Chapter2 KNN
1.numpy.tile函数
格式:tile(A,reps)
* A:array_like
* 输入的array
* reps:array_like
* A沿各个维度重复的次数
举例:A=[1,2]
1. tile(A,2)
结果:[1,2,1,2]
2. tile(A,(2,3))
结果:[[1,2,1,2,1,2], [1,2,1,2,1,2]]
3. tile(A,(2,2,3))
结果:[[[1,2,1,2,1,2], [1,2,1,2,1,2]],
[[1,2,1,2,1,2], [1,2,1,2,1,2]]]
reps的数字从后往前分别对应A的第N个维度的重复次数。
2.numpy.shape函数
shape函数是numpy.core.fromnumeric中的函数,它的功能是读取矩阵的形状,比如shape[0]就是读取矩阵第一维度的长度。

3.numpy.sum函数(axis=)
python内建函数的sum应该是默认的axis=0 就是普通的相加,当加入axis=1以后就是将一个矩阵的每一行向量相加。
例如:
c = np.array([[0, 2, 1], [3, 5, 6], [0, 1, 1]])
print c.sum()
print c.sum(axis=0)
print c.sum(axis=1)
结果分别是:19, [3 8 8], [ 3 14 2]
#axis=0, 表示列。
#axis=1, 表示行。
4.字典的get方法
dict.get(key, "NO")
如果key在字典中不存在,返回第二个参数的值,例如这里返回"NO"
5.numpy.argsort函数
array.argsort()返回的是array数组中的值的从小到大的索引
例如x = [2,4,3,1]
![]()

注意这里numpy的数组要用它自己的array函数来定义,不能直接定义数组
6. sorted函数
a = {'math':98, 'english':100, 'PE':77}
b = sorted(a.iteritems(), key=operator.itemgetter(1), reverse=True)
iteritems是循环迭代字典a中的每一个key-value对,itemgetter(1)表示排序是根据value的值排序(0则是key),reverse=True代表降序
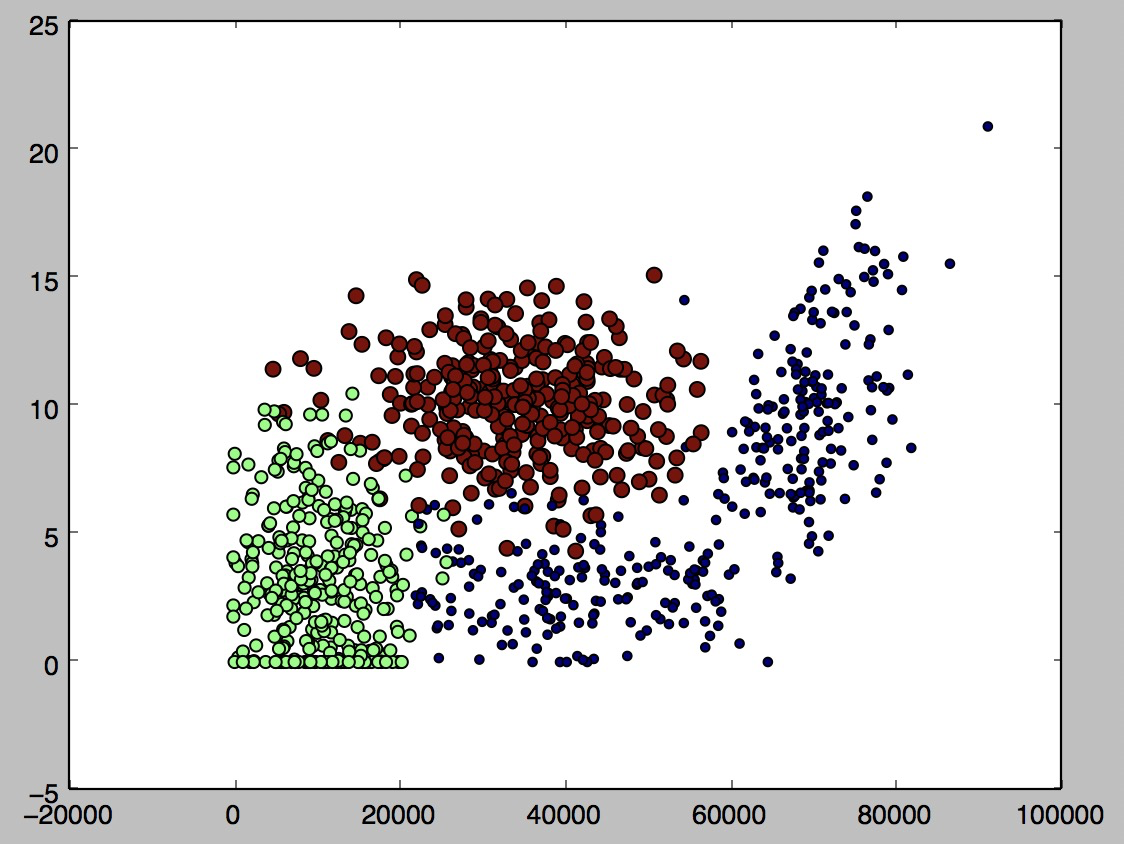
横轴:每年飞行里程数 纵轴:玩电子游戏时间
绿色:不具魅力 蓝色:魅力一般 红色:极具魅力
Helen女士的择偶标准挺不错0.0
7.numpy.min() numpy.max()
numpy里的min(0)、max(0) 参数0表示列中取得最小值,而不是选取当前行的最小值,这也是用来处理矩阵的
8.使用open(filename)函数时出现错误:
File "/Users/qcy/PycharmProjects/MachineLearning/KNN.py", line 109, in img2vector
fr = open(filename)
TypeError: function takes at least 2 arguments (1 given)
这是由于在from os import * 时,把os.open()函数引入了,从而覆盖了python的built-in的open()函数,这两个open()函数使用的方法是不一样的。所以只import需要使用的函数就行,改成from os import listdir
总结:KNN这个算法其实挺笨的,它并没有真正的使用训练集训练出一个模型,而是在测试时直接把测试的矩阵扩大到训练矩阵的规模,然后做一个距离的计算,取前K个,哪个类别的归类多就归到哪类。这种分类方式准确率还行,但是它运行的时间和占用的空间可能太过庞大了。 通过这一章也熟悉了使用numpy库对矩阵进行操作。“KNN另一个缺陷时它无法给出任何数据的基础结构信息,因此我们也无法知晓平均实例样本和典型实例样本具有什么特征。” (???)