-
MySQL数据表记录删操作
- 删除操作:作用删除表里的记录行(都是整行整行的删除的)
- 单表的删除:语法:delete from 表名 where 筛选条件
案例:删除员工编号大于203的员工信息 delete from employees where employee_id>203;
- 多表删除:
语法:delete 别名1,别名2from 表1 别名1,表2 别名2where 连接条件 and 筛选条件;注意:如果只删表1的就只写别名1,如果两个表的记录都删就别名1,别名2)delete 别名1,别名2from 表1 别名1[连接类型] join 表2 别名2on 连接条件where 筛选条件;
案例:删除任波涛的年龄信息 delete a from students s inner join ages a on s.age_id = a.id where s.name='任波涛';
- .整表记录全部删除,不能加where条件:truncate table 表名;
delete和truncate区别:①delete可以加where条件②truncate删除的效率高一些③假如要删除的表上有自增长字段,如果用delete删除,再插入数据,自增长从断点值开始,用truncate删除,再插入数据,从1开始;④truncate删除没有返回值,delete删除有返回值⑤truncate删除不能回滚,delete删除可以回滚
-
.MySQL数据库管理DDL语言和数据库管理
- DDL:Data Definition Language数据库定义语言:主要作用是对数据库和表的管理,这里的表的管理是表本身,不是表里的记录数据值的管理,前面的增删改查是对表里的记录数据值的操作,本质都不同注意区别;
- DDL的作用:
1.对数据库的管理创建数据库,修改数据库,删除数据库2.对数据库里的数据表的管理创建数据表:create修改数据表的结构设计(字段的名和字段的数据类型):alter删除数据表:drop
数据库的管理: 创建:创建数据库books create database if not exists books; 修改数据库:不会做! 修改数据库的字符集: alter database books character set gbk; 删除数据库: drop database if exists books;
-
MySQL数据表的管理
-
表的管理:1.创建表:语法:create table 表名(字段名 字段里保存数据的类型【(数据的长度) 约束】,字段名 字段里保存数据的类型【(数据的长度) 约束】,字段名 字段里保存数据的类型【(数据的长度) 约束】......);
案例:中books里创建一张表book用来保存书的信息 create table book( id int , #书的编号 b_name varchar(20), #书的名字 b_price double, #书价格 author_id int, # 关联作者信息表,作者编号 publishDate Datetime#出版日期 ); 案例:创建书的作者信息表 create table author( id int, a_name varchar(10), a_sex char(1) );
2.表的修改:首先看看可以修改表的那些东西?①可以修改字段名②可以修改字段的数据类型或约束③可以添加新字段④删除字段⑤修改表名①:修改publishDate为publish_date (注意后面要跟上类型)alter table book change column publishDate publish_date datetime;②修改publish_date的时间时间类型(datetime)改为date日期型alter table book modify column publish_date date;③给作者表添加工资字段alter table author add column salary double;④删除作者表工资字段alert table author drop column salary;⑤修改表名alter table author rename to b_author;总结表结构的修改语法:alter table 表名 add/drop/modify/change column 字段名 字段类型 【约束】3.表的删除语法:drop table if exists b_author ; //直接删除了4.表的复制①仅复制表的结构create table c_author like author;②复制表的结构和数据create table c_author1select * from author;③只复制表结构和部分数据create table c_author2select * from author where id<3;④只复制部分字段,且不要数据create table c_author3select in a_name from author where 0;
