Abstract
目标检测被认为是计算机视觉领域最具挑战性的问题之一,因为它涉及场景中物体分类和物体定位的组合。最近,与其他方法相比,深度神经网络(DNN)已经被证明可以实现出色的物体检测性能,其中,就速度和准确性而言,YOLOv2(一种改进的Only Only Look Once模型)是基于DNN的物体检测中最先进的技术之一。尽管YOLOv2可以在强大的GPU上实现实时性能,但利用这种方法在嵌入式计算设备上的视频中进行实时对象检测具有有限的计算能力和有限的内存,仍然非常具有挑战性。
在本文中,我们提出了一个名为Fast YOLO的新框架,它是一种快速的You Only Look Once框架,可加速YOLOv2以便能够以实时方式在嵌入式设备上的视频中执行对象检测。首先,我们利用进化深度智能框架来进进化YOLOv2网络架构并生成优化的架构(在此称为O-YOLOv2),参数少2.8倍,而IOU下降约2%。为了在保持性能的同时进一步降低嵌入式设备的功耗,在所提出的快速YOLO框架中引入运动自适应推理方法,以减少基于时间运动特性的O-YOLOv2的深度推理频率。实验结果表明,与原始YOLOv2相比,所提出的快速YOLO框架可以将深度推断的数量平均减少38.13%,对于视频中的目标检测平均加速~3.3X,从而使Fast YOLO在Nvidia Jetson TX1嵌入式系统上运行达到~18FPS。
1 Introduction
目标检测是计算机视觉领域最具挑战性的问题之一。对象检测的目标是定位场景中的不同对象,并将标签分配给对象的边界框。 解决这个问题的最常用的方法是重复使用现有的训练过的分类器来将标签分配给场景中的边界框。 例如,标准滑动窗口方法可用于分类器确定场景中存在的所有可能窗口的对象及其相应标签。 然而,这种方法不仅计算复杂度高,而且检测错误率也高。
最近,深度神经网络(DNNs)在各种不同的应用中表现出优越的性能,目标检测是DNNs已经显着超越现有方法的关键领域之一。 具体而言,已经证明了许多基于卷积神经网络(CNN)的方法达到了最先进的目标检测性能。 例如,在Region-CNN(R-CNN)[5]方法中,CNN体系结构用于在图像中生成bounding boxes proposals,而不是滑动窗口方法,因此分类器仅对边界框提议进行分类。 虽然R-CNN能够产生最新的精确度,但整个过程缓慢且难以优化,因为每个组件都必须单独进行培训。
最近,YOLO目标检测方法被提出,它通过将对象检测问题作为一个单一的回归问题,缓解与R-CNN相关的计算复杂性问题,其中边界框坐标和类概率是同时计算的。 尽管YOLO被证明比R-CNN具有显着的速度优势(例如,Nvidia Titan-X GPU上的每秒45帧),但也表明YOLO的定位误差显着高于最近的R-CNN变体,例如 作为更快的R-CNN,Faster R-CNN中的region proposal network(RPN)预测anchor boxes的偏移和置信度,anchor boxes使用人工挑选的priors,而不是直接预测边界框坐标。 每个anchor box的4个坐标和2个评分值相关联, which estimate the probability of object and not object of the proposed box.
