回顾
在之前的系列中,我们除了介绍了ManagedMyC这个例子、手动构建了一个SimpleLSHost,主要的精力都放在了Lex和Yacc中。之所以这样安排,因为我觉得“内功”比“招式”重要的多。不过对于学习而言,一上来就接触深层次的东西往往是个艰苦的过程。正因为如此,在接下来的几篇中,我将要开始介绍语言服务的各种“招式”,那么这篇就先从智能感知开始吧。
构建一个LS包
我不打算从头开始构建一个LS包,而是从我之前创建的SimpleLSHost开始。点击下载SimpleLSHost实例。如果想要从头开始,可以参考:VSX开发之语言服务系列(4)——从空Package开始构建语言服务框架和VSX开发之语言服务系列(5)——构建自己的Scanner和Pareser。我打算做这么一个简单的事情,当用户输入"$"的时候,自动提示在上下文中输入过的数字字符;当输入"@"时自动提示上下文中的小写字符串。看似是一个十分简单的需求。好吧,现在开始。
创建触发器
首先我们要实现"$"和"@"的触发功能,因为智能感知的窗体是“触发”出来的。至于感知的内容可以稍后讨论。
定义标记
因为现在"$"和"@"是两个有意义的标记,所以首先在parser.y中定义两个标记,分别表示"$"和"@"。然后重新编译工程两次。(在开发过程中,我经常发现只编译一次无法使对parser.y或lexer.lex的修改生效)
%token DOLLAR
%token AT
定义触发
在UserSupplied下的Configuration的构造函数中添加如下两行代码:
ColorToken((int)Tokens.DOLLAR, TokenType.Keyword, Number, TokenTriggers.MemberSelect);
ColorToken((int)Tokens.AT, TokenType.Keyword, Lowletter, TokenTriggers.MemberSelect);
这里的Tokens.DOLLAR和Tokens.AT便是parser .y刚定义的标记。这两句话定义了这两个标记的标记类型(无关紧要),颜色对象和触发器。这里的触发器设置成MemberSelect,因为这是智能感知的触发器。
让扫描器返回标记
标记定义好以后需要扫描器返回标记。在lexer.lex的第一部分中定义两个lex自己用的标记,注意这里"$"是特殊字符,需要转义。
dollar "\$"
at "@"
添加两个匹配规则,匹配动作为返回标记,注意要在"."规则之前(即任意字符匹配之前)。
{dollar} { return (int)Tokens.DOLLAR;}
{at} { return (int)Tokens.AT;}
添加提示信息
定位到UserSupplied下的Resolver.cs在FindMembers方法中添加如下代码:
List<Babel.Declaration> members = new List<Babel.Declaration>();members.Add(new Babel.Declaration("Tips1", "Tips1", 0, "Tips1"));
members.Add(new Babel.Declaration("Tips2", "Tips2", 0, "Tips2"));
return members;
Declaration是Babel定义的对象。实际上真正的提示信息和IDE的接口是AuthoringScope中的GetDeclarations方法,该方法返回一个Microsoft.VisualStudio.Package.Declarations集合。IDE通过这个集合的接口获得用户想要显示的提示信息。Babel的Declarations继承了Microsoft.VisualStudio.Package.Declarations,并且创建了Babel.Declaration,以便我们能像上面的代码那样只是简单的向集合里面添加即可。Babel.Declaration的构造函数带有四个参数,我只解释第三个参数。第三个参数的原型是int glyph,这表示的是每条感知信息的图标,可以使用IDE内建的图标。关于这些图标的索引值,在SDK文档的The Default Image List for a Language Service主题中有描述,这里便不再重复了。但是值得注意的是,文档中给出的public enum IconImageIndex实际上是错的!在本篇的附录中,我会将这个错误纠正。
调试
到这里触发器定义好了,我们可以看看效果,重新编译工程,并执行。(如果读者是下载SimpleLSHost的。可能会因为安装VS路径与我不同而无法启动。这时请检查工程属性中Debug所使用的外部程序路径。)打开一个.sls文件。下面是效果图:

