爬虫爬拉钩网出现 您操作太频繁,请稍后再访问 解决
一、总结
一句话总结:
爬拉勾网数据的时候,ajax的post请求是需要cookie的,还需要在header里面需要添加Accept、Referer、User-Agent
二、爬虫爬拉钩网出现 您操作太频繁,请稍后再访问 解决
转自或参考:{"status":false,"msg":"您操作太频繁,请稍后再访问","clientIp":"113.94.81.141"}
https://www.freesion.com/article/140098505/
在爬取拉勾网的时候报错{"STATUS":FALSE,"MSG":"您操作太频繁,请稍后再访问","CLIENTIP":"113.94.81.141"}
需要获取搜索结果那一页的cookie 以及header里面需要添加Accept、Referer、User-Agent

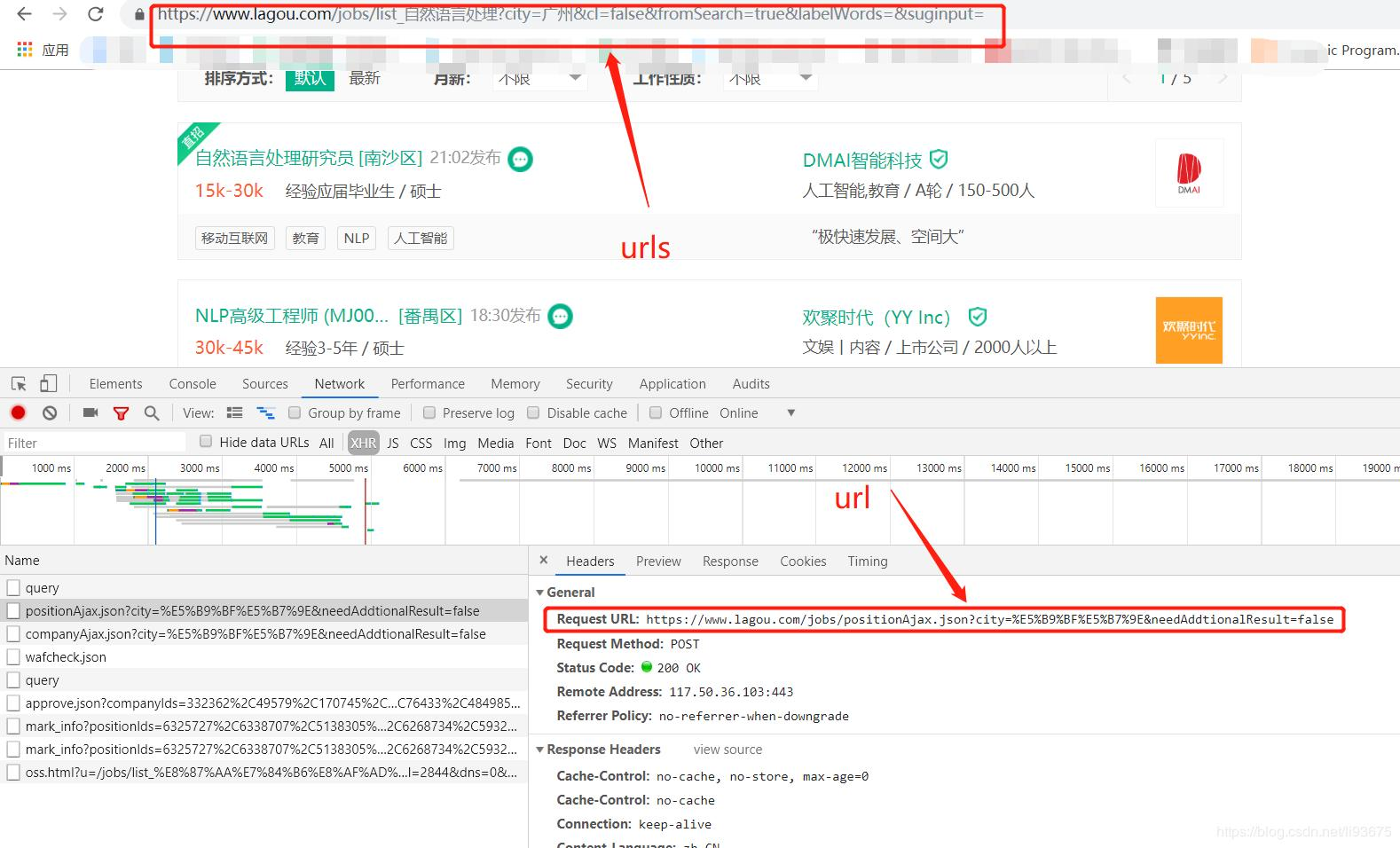
1 import requests 2 3 url = 'https://www.lagou.com/jobs/positionAjax.json?city=%E5%B9%BF%E5%B7%9E&needAddtionalResult=false' 4 5 payload={ 6 'first': 'true', 7 'pn': '1', 8 'kd': '自然语言处理' 9 } 10 11 header = { 12 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36', 13 'Referer': 'https://www.lagou.com/jobs/list_%E8%87%AA%E7%84%B6%E8%AF%AD%E8%A8%80%E5%A4%84%E7%90%86?px=default&city=%E5%B9%BF%E5%B7%9E', 14 'Accept': 'application/json, text/javascript, */*; q=0.01' 15 } 16 17 urls ='https://www.lagou.com/jobs/list_%E8%87%AA%E7%84%B6%E8%AF%AD%E8%A8%80%E5%A4%84%E7%90%86?city=%E5%B9%BF%E5%B7%9E&cl=false&fromSearch=true&labelWords=&suginput=' 18 s = requests.Session() 19 # 获取搜索页的cookies 20 s.get(urls, headers=headers, timeout=3) 21 # 为此次获取的cookies 22 cookie = s.cookies 23 # 获取此次文本 24 response = s.post(url, data=payload, headers=header, cookies=cookie, timeout=5).text 25 print(response)