-
MySQL数据类型
- MySQL数据库中的常用数据类型:
数值型:①整型②小数类型定点型浮点型字符型:①短的文本:char varchar②长的文本:text blob(二进制)日期型①数值型

小数应该知道的知识点:①浮点型:float(M,D) double(M,D);②定点型:decimal(M,D);create table t_float(f1 float(5,2);③2:表示小数点后保留位数f2 double(5,2); ④5:表示整数部分和小数部分合起来的总位数f3 decimal; ⑤插入值超过范围,会变成临界值999.99#⑥不设置后面的M和D值,float和double会根据插入的实际值来确定精度,decimal默认(10,0)表示总体10位数,小数位是0;#⑦如果要求小数点后的高精度需求的时候,建议用decimal);②日期时间类型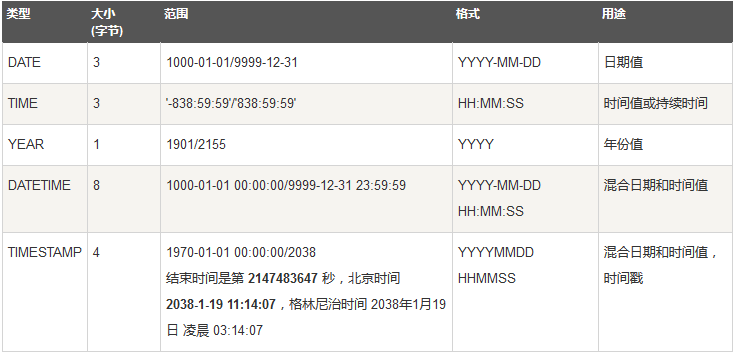
日期型应该知道的知识点:①日期型的数值要用单引号包裹起来②timestamp时间戳会受到时区的影响set time_zone='+9:00'; #设置时区③字符型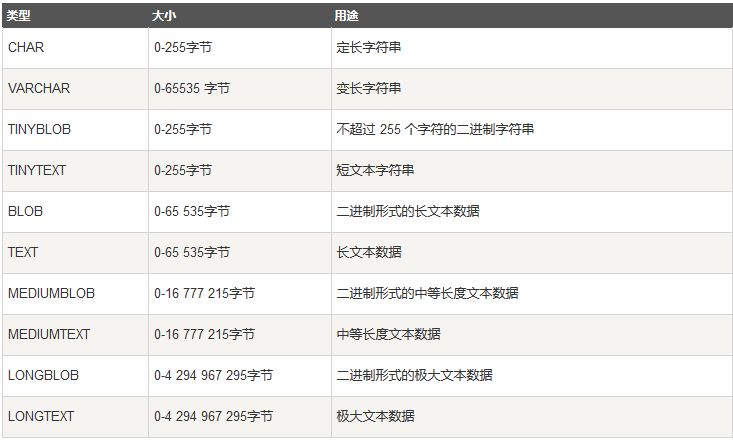
字符串应该知道的知识点:①blob类型,用来存放较大的二进制文件,比如图片②char(M)和varchar(M),里边的M值:表示能存到表格里的最大字符数③char和varchar的区别:char给的空间是固定的,varchar根据实际情况给存储的空间,char效率高,varchar效率低
-
MySQL常见的约束
- 约束:限制,限制我们表中的数据,保证添加到数据表中的数据准确和可靠性!凡是不符合约束的数据,插入时就会失败,插入不进去!
- 约束的分类:
①not null :非空约束,保证字段的值不能为空,比如学生信息表中的“学号”“姓名”等等这些是不能为空的!②default:默认约束,保证字段总会有值,即使没有插入值,都会有默认值!③primary key :主建约束,同时保证唯一性和非空④unique:唯一,保证唯一性但是可以为空,比如座位号⑤check:检查性约束【MySQL不支持,语法不报错,但无效】⑥foreign key:外键约束,用于限制两个表的关系,保证从表该字段的值必须来自于主表相关联的字段的值,不能无中生有!什么时候添加约束:①创建表的时候②修改表的时候
-
MySQL创建表时添加约束
- 列级约束
CREATE TABLE students( id INT PRIMARY KEY,#主建约束(唯一性,非空) s_name VARCHAR(10) NOT NULL, #非空 s_sex CHAR(1) CHECK(s_sex='男' OR s_sex='女'),#检查约束(Mysql无效) s_seat INT UNIQUE,#唯一约束 age INT DEFAULT 18, #默认约束 major_id INT REFERENCES majors(id) #这是外键,写在列级,Mysql无效 ) CREATE TABLE majors( id INT PRIMARY KEY, m_name VARCHAR(20) NOT NULL )
- 表级约束
CREATE TABLE students( id INT , s_name VARCHAR(10) , s_sex CHAR(1), s_seat INT, age INT , major_id INT , #这里下面有表级约束,要隔开,有逗号 CONSTRAINT pk PRIMARY KEY(id),#为id添加主建约束,pk是起的名,后面一样 CONSTRAINT uq UNIQUE(s_seat),#唯一性约束 CONSTRAINT ck CHECK(s_sex='男' OR s_sex='女'),#查询约束 CONSTRAINT fk_students_majors FOREIGN KEY(major_id) REFERENCES majors(id)#外键约束 );
总结一下表级约束的语法:【constraint 约束名字】 约束类型(字段名称) 【额外的东西,如外键】一般情况下MySQL的约束:主建,非空,唯一性,默认等这些写在列级外键约束写在表级!
