1.实验背景
本次实验是Kaggle上的一个入门比赛——Titanic: Machine Learning from Disaster。比赛选择了泰坦尼克号海难作为背景,并提供了样本数据及测试数据,要求我们根据样本数据内容建立一个预测模型,对于测试数据中每个人是否获救做个预测。样本数据包括891条乘客信息及获救情况,测试数据有418条乘客信息。样本数据的样例如下:

- Passenger:乘客唯一识别id
- Survived:是否存活,0为否,1为是
- Pclass:船舱等级,1、2、3等
- Name:姓名
- Sex:性别
- Age:年龄
- SibSp:和该乘客一起旅行的兄弟姐妹和配偶的数量
- Parch:和该乘客一起旅行的父母和孩子的数量
- Ticket:船票号
- Fare:船票价格
- Cabin:船舱号
- Embarked:登船港口 S=英国南安普顿Southampton(起航点) C=法国 瑟堡市Cherbourg(途经点) Q=爱尔兰 昆士Queenstown(途经点)
我们的目标就是根据上述字段信息以及乘客的获救情况,实现一个预测乘客是否存活的模型。下面我们来看一下用到的模型。
2.模型简介
通过分析案例,我们可以看出这是一个很明显的二分类问题,即判断乘客是否遇难,关于二分类的模型很多,这里用到了三种模型:线性回归模型、逻辑回归模型跟随机森林模型。本次实验也参考了 寒小阳的CSDN博客以及网页云课堂的免费公开课。下面就对这三个模型进行介绍。
线性回归模型
线性回归模型很简单,可以看成多项式方程的拟合问题。只有一个自变量,称为一元线性回归;有多于一个的变量,称为多元线性回归。对于一元线性回归,经常采用最小二乘的方法拟合出一条最逼近各点的曲线,如下图所示:

多元线性回归自变量不止一个,形式如式子:Y = a1X1+a2X2+a3X3+a4X4+a5X5+.....+anXn。一元线性回归是找一条拟合直线,而对于多元线性回归则是找到一个超平面,使这个超平面距离各点的距离最小。
其实无论是一元线性回归还是多元线性回归,它们的通式是Y = ω‘X+b。通过训练数据,找到最合适的w‘和b,也就实现了模型的求解。
这样,我们输入不同的自变量,就可以找到对应的因变量,达到预测的目的。
逻辑回归模型
线性回归存在一个最大的问题就是,它的自变量是连续变化的,是区间变量,而现实生活中很多变量不是连续的,例如属性变量或者序列变量。在这里,像我们样本数据中的年龄属性就是序列变量,因为年龄正常情况下不存在小数,不可能我们说一个人12.25岁;数据中的船舱等级、性别、登船港口等都是属性变量,这些变量的取值都是固定的。
所以对于现实生活中很多实例,线性回归模型不再很适用,这时候就要考虑逻辑回归模型。
其实逻辑回归可以看做广义的线性回归,只不过它通过函数L把 w‘X+b对应一个隐状态p,p = L(ω‘X+b),相当于对于结果Y又用一个函数L进行修饰得到L(Y)。如果没有函数L则是线性回归,如果函数L是多项式函数,就是多项式回归,而如果L是logistic函数,就是logistic回归。
logistic回归的因变量可以是二分类的,也可以是多分类的,但是二分类的更为常用,也更加容易解释,多类可以使用softmax方法进行处理。实际中最为常用的就是二分类的logistic回归。
我们通常用0和1来表示二分类的结果,而ω‘X+b得到的值可能不是0-1范围内,我们需要找到一个函数对于ω‘X+b结果进行处理,使其值在[0,1]里面。于是便找到Sigmoid Function作为我们的L函数,它的函数式如下:

Sigmoid Function的函数图像如下,它的绘制函数是:
1 import matplotlib.pyplot as plt 2 import numpy as np 3 4 def Sigmoid(x): 5 return 1.0 / (1.0 + np.exp(-x)) 6 7 x= np.arange(-10, 10, 0.1) 8 #Sigmoid函数 9 h = Sigmoid(x) 10 plt.plot(x, h) 11 #坐标轴上加一条竖直的线(0位置) 12 plt.axvline(0.0, color='k') 13 plt.axhspan(0.0, 1.0, facecolor='1.0', alpha=1.0, ls='dotted') 14 plt.axhline(y=0.5, ls='dotted', color='k') 15 #y轴标度 16 plt.yticks([0.0, 0.5, 1.0]) 17 #y轴范围 18 plt.ylim(-0.1, 1.1) 19 plt.show()
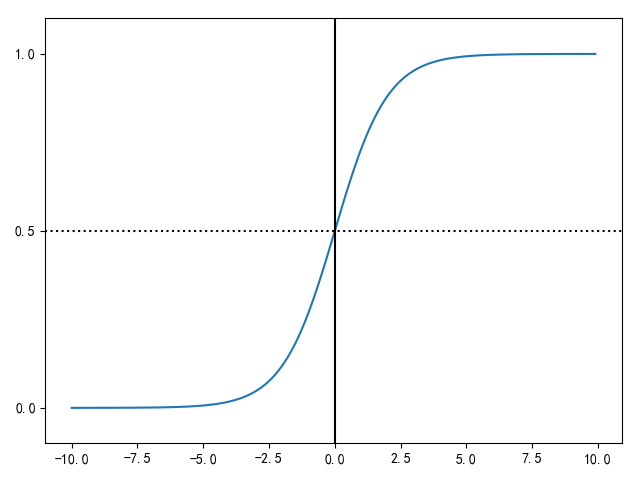
我们又把L函数叫做激活函数,激活函数不只Sigmoid Function一种,还有tanh函数、ReLU函数等等,函数的选择要根据适用场景来定。
我们通过Sigmoid Function把结果值变为[0,1]之间的数值,那么怎么才能求出最合适的ω'跟b呢?
对于单个样本,这里就是每一个乘员数据,我们定义了损失函数(Loss Functon)来评价预测的结果。它的形式是这样的:Ŀ(a,y),这里的a就是L(ω‘X+b),y则是预测的真值。Ŀ是一个衡量预测值与真值大小的函数,最常用的就是对数形式的函数,为:Ŀ(a,y) = -[yloga +(1-y)log(l-y)]。
而成本函数(Cost Function)则是所有样本函数的加权求平均。我们要想求出最合适的ω'跟b,就要是成本函数的值最小,首先对ω'跟b赋予初值,这时候我们对成本函数求导,利用反向传播,可以得到一次dω'跟db。
通过梯度下降法ω' = ω'+dω',b = b+db就得到更新后的ω'跟b。最后通过一步步的梯度下降,使得成本函数C的值最小,这时候我们就找到了最优的ω'跟b。如下图所示,通过不断调整ω'跟b,使得损失函数C到达最低点。

当然,我们的实现过程很简单,只需要几行代码就可以搞定。
随机森林模型
在谈随机森林模型前,需要理解决策树模型。最简单的一个决策树只有一个分支,例如考到60分以上是及格,60分以下是不及格。当影像因素很多事,会根据这些因素建立很多决策层,最终得到结果。如下图所示,就是一个决策树:

决策树模型很容易产生过拟合现象,模型泛化能力很弱。基于决策树模型,又出现了随机森林模型,通过选择选择任意数量的决策树,通过从样本数据数据中有放回的随机抽取一些样本去训练这些决策树,最终的结果是综合所有决策树的判断给出最合理的决策。
说了这么多模型,其实模型的实现过程很简单,因为python的sklearn库已经把上面这些函数通通封装好了,只需要调用即可。
3.数据预处理
在进行实验之前,这里先说明一下用到的库函数。pandas、sklearn、numpy以及绘图库函数matplotlib。
机器学习的绝大多数运算是矩阵运算,需要输入的数据是数值型。而我们这里很多数据是字符型,我们首先需要对于数据进行预处理。
首先读入我们的数据:
1 # 正则表达式模块 2 import re 3 4 # 由于年龄中有空值,需要先用平均值对年龄的缺失值进行填充,因为矩阵运算只能是数值型,不能是字符串 5 titanic['Age'] = titanic['Age'].fillna(titanic['Age'].mean()) 6 # 同理,由于Embarked(登船地点)里面也有空值,所以也需要用出现最多的类型对它进行一个填充 7 titanic['Embarked'] = titanic['Embarked'].fillna('S') 8 9 # 对于性别中的male与female,用0和1来表示。首先看性别是否只有两个值 10 # 对于登船地点的三个值S C Q,也用0 1 2分别表示 11 # print(titanic['Sex'].unique()) 12 # print(titanic['Embarked'].unique()) 13 titanic.loc[titanic['Sex'] == 'male', 'Sex'] = 0 14 titanic.loc[titanic['Sex'] == 'female', 'Sex'] = 1 15 16 titanic.loc[titanic['Embarked'] == 'S', 'Embarked'] = 0 17 titanic.loc[titanic['Embarked'] == 'C', 'Embarked'] = 1 18 titanic.loc[titanic['Embarked'] == 'Q', 'Embarked'] = 2 19 20 # 加上其余的属性特性 21 titanic["FamilySize"] = titanic["SibSp"] + titanic["Parch"] 22 23 # 姓名的长度 24 titanic["NameLenght"] = titanic["Name"].apply(lambda x: len(x)) 25 26 27 # 定义提取姓名中Mr以及Mrs等属性 28 def get_title(name): 29 title_search = re.search(' ([A-Za-z]+).', name) 30 if title_search: 31 return title_search.group(1) 32 return "" 33 34 35 titles = titanic["Name"].apply(get_title) 36 # 对于姓名中的一些称呼赋予不同的数值 37 title_mapping = {'Mr': 1, 'Miss': 2, 'Mrs': 3, 'Master': 4, 'Dr': 5, 'Rev': 6, 'Major': 7, 'Mlle': 8, 'Col': 9, 38 'Capt': 10, 'Ms': 11, 'Don': 12, 'Jonkheer': 13, 'Countess': '14', 'Lady': 15, 'Sir': 16, 'Mme': 17} 39 for k,v in title_mapping.items(): 40 titles[titles == k] = v 41 titanic['Titles'] = titles
这时候,我们需要画图看一下这些数据对于最后获救的结果影响到底有多大。
首先是乘客船舱等级获救情况统计:
1 # 导入图表函数 2 import matplotlib.pyplot as plt 3 from pylab import * 4 # 图表汉字正常显示 5 mpl.rcParams['font.sans-serif'] = ['SimHei'] 6 # 图表负值正常显示 7 matplotlib.rcParams['axes.unicode_minus'] = False 8 9 # 查看各等级乘客等级的获救情况 10 fig = plt.figure() 11 # 设置图表颜色的alpha参数 12 fig.set(alpha=0.2) 13 14 Suvived_0 = titanic.Pclass[titanic.Survived == 0].value_counts() 15 Suvived_1 = titanic.Pclass[titanic.Survived == 1].value_counts() 16 df = pandas.DataFrame({u"获救": Suvived_1, u"未获救": Suvived_0}) 17 df.plot(kind='bar', stacked=True) 18 plt.title(u'各乘客等级的获救情况') 19 plt.xlabel(u'乘客等级') 20 plt.ylabel(u'人数') 21 plt.show()

再看一下不同性别的获救情况:
1 # 按性别分组 2 fig = plt.figure() 3 fig.set(alpha=0.2) 4 5 Survived_m = titanic.Survived[titanic.Sex == 0].value_counts() 6 Survived_f = titanic.Survived[titanic.Sex == 1].value_counts() 7 df = pandas.DataFrame({u'男性': Survived_m, u'女性': Survived_f}) 8 df.plot(kind='bar', stacked=True) 9 plt.title(u'不同性别获救情况') 10 plt.xlabel(u'性别') 11 plt.ylabel(u'人数') 12 plt.show()

还有不同年龄的获救情况统计:
1 # 不同年龄获救情况 2 fig = plt.figure() 3 fig.set(alpha=0.2) 4 plt.scatter(titanic.Survived, titanic.Age) 5 plt.ylabel(u'年龄') 6 plt.grid(b=True, which='major', axis='y') 7 plt.title(u'不同年龄的获救情况(1为获救)') 8 plt.show()

不同港口登录乘客的获救情况:
1 # 不同港口登录乘客获救情况 2 fig = plt.figure() 3 fig.set(alpha=0.2) 4 Survived_0 = titanic.Embarked[titanic.Survived == 0].value_counts() 5 Survived_1 = titanic.Embarked[titanic.Survived == 1].value_counts() 6 df = pandas.DataFrame({u'获救': Survived_1, u'未获救': Survived_0}) 7 df.plot(kind='bar', stacked=True) 8 plt.xlabel(u'登录港口') 9 plt.ylabel(u'人数') 10 plt.title(u'不同港口登录乘客获救情况')

