1 引用
1.1 定义及编程实践
引用,是某个已存在变量的另一个名字。
一旦把引用初始化为某个变量,就可以使用该引用名称或变量名称来指向变量。
注意:
-
引用没有定义,是一种关系型声明。声明它和原有某一变量(实体)的关
系。因此引用类型必须与原类型保持一致,且不分配内存。与被引用的变量有相同的地
址。 -
& 符号前有数据类型时,是引用。其它皆为取地址。
-
可对引用再次引用。多次引用的结果,是某一变量具有多个别名。
创建引用例子如下:
// reference.cpp
#include <iostream>
using namespace std;
int main ()
{
// 声明简单的变量
int i;
double d;
// 声明引用变量
int& r = i;
double& s = d;
i = 1;
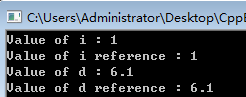
cout << "Value of i : " << i << endl;
cout << "Value of i reference : " << r << endl;
d = 6.1;
cout << "Value of d : " << d << endl;
cout << "Value of d reference : " << s << endl;
getchar();
return 0;
}
运行结果:
引用编程实践如下:
// reference2.cpp
#include <iostream>
using namespace std;
int main()
{
int a = 1;
int& b = a; // b = a = 1
a = 2;
int *p = &a;
*p = 3; // a = 3
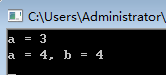
cout << "a = " << a << endl;
b = 4; // b = a -> a = 4
cout << "a = " << a << ", b = " << b << endl;
getchar();
return 0;
}
运行结果:
1.2 引用和指针的区别
引用很容易和指针混淆,它们之间有以下不同:
-
不存在空引用。引用必须连接到一块合法的内存。指针可以为空指针。
-
引用必须在创建时被初始化(引用作为函数参数的时候不需要初始化,因为形参一定会被赋值的)。指针可以在任何时间被初始化。
-
一旦引用被初始化为一个对象,就不能被指向到另一个对象。指针可以在任何时候指向到另一个对象。
1.3 引用的意义
-
引用作为其他变量的别名而存在,因此在一些场合可以代替指针
-
引用相对于指针来说具有更好的可读性和实用性
// 无法实现两数据的交换
void swap(int a,int b);
//开辟了两个指针空间用于交换
void swap(int *a,int *b);
// referenceSwap.cpp,不开辟空间使用引用进行数值交换
#include <iostream>
using namespace std;
void swap(int& a, int& b)
{
int temp;
temp = a;
a = b;
b = temp;
}
int main()
{
int a = 1,b = 2;
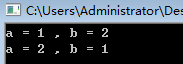
cout << "a = " << a << " , b = " << b << endl;
swap(a,b);
cout << "a = " << a << " , b = " << b << endl;
getchar();
return 0;
}
运行结果:
1.4 堆变量,栈变量
全局变量、静态局部变量、静态全局变量,new 产生的变量都在堆中,动态分配的变量在堆中分配。
局部变量在栈里面分配。
程序为栈变量分配动态内存,在程序结束为栈变量清除内存,但是堆变量不会被清除。
1.5 引用作为函数的返回值
当函数返回值为引用时:
- 若返回栈变量引用时,不能成为其他引用的初始值。
如下代码所示:
// funcReturnRef.cpp,引用作为函数的返回值,什么时候可以为其他引用初始化的值
#include <iostream>
using namespace std;
// 返回栈变量
int getA1()
{
int a;
a = 1;
return a;
}
// 返回栈变量引用
int& getA2()
{
int a;
a = 1;
return a;
}
int main()
{
int a1 = 0;
int a2 = 0;
// 值拷贝
a1 = getA1();
// 将 栈变量引用 赋值给 变量,编译器类似做了如下隐藏操作:a2 = *(getA2())
a2 = getA2();
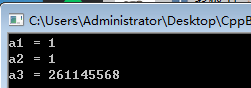
// 将 栈变量引用 赋值给 另一个引用作为初始值。此时将会有警告:返回局部变量或临时变量的地址
int& a3 = getA2();
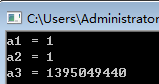