2 Methodology
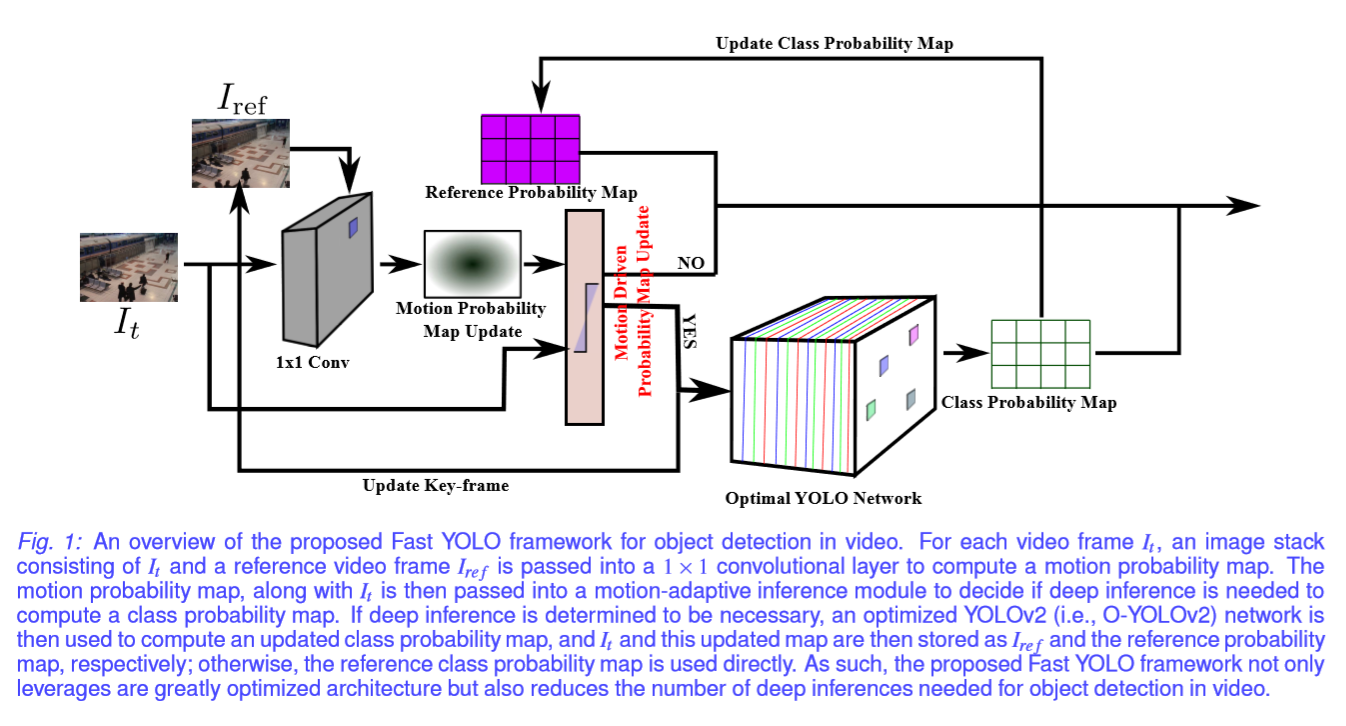
所提出的Fast YOLO框架分为两个主要组件:i)优化的YOLOv2架构,以及ii)运动自适应推理(见Figure 1)。 对于视频每一帧,由视频帧与参考帧组成的图像栈被传递到1×1卷积层。 卷积层的结果是运动概率映射,然后将其馈送到运动自适应推断模块以确定是否需要深度推断来计算更新的类别概率映射。 正如Introduction中提到的,主要目标是引入视频中的对象检测框架,可以在嵌入式设备上更快地执行操作,同时减少资源使用,进而显着降低功耗。 通过利用这种运动自适应推理方法,深度推断的频率大大降低,并且仅在必要时才执行。
2.1 Optimized Network Architecture
深度神经网络的主要挑战之一,尤其是在将它们用于嵌入式场景时,主要体现在网络架构设计中。设计过程通常由人类专家来完成,他探索大量的网络配置,从而在建模精度和参数数量方面为特定任务寻找最佳架构。目前通常将寻找优化网络架构作为超参数优化问题来解决,但这种解决该问题的方法非常耗时且大多数方法对于大型网络架构而言在计算上难以处理,或者导致次优解决方案不足以应用到嵌入式系统中。例如,超参数优化的常用方法是网格搜索,其中检查大范围的不同网络配置,然后选择最佳配置作为最终网络架构。然而,为了视频中的对象检测而设计的深度神经网络(例如YOLOv2)具有大量的参数,因此在计算上不易搜索整个参数空间以找到最优解。因此,我们不是利用超参数优化方法来获得基于YOLOv2的最佳网络架构,而是利用专门设计的用于提高网络效率的网络优化策略。特别是,我们利用进化深度智能框架来优化网络架构,以合成一个满足嵌入式设备内存和计算能力限制的深度神经网络。
在进化深度智能框架中,深层神经网络的建筑特征通过概率遗传编码建模策略建模。具体而言,以这种方式产生的概率“DNA”编码在网络架构内存在所有可能的突触的概率。然后利用祖先网络(模仿遗传)的概率“DNA”以及环境因素以随机方式(模仿自然选择和随机突变)合成新的后代深度神经网络。这种编码和合成过程是一代一代重复的,随着时间的推移会产生越来越有效的深度神经网络。这种方法的一个关键优势是,与超参数优化方法不同,需要评估大量可能的解决方案,这是显着减少的,因此显着降低了寻找最佳网络架构的计算复杂性。
为了利用演化深度智能框架获得基于YOLOv2的优化网络体系结构,以实现视频嵌入式对象检测,我们考虑到计算能力和可用内存在嵌入式设备上受到很大限制的事实。 因此,我们配置网络合成过程中使用的环境因素,使得网络结构中的参数数量在每一代都大大减少,因为参数的数量是深度神经网络计算和存储要求的主要因素。
使用这种方法,我们可以自动找到基于YOLOv2(我们将称之为O-YOLOv2)的优化网络体系结构,该体系结构与原始YOLOv2网络体系结构相比,包含的参数少了约2.8倍。 运行这种优化的深度神经网络不仅大大降低了计算和内存的需求,而且还降低了处理器单元的功耗,这对于嵌入式设备非常重要。
