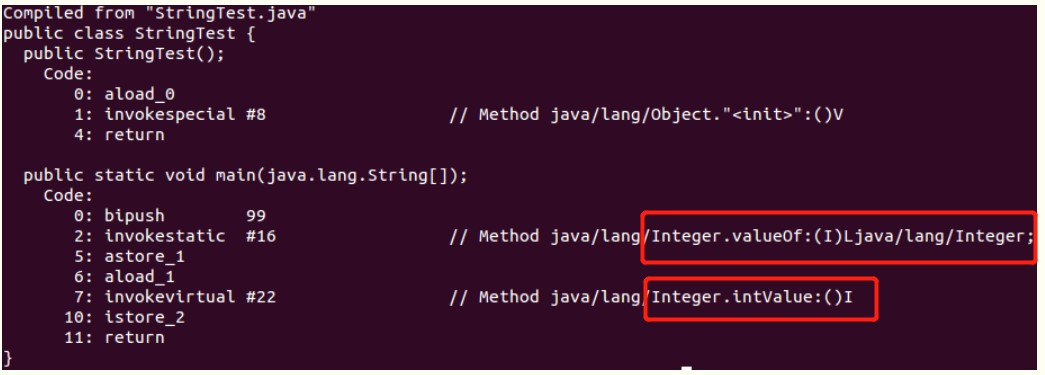
看看Integer.valueOf函数的源码
public static Integer valueOf(int i) {
if (i >= IntegerCache.low && i <= IntegerCache.high)
return IntegerCache.cache[i + (-IntegerCache.low)];
return new Integer(i);
}
IntegerCache是-128到128,也就是说
它会首先判断i的大小:如果i小于-128或者大于等于128,就创建一个Integer对象,否则执行SMALL_VALUES[i + 128]。
Interger的构造函数很简单就是一个this.value = value;它里面定义了一个value变量,创建一个Integer对象,就会给这个变量初始化。第二个传入的是一个String变量,它会先把它转换成一个int值,然后进行初始化。
下面看看SMALL_VALUES[i + 128]是什么东西:
所以我们这里可以总结一点:装箱的过程会创建对应的对象,这个会消耗内存,所以装箱的过程会增加内存的消耗,影响性能。
接着看看intValue函数
public int intValue() { return value; }
二、相关问题
上面我们看到在Integer的构造函数中,它分两种情况:
1、i >= 128 || i < -128 =====> new Integer(i)
2、i < 128 && i >= -128 =====> SMALL_VALUES[i + 128]
两种情况 1.大于绝对值128 2.小于绝对值128.这边为什么是128呢,128 = 1000000,这是指向常量池中的缓存地址,至于为什么缓存是128呢?这是因为在文档中说128是经常请求的值,这就很奥妙无穷了。这边固定了缓存的下限,但是上限可以通过设置jdk的AutoBoxCacheMax参数调整,自动缓存区间设置为[-128,N];
对于Integer,在(-128,128]之间只有固定的256个值,所以为了避免多次创建对象,我们事先就创建好一个大小为256的Integer数组SMALL_VALUES,所以如果值在这个范围内,就可以直接返回我们事先创建好的对象就可以了。
但是对于Double类型来说,我们就不能这样做,因为它在这个范围内个数是无限的。
总结一句就是:在某个范围内的整型数值的个数是有限的,而浮点数却不是。
所以在Double里面的做法很直接,就是直接创建一个对象,所以每次创建的对象都不一样。
我们进行一个归类:
Integer派别:Integer、Short、Byte、Character、Long这几个类的valueOf方法的实现是类似的。
Double派别:Double、Float的valueOf方法的实现是类似的。每次都返回不同的对象。
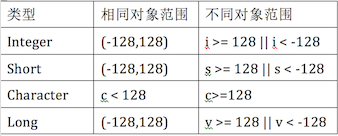
下面对Integer派别进行一个总结,如下图:
总结:
1、需要知道什么时候会引发装箱和拆箱
2、装箱操作会创建对象,频繁的装箱操作会消耗许多内存,影响性能,所以可以避免装箱的时候应该尽量避免。
3、equals(Object o) 因为原equals方法中的参数类型是封装类型,所传入的参数类型(a)是原始数据类型,所以会自动对其装箱,反之,会对其进行拆箱
4、当两种不同类型用==比较时,包装器类的需要拆箱, 当同种类型用==比较时,会自动拆箱或者装箱
泛型的擦除
Java的泛型是伪泛型,这是因为Java在编译期间,所有的泛型信息都会被擦掉,正确理解泛型概念的首要前提是理解类型擦除。Java的泛型基本上都是在编译器这个层次上实现的,在生成的字节码中是不包含泛型中的类型信息的,使用泛型的时候加上类型参数,在编译器编译的时候会去掉,这个过程成为类型擦除。
如在代码中定义List<Object>和List<String>等类型,在编译后都会变成List,JVM看到的只是List,而由泛型附加的类型信息对JVM是看不到的。Java编译器会在编译时尽可能的发现可能出错的地方,但是仍然无法在运行时刻出现的类型转换异常的情况,类型擦除也是Java的泛型与C++模板机制实现方式之间的重要区别。
public class Test { public static void main(String[] args) { ArrayList<String> list1 = new ArrayList<String>(); list1.add("abc"); ArrayList<Integer> list2 = new ArrayList<Integer>(); list2.add(123); System.out.println(list1.getClass() == list2.getClass()); } }
这两个类是相同的...