好吧,通过图表分析,我们得知其中的一些要素对于是否获救确实存在影像。此时我们已经获得了10个影响属性,分别是:Pclass", "Sex", "Age", "SibSp", "Parch", "Fare", "Embarked", "Titles", "FamilySize", "NameLenght"。
那么我们有必要对这10个字段分别计算一下重要度,也就是对于结果的影像。我们通过对于每个字段,随机添加一些噪音值,通过对于结果值的影像来判断相应的重要程度。例如一个属性添加了很多噪音值,但是对于结果预测的准确率没有太大影响,我们就认为这个属性重要程度相对较低,反之亦然,统计代码及结果如下图所示:
1 # 各特征属性的重要程度 2 from sklearn.feature_selection import SelectKBest, f_classif 3 4 5 selector = SelectKBest(f_classif, k=5) 6 selector.fit(titanic[presictors], titanic["Survived"]) 7 # 获取每个数据的重要值 8 scores = -np.log10(selector.pvalues_) 9 10 # 画图表示,看看哪一些属性对结果影响较大,即重要值高 11 plt.bar(range(len(presictors)), scores) 12 plt.xticks(range(len(presictors)), presictors, rotation='vertical') 13 14 plt.show()
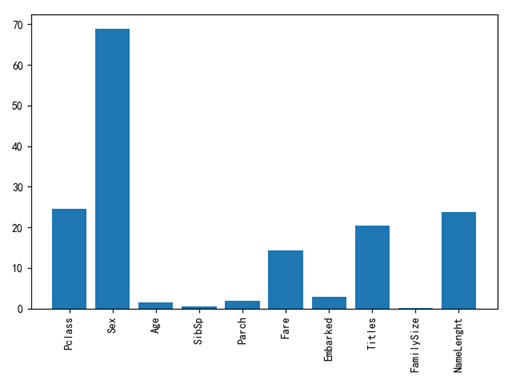
我们发现,船舱等级(Pclass)、性别(Sex)、船票价格(Fare)、名字称谓(Title)以及名字长短(NameLength)的重要性很大,其它的重要性则不是很高(数值越大重要性越大)。头等舱的确实有一定的优势,女性比男性更有优势(女人跟小孩优先)以及姓名长度跟称谓也有影响(姓名长度影响座位分配?),船票价格跟船舱等级是正相关,所以也很重要。
4.模型训练
好了,模型我们也已经初步了解,数据也已经经过预处理,那么我们就开始训练模型吧。
在此之前,先讨论一下交叉验证。由于我们的测试数据是没有存活数据的,也就是我们需要根据样本数据训练出来的模型给出测试数据对应的存活结果,再在Kaggle平台上提交结果。但是,我们又怎么知道我们训练模型的效果呢?有种方法叫做交叉验证,它的思想就是对于训练样本分成几份,例如三份,然后分别取出不同的两份作为训练样本,另一份作为测试样本,共取3次,最后取平均就得到了最终的最终的精度。最终的结果值就是预测出正确值数量/测试样本的数量。sklearn里面也提供了交叉验证的模型,所以很方便就可以测试我们的模型是否准确啦。
首先我们看一下线性回归模型的训练及测试结果:
1 # 导入线性回归模型跟逻辑回归模型 2 from sklearn.linear_model import LinearRegression, LogisticRegression 3 4 presictors = ["Pclass", "Sex", "Age", "SibSp", "Parch", "Fare", "Embarked", "Titles", "FamilySize", "NameLenght"] 5 alg = LinearRegression() 6 # 在训练集上进行三次交叉验证 7 # kf = KFold(titanic.shape[0], n_folds=3, random_state=1) 8 kf = KFold(n_splits=2) 9 predictions = [] 10 for train, test in kf.split(titanic): 11 # 从train中取出分割后的训练数据 12 train_predictors = titanic[presictors].iloc[train, :] 13 # 取出存活数量作为训练目标 14 train_target = titanic["Survived"].iloc[train] 15 # 使用训练样本跟训练目标训练回归函数 16 alg.fit(train_predictors, train_target) 17 # 我们现在可以在测试集上做预测 18 test_predictions = alg.predict(titanic[presictors].iloc[test, :]) 19 predictions.append(test_predictions) 20 21 # 检查回归的效果 22 predictions = np.concatenate(predictions, axis=0) 23 24 predictions[predictions > .5] = 1 25 predictions[predictions <= .5] = 0 26 accuracy = sum(predictions == titanic["Survived"])/len(predictions) 27 print(accuracy)
好啦,然后我们可以看我们模型的预测准确率是0.792368125701459。毕竟这是用线性回归做的,我们可以再试一下逻辑回归,看一下效果是否会更好。