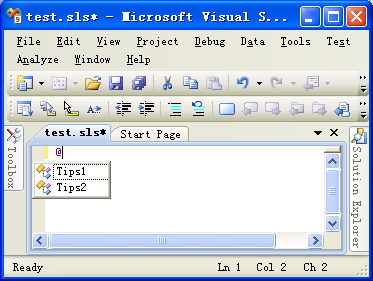
可以看到当输入"$"或"@"时都会出现智能提示,这个提示使用了"public class"式样的图标,并显示了Tips1和Tips2。当然这么简单的静态的提示,对于实际的语言服务是没有太大意义的,接下来,我们做些有意义的事情。
了解智能提示的工作过程
在接下去之前,我打算把上面部分的工作过程梳理一下,以便读者能更容易理解接下来的工作。在前面介绍着色器工作原理的章节中,我提到过IScanner接口。这是Scanner和IDE表现层的接口,其中ScanTokenAndProvideInfoAboutIt方法会被IDE反复调用并返回TokenInfo结构,TokenInfo包含标记的着色信息,类型信息,触发器信息等。IDE在获得一个标记之后决定下一步的处理,而Babel实现了一个LineScanner,并实例化Scanner:
Babel.ParserGenerator.IColorScan lex = null;
this.lex = new Babel.Lexer.Scanner();
于是在ScanTokenAndProvideInfoAboutIt中,LineScanner根据Configuration中的“配置”,给TokenInfo赋值。因此,Configuration实际上便成了“配置”文件,可以在Configuration中定义触发器。
在TokenInfo返回给IDE后,如果其中是个MemberSelect触发器,IDE会调用LanguageService类中的ParseSource方法,这个方法返回一个AuthoringScope,IDE再调用AuthoringScope的GetDeclarations方法,得到感知的信息列表。ParseSource还会传入ParseRequest对象,这个对象包含ParseReason枚举,可以在ParseSource方法中判断ParseReason是不是MemberSelectAndHighlightBraces,如果是可以为返回的AuthoringScope对象做特殊处理。Babel还为用户设计了IASTResolver接口,并实现了一个继承的AuthoringScope,在这个AuthoringScope中调用IASTResolver接口的FindMembers方法。我们需要做的便是在Resolver中实现这个方法,上面我们就是这样做的。
下图简要说明了这个过程:
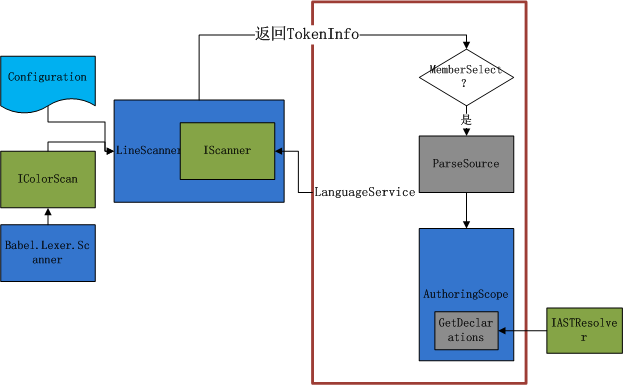
使用Parser获得上下文信息
LanguageService.ParseSource方法
理解了上面这个过程,应该想到的是如果想要把上下文的信息加入到智能提示信息中,就像这个实例的需求那样,关键点在于ParseSource方法返回的这个AuthoringScope能不能为我们提供足够的上下文信息。好在,ParseSource方法实例化了一个解析器,并调用了Parse方法进行了解析,看下面四行代码:
Babel.Lexer.Scanner scanner = new Babel.Lexer.Scanner();
Parser.Parser parser = new Parser.Parser();
parser.scanner = scanner;
yyparseResult = parser.Parse();
可以看出parser使用的扫描器就是Babel.Lexer.Scanner,跟IDE表现层使用的是同一个Scanner!!下图总结了Scanner与其实现的接口的关系:
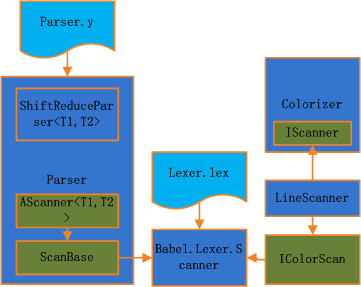
Parse方法是唯一能处理底层解析,并使用我们定义的语法区分标记的方法。但是这个方法只返回成功与否,光从返回值不能获得足够的信息。所以,只能在Parser中定义一些字段,并在解析的过程中将信息保存在Parser中。
部分类Parser
现在我们定位到ManagedBabel下的Parser.cs中,这个Parser是个部分类,并且存在于Babel.Parser名字空间下,另一个Parser便是parser.y生成的Parser。于是,我们便可以在这里的Parser中定义我们自己的字段。观察现有的Parser可以发现其中已经定义了一些额外的字段和方法,其中包括一个IList<TextSpan[]> braces;这是原先的ManagedMyC为了实现括号匹配用的,在以后的文章中,将介绍如何实现括号匹配。
底层解析与扫描处理
OK,现在开始实现我们的业务吧。为了保存上下文中含有的数字和小写字母,我们必须定义两个存放它们的List,在Parser中定义两个字段,我们暂时使用public修饰,并在初始化函数中初始化它们:
public IList<TextSpan> numbers;