-
MySQL主键和唯一两个约束的区别和外键的特点
-
主键和唯一性的区别:①主键约束: 同时保证唯一和非空在同一个表中主键只能有一个在同一个表中可以将多个字段组合成一个主键(不推荐)如:CONSTRAINT pk PRIMARY KEY(id,s_name),id和s_name组合起来成表的一个主键②唯一约束: 保证唯一但可以为空在同一个表中唯一约束可有很多个在同一个表中可以将多个字段组合成一个唯一约束(不推荐)外键的特点:①要求在从表上设置外键约束②从表上的列和主表上的对应的关联列的数据类型必须一致,含义意义一致③主表上的关联列必须是一个key(一般是主键,很少时候也可以是唯一键)④插入数据时,先插入主表,在插入从表;删除的时候,要先删除从表记录,在删除主表的记录
-
MySQL修改表时添加和删除约束
- 修改表时添加和删除约束:
①非空约束 alter table students modify column s_name varchar(20) not null; #添加 alter table students modify column s_name varchar(20) ; #删除 ②添加默认约束 alter table students modify column age int default 18; #添加 alter table students modify column age;#删除 ③添加主键 alter table students modify column id int primary key; #添加 alter table students modify column id int;#删除不掉的 alter table students drop primary key;#删除 ④添加唯一键 alter table students modify column seat int unique; #添加 alter table students drop index seat;#删除 show index from students;#查看唯一约束 ⑤外键 alter table students add foreign key(major_id) references majors(id); #添加 alter table students drop foreign key fk_students_majors;#删除
-
MySQL标识列
- 标识列:有叫自增长列,可以不用插入值,MySQL自动提供默认的序列值.
创建表的时候添加自增长列: create table t_identity( id int primary key auto_identity, name varchar(20) ); 有了自增长列,我们添加数据记录就可以: insert into t_identity values(null,'张三'); insert into t_identity values(null,'李四'); insert into t_identity values(null,'王麻子'); insert into t_identity(name) values ('张三'); insert into t_identity(name) values ('李四'); insert into t_identity(name) values ('王麻子');总结:①自增长列必须和键(一般是主键)搭配②一个表中有且只能有一个自增长列③自增长列的类型只能是数值型,一般情况用int④自增长列可以设置步长(set auto_increment_increment=3;),也可以手动插入一个数值改变起始值修改表的时候添加自增长: alter table t_indentity modify column id int primary key auto_increment; 删除自增长: alter table t_indentity modify column id int;
-
MySQL事务介绍
- TCL:Transaction Control Language,事务控制语言
- 事务:在MySQL数据库中表示一条或多条Sql语句组合在一起的一个执行单元.这个执行单元要么全部执行,要么全部不执行,否则就会出现逻辑错误!
比如银行里的转账这个事情:A账号余额:1000B账号余额:1000现在A转500元给B,那么要完成这个转账的事务,数据中的SQL应该是这样的执行过程:①A账号上要减少500元update 储蓄表 set A.余额=A.余额-500 where 账号名='A';②B账号上要增加500元update 储蓄表 set B.余额=B.余额+500 where 账号名='B';如果没有事务处理这个功能,上面的情况下,很可能会发生这样的情况:①执行成功 A的余额变为:500刚开始执行②的时候,突然出现某系统系统错误,导致②执行失败!①√②×:A的钱减少了,B的钱没增加!所以在类似的场景需求中我们需要事务处理:实现将①和②的SQL语句绑定在一起,要么都执行成功,没的事! 要么不管是①执行出错还是②执行出错,数据库里的数据状态会回滚到没有执行任何①或②里的SQL语句之前!