1 alg = LogisticRegression(random_state=1) 2 scores = cross_val_score(alg, titanic[presictors], titanic["Survived"], cv=3) 3 print(scores.mean())
结果出来了,模型的预测准确度是0.8103254769921437,确实比线性回归的效果要好,那么我们再试一下随机森林的结果。
1 # 导入随机森林模型 2 from sklearn.ensemble import RandomForestClassifier 3 4 alg = RandomForestClassifier(random_state=1, n_estimators=100, min_samples_split=4, min_samples_leaf=2) 5 # presictors = ["Pclass", "Sex", "Age", "SibSp", "Parch", "Fare", "Embarked", "Titles", "FamilySize", "NameLenght"] 6 kf = KFold(n_splits=3) 7 scores = cross_val_score(alg, titanic[presictors], titanic["Survived"], cv=kf.split(titanic)) 8 print(scores.mean())
模型的预测准确度是0.8294051627384961,精度再一次提高。
到目前为止,我们已经尝试了线性回归、逻辑回归以及随机森林实现了泰坦尼克号生存预测。这时候,我们在会考虑,模型精度能不能进一步提高呢?模型融合可以是机器学习中提高精度的一大杀器。我们试着把逻辑回归跟随机森林这两种模型结合到一起,综合两种模型的预测得出更合理的结果,同时,因为随机森林的精度更高,所以我们对于随机森林赋予权重为3,逻辑回归模型的权重赋予1,下面我们看一下实现过程:
1 algorithms = [ 2 [RandomForestClassifier(random_state=1, n_estimators=100, min_samples_split=4, min_samples_leaf=2), ["Pclass", "Sex", 3 "Age", "SibSp", "Parch", "Fare", "Embarked", "Titles", "FamilySize", "NameLenght"]], 4 [LogisticRegression(random_state=1), ["Pclass", "Sex", "Age", "SibSp", "Parch", "Fare", "Embarked", "Titles", 5 "FamilySize", "NameLenght"]] 6 ] 7 # 交叉验证 8 kf = KFold(n_splits=3) 9 predictions = [] 10 for train, test in kf.split(titanic): 11 train_target = titanic["Survived"].iloc[train] 12 full_test_predictions = [] 13 # 对于每一个测试集都做出预测 14 for alg, predictors in algorithms: 15 alg.fit(titanic[predictors].iloc[train, :], train_target) 16 test_predictions = alg.predict_proba(titanic[predictors].iloc[test, :].astype(float))[:, 1] 17 full_test_predictions.append(test_predictions) 18 test_predictions = (full_test_predictions[0]*3 + full_test_predictions[1])/4 19 test_predictions[test_predictions <= .5] = 0 20 test_predictions[test_predictions > .5] = 1 21 predictions.append(test_predictions) 22 23 # 把所有的预测结果放到集合当中 24 predictions = np.concatenate(predictions, axis=0) 25 26 # 计算与训练数据真值比较的精度 27 accuracy = sum(predictions == titanic["Survived"])/len(predictions) 28 print(accuracy)
这时候我们得到最终的精度为0.8249158249158249,好吧对比单纯的随机森林精度并没有提高。
5.结束语
同时我们还可以对模型进行进一步的优化,例如上面有一些字段属性的重要程度很低,那么我们就可以综合取舍,这样不仅可以提高我们模型的精度,还可以提高我们模型的泛化能力。同时,我们还可以尝试其它的模型,以及多种模型的组合,以此来提高我们预测的精度。
当然,这次模型训练的数据非常少,因为泰塔尼克号全部的乘客约2200人,模型的训练可能需要更多数据的训练,在模型精度和泛化能力之间寻找一个合理平衡,也就是防止过拟合跟欠拟合的问题。
本次实验采用的python版本是3.6.0,实验用到的数据以及源代码在我的GitHub中(首页左上角点击即可进入),大家可以下载实验。
这次实验就讲到这里啦,欢迎大家提出宝贵的意见!