public IList<TextSpan> literals;public void MBWInit(ParseRequest request)
{...
numbers = new List<TextSpan>();
literals = new List<TextSpan>();
}
在Parser中临时定义如下三个辅助方法:
//add numbers
private void AddNumbers(params Babel.ParserGenerator.LexLocation[] locs)
{
foreach (Babel.ParserGenerator.LexLocation l in locs)
{
numbers.Add(LocationToSpan(l));
}
}//add literals
private void AddLiterals(params Babel.ParserGenerator.LexLocation[] locs)
{
foreach (Babel.ParserGenerator.LexLocation l in locs)
{
literals.Add(LocationToSpan(l));
}
}//convert from location to textspan
private TextSpan LocationToSpan(Babel.ParserGenerator.LexLocation s)
{
TextSpan ts = new TextSpan();
ts.iStartLine = s.sLin - 1;
ts.iStartIndex = s.sCol;
ts.iEndLine = s.eLin - 1;
ts.iEndIndex = s.eCol;
return ts;
}
在parser.y中修改语法定义部分的匹配行为代码,如下。这里的含义是,当序列NUMBER、LOWLETTER 规约时执行上面定义了两个辅助函数。
Declaration
: NUMBER { AddNumbers(@1);}
| CAPLETTER
| LOWLETTER { AddLiterals(@1);}
;
这里"@1"会被MPPG编译成location_stack.array[location_stack.top-1],这是个LexLocation;同理,"@2"会被编译成location_stack.array[location_stack.top-2]。在之前文章中我提到过LexLocation表示标记的位置信息,这里"@1"表示NUMBER标记的位置,我们将这些位置信息在解析过程中保存在Parser对象中。
为了使位置信息经由扫描器传递给解析器,需要在lexer.lex的第一部分加入如下代码,这段代码来自于ManagedMyC:
%{
internal void LoadYylval()
{
yylval.str = tokTxt;
yylloc = new LexLocation(tokLin, tokCol, tokLin, tokECol);
}
%}
在lexer.lex的第二部分加入如下代码:
%{
LoadYylval();
%}
这样在每个标记扫描后,会把每个标记的yylloc、yylval加载,这样解析器就可以通过yylloc、yylval访问标记的位置信息和值信息。
表层处理
完成上述过程后,ParseSource方法便可以获得我们想要的上下文信息了,只不过这个信息还只是标记的位置信息,我们需要的是文本信息,可以利用ParseSource中的Source对象将位置信息转化成文本。可能有些读者会问:为什么要将位置信息保存下来,不直接保存文本吗?事实上,的确如此,在这里我只是为了演示Source的GetText方法。在实际的使用中,建议直接利用标记的值信息,这涉及到"$n"的用法将在以后的文章中涉及。还有一个问题,提供智能感知信息列表的是Resolver,Resolver是无法直接访问到Parser的,于是,我们不得不将转化的结果保存在Resolver对象中。
在Resolver中定义两个共有字段,用来存储:
public List<string> numbers = new List<string>();
public List<string> literals = new List<string>();
为了方便,将ManagedMyC/AuthoringScope中的IASTResolver resolver字段改成public Resolver resolver。
在ParseSource方法开始初始化一个AuthoringScope,并在最后返回这个AuthoringScope:
AuthoringScope asp = new AuthoringScope(null);
...