- MySQL数据库中的存储引擎:
①什么是存储引擎:在mysql中的数据是用各种不同的技术来存储在磁盘文件(或内存)当中的,这种具体的存储技术就是我们说的存储引擎.②我们可以通过show engines;命令来查看mysql支持的存储引擎.③在mysql可以选择的这些存储引擎中,innodb,myisam,memory这个三个是最常用的,但是其中只有innodb支持事务处理,而其他是不支持事务处理的.
-
事务的ACID特点:①原子性(Atomicity):组成事务的SQL语句不可在分,要么都执行,要么都不执行.②一致性(Consistency):事务必须让数据的数据状态变化到另一个一致性的状态,比如:刚刚的例子中A和B的余额总和是2000,转账后,A和B的余额总和不能变.前后具有一致性.③隔离性(Isolation):一个事务的执行,不受其他事务的干扰,相互应该是隔离的,但是实际上是很难做到的,要通过隔离级别做选择!④持久性(Durability):一个事务被提交,并成功执行,那么它对数据的修改就是永久性的.接下来的其他操作或出现的故障,不能影响到它执行的结果!
-
MySQL的事务处理
- MySQL的事务的创建:
①隐视事务:事务没有明显的开始和结束的标记.这时候像insert语句,update语句和delete语句,每一条SQL语句就默认是一个事务.显然,隐视事务在类似转账的逻辑业务需求的时候,就无法处理了!②显示事务:说白了,这个事务模式,就要我们中程序中手动的用命令来开启事务,和结束事务,并让事务里的多条SQL语句去执行.注意:默认MySQL是开启自动提交事务的,用show variables like 'autocommit';命令可以查看到. 所以开启显示事务前,要关掉它,用set autocommit=0;只对本身会话有效.①:开始事务set autocommit=0;start transaction; #可选的,执行set autocommit=0已经默认开启了!②:编写事务中的SQL语句(主要是:select update delete insert等语句)语句1;语句2;........③:结束事务commit;提交事务去真正执行rollback;回滚事务,恢复数据库执行前的状态!
- 案例演示:
DROP TABLE IF EXISTS account; CREATE TABLE account( id INT PRIMARY KEY AUTO_INCREMENT, username VARCHAR(20), balance DOUBLE ); INSERT INTO account(username,balance) VALUES('A',1000),('B',1000); SET autocommit = 0;#开启事务 START TRANSACTION; #编写sql语句 UPDATE account SET balance=balance-500 WHERE username='A'; UPDATE account SET balance=balance+500 WHERE username='B'; #结束事务 #commit; ROLLBACK;
-
MySQL事务并发问题
- 当有多个事务同时访问数据库中的同一个数据时,如果没有采取必要的隔离机制,就会导致各种并发错误发生:
两个事务t1,t2:①脏读: 当t2正在更新某个字段但还没有提交数据库执行时,t1在这个时刻正好读取这个字段的数据,然后t2发生错误,然后回滚数据,导致t1读取到数据就是t2更新时的临时数据,而且最终没有更新成功的无效数据!②不可重复读:t1读取一个字段是数值,然后t2更新了这个字段,之后t1在读取同一个字段,值发生了变化!③幻读:t1读取一个字段是数值,然后t2对这个字段插入新数值,t1在读突然就多了几行数据.
- 数据库事务的隔离性:数据库必须具有隔离这种并发运行的事务的能力,避免这些个错误现象!一个事务与其他事务隔离的程度称为隔离级别:数据库规定了事务隔离级别,不同隔离级别对应不同的干扰程度,级别越高,数据一致性越好,但并发性越弱!