2.2 Motion-adaptive Inference
为了进一步降低视频中嵌入对象检测的处理器单元的功耗,我们利用并非所有捕获的视频帧都包含唯一信息这一事实,因此不需要在所有帧上执行深入推理。 因此,我们引入运动自适应推理方法来确定特定视频帧是否需要深度推断。 通过在必要时使用前面章节中介绍的O-YOLOv2网络进行深入推理,该运动自适应推理技术可以帮助框架减少对计算资源的需求,从而显着降低系统的功耗以及 处理速度的提高。
运动自适应推理过程可以在Figure 1中看到。每个帧与参考帧Iref堆叠在一起形成一个图像堆栈。 然后在图像堆栈上执行1×1卷积层以产生运动概率图。 运动概率映射连同框架It一起被传递到运动自适应推理模块,该模块确定框架与参考框架相比是否足够独特,以确保深度推理计算新的类别概率图。 如果模块确定需要进行深度推理,则使用O-YOLOv2网络来计算更新的类别概率图,然后将它和更新的图分别存储为Iref和参考概率图。 在运动自适应推理模块确定帧It不需要深度推断的情况下,所存储的参考类概率图被直接使用而不在帧It上执行O-YOLOv2。
通过利用这个简单而有效的过程,只有需要深度推理的帧才能被处理,这不仅降低了功耗,而且还减少了每帧的平均运行时间,并且可以为静止的或频繁发生微小变化的环境提供更快的框架。
3 Results & Discussion
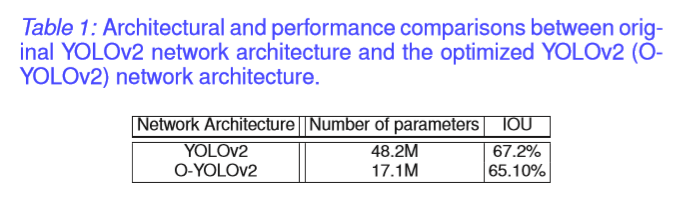
对提出的Fast-YOLO框架使用两种不同的策略进行评估。 首先,我们评估优化的YOLOv2(即O-YOLOv2)网络架构在Pascal VOC 2007数据集上的原始YOLOv2网络架构的建模精度和性能,以演示网络架构优化过程的有效性。 Table 1显示了O-YOLOv2与Pascal VOC数据集上原始YOLOv2之间的架构和性能比较。 可以观察到,与原始YOLOv2相比,O-YOLO网络架构小2.8倍,IOU仅下降2%,这对真实世界的基于视频的对象检测应用几乎没有影响。
其次,提出的Fast YOLO框架,O-YOLOv2和原始YOLOv2是根据的视频在Nvidia Jetson TX1嵌入式系统上的平均运行时间来评估的。 从Table 2可以看出,所提出的快速YOLO框架可以将深度推断的数量平均减少68.5%,从而导致平均运行时间为56ms,而原始YOLOv2实现的运行时间为184ms(速度约3.3x以上)。

4 Conclusion
在本文中,我们介绍了Fast YOLO,这是一个用于视频中实时嵌入对象检测的新框架。 虽然YOLOv2被认为是在强大的GPU上实时推断的最先进的框架,但它不可能在嵌入式设备上实时使用它。 在这里,我们利用进化深度智能框架,基于YOLOv2生成优化的网络架构。 优化的网络架构被用于运动自适应推理框架内,以加速检测过程并降低嵌入式设备的能耗。 实验结果表明,所提出的Fast YOLO框架的平均运行时间比原来的YOLOv2快3.3倍,平均可以减少38.13%的深层推理,并且具有约小2.8x的网络结构。