cout << "a1 = " << a1<< endl;
cout << "a2 = " << a2<< endl;
cout << "a3 = " << a3<< endl;
getchar();
return 0;
}
警告信息:

第一次运行结果:
第二次运行结果:
- 若返回堆变量引用时,可以成为其他引用的初始值
如下代码所示:
// funcReturnRef2.cpp,引用作为函数的返回值,什么时候可以为其他引用初始化的值
#include <iostream>
using namespace std;
// 返回堆变量
int getA1()
{
static int a;
a = 1;
return a;
}
// 返回栈变量引用
int& getA2()
{
static int a;
a = 1;
return a;
}
int main()
{
int a1 = 0;
int a2 = 0;
// 值拷贝
a1 = getA1();
// 将 栈变量引用 赋值给 变量,编译器类似做了如下隐藏操作:a2 = *(getA2())
a2 = getA2();
// 将 堆变量引用 赋值给 另一个引用作为初始值。由于是静态区域,地址不变,内存合法。
int& a3 = getA2();
cout << "a1 = " << a1<< endl;
cout << "a2 = " << a2<< endl;
cout << "a3 = " << a3<< endl;
getchar();
return 0;
}
运行结果:

1.6 指针引用作函数参数
C++ 中指针引用作函数参数,与 C 语言中二级指针作函数参数的区别。
如下代码所示:
// pointReference.cpp
// C++ 中指针引用作函数参数,与 C 语言中二级指针作函数参数的区别
#include <iostream>
using namespace std;
#define AGE 18
// C 语言中的二级指针
int getAge1(int **p)
{
int age = AGE;
int *ptemp = &age;
// p 是实参的地址, *实参的地址,去间接的修改实参
*p = ptemp;
return 0;
}
// C++ 中指针引用
int getAge2(int* &p)
{
int age = AGE;
if(p == NULL)
{
p = (int *)malloc(sizeof(int));
if(p == NULL)
return -1;
}
// 给 p 赋值,相当于给 main 函数中的 pAge 赋值
*p = age;
return 0;
}
int main(void)
{
int *pAge = NULL;
// 1 C 语言中二级指针
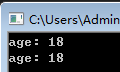
getAge1(&pAge);
cout << "age: " << *pAge << endl;
pAge = NULL;
// C++ 中指针引用
getAge2(pAge);
cout << "age: " << *pAge << endl;
pAge = NULL;
getchar();
return 0;
}
运行结果:
1.7 const 引用
-
const 对象的引用必须是 const 的。
-
const 引用可以使用相关类型的对象(常量,非同类型的变量或表达式)初始化。这个是 const 引用与普通引用最大的区别。
例:
const int &a = 1;
double x = 1.1;
const int &b = x;
- const 引用限制对象为只读,不能通过修改 const 引用来修改 const 对象。
2 inline 内联函数
C 语言中有宏函数的概念。宏函数的特点是内嵌到调用代码中去,避免了函数调用的开销。但是由于宏函数的处理发生在预处理阶段,确实了语法检测和有可能带来的语义差错,因此 C++ 引入了 inline 内联函数。
2.1 内联函数基本概念
-
内联函数声明时 inline 关键词必须和函数定义结合在一起,否则编译器会忽略内联请求。
-
C++ 编译器直接将函数体插入在函数调用的地方。
-
内联函数没有普通函数调用时的额外开销(压栈,跳转,返回)
-
内联函数是一种特殊的函数,具有普通函数的特征(参数检查,返回类型等)
-
内联函数由编译器处理,直接将编译后的函数体插入在调用的地方,宏函数由预处理器处理,进行简单的文本替换,没有任何的编译过程。
-
C++ 对内联函数的限制:
- 不能存在任何形式的循环语句
- 不能存在过多的条件判断语句
- 函数体不能过于庞大
- 不能对函数进行取址操作
- 函数内联声明必须在调用语句之前
-
编译器对于内联函数的限制不是绝对的,内联函数相对于普通函数的优势知识节省了函数调用时压栈,跳转,和返回的开销。因此,当函数体的执行开销远大于压栈,跳转,和返回的开销时,那么内联函数将没有意义。
实例代码如下所示:
// inlineFunction.cpp
// 内联函数示例
#include <iostream>