-
MySQL数据库支持四个不同隔离级别,这四个由底到高的级别是:read uncommitted; 读未提交数据read commited; 读已提交数据repeatable read; 可重复读(默认)serialable; 串行化第一个级别:脏读、不可重复读、幻读第二级别: 脏读没有了,但不可重复读和幻读仍然有!第三级别:没有脏读,没有不可重复读,仍然有幻读!第四个级别:可以解决所有问题! 会使性能十分低下!
-
MySQL设置回滚点
- 主要是关键字:savepoint
SET autocommit = 0;#开启事务 START TRANSACTION; #编写sql语句 DELETE FROM account WHERE id=1; SAVEPOINT a; #设置保存点 DELETE FROM account WHERE id=2; #结束事务 #commit; ROLLBACK TO a; #回滚到保存点
-
MySQL存储过程的介绍和无参数存储过程演示
- 存储过程:预先编辑好SQL语句的集合,这个集合完成了某项具体的功能集合,需要这个功能的时候,只要调用这个过程就好了!(大型的项目才玩这个,中小项目不会用到的!动不动就要插入或者更新上万条记录,用这个才能体现出效率!)
- 创建语法:
create procedure 存储过程的名字(参数列表)begin存储过程体(SQL语句的集合);end注意:①参数列表包含三个部分:参数模式 参数名 参数类型(比如: in s_name varchar(20) )参数模式:in : 该参数可以作为输入,需要调用方传入值来给存储过程out : 该参数可以作为输出,该参数可以作为返回值给调用方inout : 该参数既可以做输入,也可以作为输出②如果存储体只要一句SQL语句,begin和end可以省略,存储体里的slq语句结尾处必须加分号,避免数据库误判为存储过程的结束标记,所以需要我们自定义命令的结尾符号:delimiter 结尾标记 比如:delimiter $
- 存储过程的调用:call 存储过程名(参数列表);
- 无参数存储过程:
delimiter $ create procedure myp1() begin insert into ages(id,`age`) values (11,'12'); insert into ages(id,`age`) values (21,'13'); insert into ages(id,`age`) values (31,'14'); insert into ages(id,`age`) values (41,'15'); end $ call myp1()
-
in参数模式的存储过程
- 带in参数模式的存储过程:
案例:通过学生名查询对应的年龄 delimiter $ create procedure myp2(in s_name varchar(10)) begin select s.name, a.age from students s inner join ages a on s.age_id = g.id where s.name=s_name; end $ 调用:call myp2('任波涛')
案例:创建判断用户是否登录成功delimiter $create procedure myp3(in username varchar(20),in password varchar(20))begindeclare res int defaut 0; #定义一个字段串类型变量select count(*) into res from users u #将查询结果赋值给变量where u.username=usernameand u.password=password;select if(res>0,'登录成功','登录失败'); # 打印结果end $调用:call myp3('admin','admin')
-
out参数模式的存储过程
- out参数模式的存储过程:
案例:根据学生姓名,返回对应的年龄 create procedure myp4(in sname varchar(10),out age int) begin select a.age into age from students s inner join ages a on s.age_id = a.id where s.sname=sname; end $ 调用: call myp4('任波涛',@age) #把值取出来放到变量里去 select @age $ #查看值了
案例:案例:根据学生姓名,返回对应的年龄和学生编号create procedure myp5(in sname varchar(10),out age int,out sid int)beginselect a.age ,s.id into age,sidfrom students sinner join ages aon s.age_id = a.idwhere s.sname=sname;end $调用:call('任波涛',@age,@sid)select @age,@sid $
-
inout参数模式存储过程和删除查看存储过程
- inout参数模式存储过程和删除查看存储过程:
案例:传入a和b两个数,然后让a和b都乘以2后返回 create procedure myp7(inout a int , inout b int) begin set a=a*2; set b=b*2; end $ 调用: set @a=10set @b=20$ call myp5(@a,@b) select @a,@b 删除存储过程: drop procedure 存储过程名; drop procedure myp1; #每次只能删除一个 查看存储过程的信息: show create procedure 存储名;