擦去之后他会变成这样
class Pair<T> { private T value; public T getValue() { return value; } public void setValue(T value) { this.value = value; } } class Pair { private Object value; public Object getValue() { return value; } public void setValue(Object value) { this.value = value; } }
因为在Pair<T>中,T 是一个无限定的类型变量,所以用Object替换,其结果就是一个普通的类,如同泛型加入Java语言之前的已经实现的样子。在程序中可以包含不同类型的Pair,如Pair<String>或Pair<Integer>,但是擦除类型后他们的就成为原始的Pair类型了,原始类型都是Object。
从上面的例2中,我们也可以明白ArrayList<Integer>被擦除类型后,原始类型也变为Object,所以通过反射我们就可以存储字符串了。
如果类型变量有限定,那么原始类型就用第一个边界的类型变量类替换。
public class Pair<T extends Comparable> {}
要区分原始类型和泛型变量的类型。
在调用泛型方法时,可以指定泛型,也可以不指定泛型。
- 在不指定泛型的情况下,泛型变量的类型为该方法中的几种类型的同一父类的最小级,直到Object
- 在指定泛型的情况下,该方法的几种类型必须是该泛型的实例的类型或者其子类
public class Test {
public static void main(String[] args) {
/**不指定泛型的时候*/
int i = Test.add(1, 2); //这两个参数都是Integer,所以T为Integer类型
Number f = Test.add(1, 1.2); //这两个参数一个是Integer,以风格是Float,所以取同一父类的最小级,为Number
Object o = Test.add(1, "asd"); //这两个参数一个是Integer,以风格是Float,所以取同一父类的最小级,为Object
/**指定泛型的时候*/
int a = Test.<Integer>add(1, 2); //指定了Integer,所以只能为Integer类型或者其子类
int b = Test.<Integer>add(1, 2.2); //编译错误,指定了Integer,不能为Float
Number c = Test.<Number>add(1, 2.2); //指定为Number,所以可以为Integer和Float
}
//这是一个简单的泛型方法
public static <T> T add(T x,T y){
return y;
}
}
类型擦除引起的问题及解决方法
因为种种原因,Java不能实现真正的泛型,只能使用类型擦除来实现伪泛型,这样虽然不会有类型膨胀问题,但是也引起来许多新问题,所以,SUN对这些问题做出了种种限制,避免我们发生各种错误。
Q: 既然说类型变量会在编译的时候擦除掉,那为什么我们往 ArrayList 创建的对象中添加整数会报错呢?不是说泛型变量String会在编译的时候变为Object类型吗?为什么不能存别的类型呢?既然类型擦除了,如何保证我们只能使用泛型变量限定的类型呢?
A: Java编译器是通过先检查代码中泛型的类型,然后在进行类型擦除,再进行编译。
public static void main(String[] args) { ArrayList<String> list = new ArrayList<String>(); list.add("123"); list.add(123);//编译错误 }
在上面的程序中,使用add方法添加一个整型,在IDE中,直接会报错,说明这就是在编译之前的检查,因为如果是在编译之后检查,类型擦除后,原始类型为Object,是应该允许任意引用类型添加的。可实际上却不是这样的,这恰恰说明了关于泛型变量的使用,是会在编译之前检查的。
那么,这个类型检查是针对谁的呢?我们先看看参数化类型和原始类型的兼容。
多态和重写之间冲突
可是由于种种原因,虚拟机并不能将泛型类型变为Date,只能将类型擦除掉,变为原始类型Object。这样,我们的本意是进行重写,实现多态。可是类型擦除后,只能变为了重载。这样,类型擦除就和多态有了冲突。JVM知道你的本意吗?知道!!!可是它能直接实现吗,不能!!!如果真的不能的话,那我们怎么去重写我们想要的Date类型参数的方法啊。
于是JVM采用了一个特殊的方法,来完成这项功能,那就是桥方法。
首先,我们用javap -c className的方式反编译下DateInter子类的字节码,结果如下:
class com.tao.test.DateInter extends com.tao.test.Pair<java.util.Date> { com.tao.test.DateInter(); Code: 0: aload_0 1: invokespecial #8 // Method com/tao/test/Pair."<init>":()V 4: return public void setValue(java.util.Date); //我们重写的setValue方法 Code: 0: aload_0 1: aload_1 2: invokespecial #16 // Method com/tao/test/Pair.setValue:(Ljava/lang/Object;)V 5: return public java.util.Date getValue(); //我们重写的getValue方法 Code: 0: aload_0 1: invokespecial #23 // Method com/tao/test/Pair.getValue:()Ljava/lang/Object; 4: checkcast #26 // class java/util/Date 7: areturn public java.lang.Object getValue(); //编译时由编译器生成的巧方法 Code: 0: aload_0 1: invokevirtual #28 // Method getValue:()Ljava/util/Date 去调用我们重写的getValue方法; 4: areturn public void setValue(java.lang.Object); //编译时由编译器生成的巧方法 Code: 0: aload_0 1: aload_1 2: checkcast #26 // class java/util/Date 5: invokevirtual #30 // Method setValue:(Ljava/util/Date; 去调用我们重写的setValue方法)V 8: return }
从编译的结果来看,我们本意重写setValue和getValue方法的子类,竟然有4个方法,其实不用惊奇,最后的两个方法,就是编译器自己生成的桥方法。可以看到桥方法的参数类型都是Object,也就是说,子类中真正覆盖父类两个方法的就是这两个我们看不到的桥方法。而打在我们自己定义的setvalue和getValue方法上面的@Oveerride只不过是假象。而桥方法的内部实现,就只是去调用我们自己重写的那两个方法。
所以,虚拟机巧妙的使用了桥方法,来解决了类型擦除和多态的冲突
简单一点说,装箱就是自动将基本数据类型转换为包装器类型;拆箱就是自动将包装器类型转换为基本数据类型。
下面我们来看看需要装箱拆箱的类型有哪些:
这个过程是自动执行的,那么我们需要看看它的执行过程:
它会首先判断i的大小:如果i小于-128或者大于等于128,就创建一个Integer对象,否则执行SMALL_VALUES[i + 128]。
Interger的构造函数很简单就是一个this.value = value;它里面定义了一个value变量,创建一个Integer对象,就会给这个变量初始化。第二个传入的是一个String变量,它会先把它转换成一个int值,然后进行初始化。
下面看看SMALL_VALUES[i + 128]是什么东西:
所以我们这里可以总结一点:装箱的过程会创建对应的对象,这个会消耗内存,所以装箱的过程会增加public int intValue return 这个很简单,直接返回value值即可。
二、相关问题
上面我们看到在Integer的构造函数中,它分两种情况:
1、i >= 128 || i < -128 =====> new Integer(i)
2、i < 128 && i >= -128 =====> SMALL_VALUES[i + 128]
两种情况 1.大于绝对值128 2.小于绝对值128.这边为什么是128呢,128 = 1000000,这是指向常量池中的缓存地址,至于为什么缓存是128呢?这是因为在文档中说128是经常请求的值,这就很奥妙无穷了。这边固定了缓存的下限,但是上限可以通过设置jdk的AutoBoxCacheMax参数调整,自动缓存区间设置为[-128,N];
对于Integer,在(-128,128]之间只有固定的256个值,所以为了避免多次创建对象,我们事先就创建好一个大小为256的Integer数组SMALL_VALUES,所以如果值在这个范围内,就可以直接返回我们事先创建好的对象就可以了。
但是对于Double类型来说,我们就不能这样做,因为它在这个范围内个数是无限的。
总结一句就是:在某个范围内的整型数值的个数是有限的,而浮点数却不是。
所以在Double里面的做法很直接,就是直接创建一个对象,所以每次创建的对象都不一样。
我们进行一个归类:
Integer派别:Integer、Short、Byte、Character、Long这几个类的valueOf方法的实现是类似的。
Double派别:Double、Float的valueOf方法的实现是类似的。每次都返回不同的对象。
下面对Integer派别进行一个总结,如下图:
总结:
1、需要知道什么时候会引发装箱和拆箱
2、装箱操作会创建对象,频繁的装箱操作会消耗许多内存,影响性能,所以可以避免装箱的时候应该尽量避免。
3、equals(Object o) 因为原equals方法中的参数类型是封装类型,所传入的参数类型(a)是原始数据类型,所以会自动对其装箱,反之,会对其进行拆箱
4、当两种不同类型用==比较时,包装器类的需要拆箱, 当同种类型用==比较时,会自动拆箱或者装箱
泛型的擦除
Java的泛型是伪泛型,这是因为Java在编译期间,所有的泛型信息都会被擦掉,正确理解泛型概念的首要前提是理解类型擦除。Java的泛型基本上都是在编译器这个层次上实现的,在生成的字节码中是不包含泛型中的类型信息的,使用泛型的时候加上类型参数,在编译器编译的时候会去掉,这个过程成为类型擦除。
如在代码中定义List<Object>和List<String>等类型,在编译后都会变成List,JVM看到的只是List,而由泛型附加的类型信息对JVM是看不到的。Java编译器会在编译时尽可能的发现可能出错的地方,但是仍然无法在运行时刻出现的类型转换异常的情况,类型擦除也是Java的泛型与C++模板机制实现方式之间的重要区别。