return asp;
接着在ParseSource的yyparseResult = parser.Parse();之后添加如下代码,这段代码便是将位置信息转化成文本,并存储到Resolver对象中。
foreach (TextSpan ts in parser.numbers)
{
asp.resolver.numbers.Add(source.GetText(ts));
}foreach (TextSpan ts in parser.literals)
{
asp.resolver.literals.Add(source.GetText(ts));
}
这样在Resolver中的FindMember方法就可以这样写了:
List<Babel.Declaration> members = new List<Babel.Declaration>();
foreach(string number in numbers)
members.Add(new Babel.Declaration(number, number, 0, number));
foreach (string literal in literals)
members.Add(new Babel.Declaration(literal, literal, 0, literal));return members;
编译运行,结果如下。可以看到,当我们输入"$"或者"@"的时候,智能感知了上文中小写字母和数字。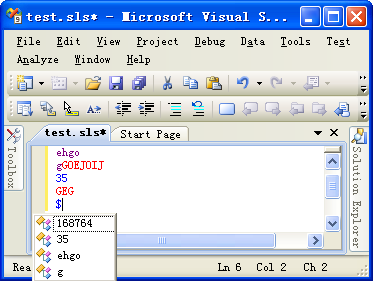
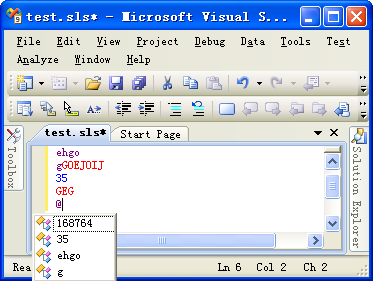
还差一点。我们想要的是"$"显示数字,"@"显示小写的字符串啊。因为在Resolver对象中并没有判断标记是"$"还是"@",而是统一处理了。现在我们需要将标记信息传递给Resolver。
标记信息需要AuthoringScope传递给Resolver,所以修改AuthoringScope.GetDeclarations,修改如下这个case,把TokenInfo传给FindMembers方法。
case ParseReason.MemberSelectAndHighlightBraces:
declarations = resolver.FindMembers(info, line, col);
修改FindMembers方法:
List<Babel.Declaration> members = new List<Babel.Declaration>();
Microsoft.VisualStudio.Package.TokenInfo token = result as Microsoft.VisualStudio.Package.TokenInfo;
if (token != null)
{
switch (token.Token)
{
case (int)Babel.Parser.Tokens.DOLLAR:
{
foreach (string number in numbers)
members.Add(new Babel.Declaration(number, number, 0, number));
}
break;
case (int)Babel.Parser.Tokens.AT:
{
foreach (string literal in literals)
members.Add(new Babel.Declaration(literal, literal, 0, literal));
}
break;
}
}return members;
在这个方法中我们根据TokenInfo,如果是DOLLAR就显示数字,反之显示字符串。
还有最后一步,在LineScanner的ScanTokenAndProvideInfoAboutIt方法的if (token != (int)Tokens.EOF)语句块中添加tokenInfo.Token = token;之所以要加这句话,是因为ScanTokenAndProvideInfoAboutIt返回的TokenInfo需要包含token,但是Babel却没有!!我不知道这是不是微软的失误。呵呵。如果这里TokenInfo不返回token值的话,我们就不能在表现层得知是哪个标记。