using namespace std;
inline void func()
{
cout << "this is inlineFunction example!" << endl;
}
int main()
{
func();
getchar();
return 0;
}
运行结果:

3 函数重载
函数重载:用同一个函数名定义不同的函数,当函数名和不同的参数搭配时函数的含义不同。
3.1 重载规则
-
函数名相同
-
参数个数不同,参数的类型不同,参数顺序不同,均可构成重载。
-
返回值类型不同则不可以构成重载。
如下所示:
void func(int a); // ok
void func(char a); // ok
void func(char a,int b); // ok
void func(int a,char b); // ok
char func(int a); // 与第一个函数冲突,报错
3.2 调用准则
-
严格匹配,找到即调用。
-
通过隐式转换寻求一个匹配,找到即调用。
3.3 重载底层实现
C++ 利用 name mangling(倾轧)技术,来改变函数名,以区分参数不同的同名函数。
实现原理:用 v c i f l d 表示 void char int float long double 及其引用。
如下所示:
void func(char a); // func_c(char a);
void func(char a,int b,double c); // func_cid(char a,int b,double c);
3.4 函数指针基本语法
// 方法一:
// 声明一个函数类型
typedef void (myfunctype)(int a,int b);
// 定义一个函数指针
myfunctype* fp1= NULL;
// 方法二:
// 声明一个函数指针类型
typedef void (*myfunctype_pointer)(int a,int b)
// 定义一个函数指针
myfunctype_pointer fp2 = NULL;
// 方法三:
// 直接定义一个函数指针
void (*fp3 )(int a,int b);
3.5 函数重载和函数指针结合
当使用重载函数名对函数指针进行赋值时,根据重载规则挑选与函数指针参数列表一致的候选者,严格匹配候选者的函数类型与函数指针的函数类型。
示例代码如下所示:
#include <iostream>
using namespace std;
void func(int a, int b)
{
cout << a << b << endl;
}
void func(int a, int b, int c)
{
cout << a << b << c << endl;
}
void func(int a, int b, int c, int d)
{
cout << a << b << c << d << endl;
}
// 1 定义一个函数类型
typedef void(myfunctype)(int, int); //定义了一个函数类型, 返回值void 参数列表是 int,int ,, void()(int,int)
// 2 定义一个函数指针类型
typedef void(*myfunctype_pointer)(int, int); //定义了一个函数指针类型, 返回值void 参数列表是 int,int ,, void(*)(int,int)
int main(void)
{
//1 定义一个函数指针
myfunctype * fp1 = NULL;
fp1 = func;
fp1(10, 20);
// 2 定义一个函数指针
myfunctype_pointer fp2 = NULL;
fp2 = func;
fp2(10, 20);
// 3 直接定义一个函数指针
void(*fp3)(int, int) = NULL;
fp3 = func;
fp3(10, 20);
cout << " -----------------" << endl;
// 此时的fp3 是 void(*)(int,int)
// fp3(10, 30, 30); // fp3 恒定指向一个 函数入口,void func(int, int) 的函数入口
// fp3(10, 30, 40, 50); // 想要通过函数指针,发生函数重载 是不可能。
fp3(10, 20);
void(*fp4)(int, int, int) = func; // 在堆函数指针赋值的时候,函数指针会根据自己的类型 找到一个重载函数
fp4(10, 10, 10);
// fp4(10, 10, 10, 10);
// 函数指针,调用的时候是不能够发生函数重载的。
void(*fp5)(int, int, int, int) = func; // void func(int ,int ,int ,int )
fp5(10, 10, 10, 10);
return 0;
}
运行结果:

3.6 函数重载总结
-
重载函数在本质上是相互独立的不同函数。
-
函数重载是由函数名和参数列表决定的。