编译运行,最后的效果是这样的。
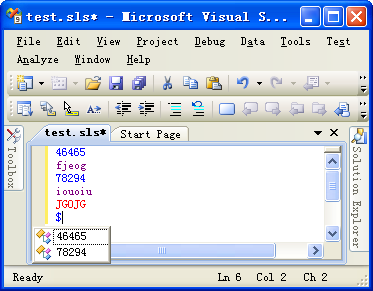
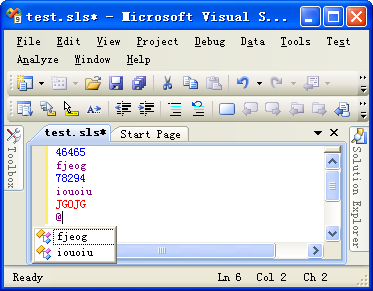
小结
本篇讲解了如何在语言服务的表现层集成智能感知功能,并用一个例子说明了具体实现memberselect功能的步骤。可以在下面这个地址下载本篇的例子程序:SimpleLSHostMemberSelect
这个例子程序是比较基本的,一个真正的语言服务要做的事情比这个多的多。读者关键要理解各部分协调的机理,这样才能举一反三。
附录
下面是可以直接在程序中使用的IconImageIndex。
internal enum IconImageIndex
{
// access types
AccessPublic = 0,
AccessInternal = 1,
AccessFriend = 2,
AccessProtected = 3,
AccessPrivate = 4,
AccessShortcut = 5,
Base = 6,
// Each of the following icon type has 6 versions,
//corresponding to the access types
Class = Base * 0,
Constant = Base * 1,
Delegate = Base * 2,
Enumeration = Base * 3,
EnumMember = Base * 4,
Event = Base * 5,
Exception = Base * 6,
Field = Base * 7,
Interface = Base * 8,
Macro = Base * 9,
Map = Base * 10,
MapItem = Base * 11,
Method = Base * 12,
OverloadedMethod = Base * 13,
Module = Base * 14,
Namespace = Base * 15,
Operator = Base * 16,
Property = Base * 17,
Struct = Base * 18,
Template = Base * 19,
Typedef = Base * 20,
Type = Base * 21,
Union = Base * 22,
Variable = Base * 23,
ValueType = Base * 24,
Intrinsic = Base * 25,
JavaMethod = Base * 26,
JavaField = Base * 27,
JavaClass = Base * 28,
JavaNamespace = Base * 29,
JavaInterface = Base * 30,
// Miscellaneous icons with one icon for each type.
Error = 187,
GreyedClass = 188,
GreyedPrivateMethod = 189,
GreyedProtectedMethod = 190,
GreyedPublicMethod = 191,
BrowseResourceFile = 192,
Reference = 193,
Library = 194,
VBProject = 195,
VBWebProject = 196,
CSProject = 197,
CSWebProject = 198,
VB6Project = 199,
CPlusProject = 200,
Form = 201,
OpenFolder = 202,
ClosedFolder = 203,
Arrow = 204,
CSClass = 205,
Snippet = 206,
Keyword = 207,
Info = 208,
CallBrowserCall = 209,
CallBrowserCallRecursive = 210,
XMLEditor = 211,
VJProject = 212,
VJClass = 213,
ForwardedType = 214,
CallsTo = 215,
CallsFrom = 216,
Warning = 217,
}