对Ayoosh Kathuria的YOLOv3实现进行翻译和总结,原文链接如下:
https://blog.paperspace.com/how-to-implement-a-yolo-object-detector-in-pytorch/
*首先翻译遵循不删不改的原则有一说一,对容易起到歧义的中文采取保留英文的方式。其中对原文没有删减但是略有扩充,其中某些阐释是我一句话的总结,如有错误请大家在留言区指出扶正。
这是从头开始构建YOLO v3检测器的教程,详细说明了如何从配置文件创建网络体系结构、加载权重和设计输入/输出。
目标检测(object detection)是一个因近年来深度学习的发展而受益颇多的领域,近年来,人们开发了多种目标检测算法,其中包括YOLO、SSD、Mask-RCNN和RetinaNet。
在过去的几个月里,我(Ayoosh Kathuria)一直在一个实验室致力于改进目标检测。从这次经历中得到的最大收获就是认识到学习目标检测的最佳方法是自己从头开始实现算法。这正是我们在本教程中要做的。
我们将会使用PyTorch并基于YOLO v3来实现一个目标检测器,这是一种速度更快的目标检测算法。
本教程的代码在Python 3.5和PyTorch 0.4上运行。在这个Github repo中可以完整地找到它。
本教程分为5个部分:
Part 1 (This one): Understanding How YOLO works
Part 2 : Creating the layers of the network architecture
Part 3 : Implementing the forward pass of the network
Part 4 : Objectness score thresholding and Non-maximum suppression
Part 5 : Designing the input and the output pipelines
1.先决条件
- 你应该了解卷积神经网络是如何工作的。这还包括残差模块、跳远连接和上采样的知识。(Residual Blocks, skip connections可以从ResNet学习, Upsampling是图像插值扩大运算,可以理解为在最后的网络层中等比例扩大经过前面卷积缩小后的图片,得到和原图一样大的图像)
- 什么是目标检测,边框回归,IoU和非极大值抑制。(bounding box regression是指将本来预测的边框通过平移和放缩来微调,也就是把本来的(x,y,h,w)经过变换得到新的坐标输出。IoU是预测框和标记框的交集。non-maximum suppression是:先假设有6个矩形框,根据分类器的类别分类概率做排序,假设从小到大属于车辆的概率 分别为A、B、C、D、E、F。(1)从最大概率矩形框F开始,分别判断A~E与F的重叠度IOU是否大于某个设定的阈值;(2)假设B、D与F的重叠度超过阈值,那么就扔掉B、D;并标记第一个矩形框F,是我们保留下来的。(3)从剩下的矩形框A、C、E中,选择概率最大的E,然后判断E与A、C的重叠度,重叠度大于一定的阈值,那么就扔掉;并标记E是我们保留下来的第二个矩形框。就这样一直重复,找到所有被保留下来的矩形框。)
- 基本的PyTorch用法。你应该能够轻松地创建简单的神经网络。
2.什么是YOLO?
YOLO源于Redmon J , Divvala S , Girshick R , et al. You Only Look Once: Unified, Real-Time Object Detection[J]. 2015.它是一种利用深度卷积神经网络学习到的特征来检测物体的目标检测器。在我们开始构建代码之前,我们必须了解YOLO是如何工作的。
如有兴趣可以参考Andrew Ng的公开课,在CNN中他对YOLO有了初步的讲解,本人也是因吴恩达老师才了解到YOLO。
3.A Fully Convolutional Neural Network
一句话介绍FCN就是不含全连接层的CNN,也就是说直接在像素层面对卷积层进行操作,不再对其参数进行一维展开。
YOLO只使用卷积层,使其成为完全卷积网络(FCN)。它有75个卷积层,有跳远连接和上采样层。不使用任何形式的池化层,使用步长为2的卷积层来对特征映射进行降采样(downsampling说白了就是因为(n-f)/s + 1因为步长s是2所以缩小了图像,因为使用了若干个downsampling原图像就会缩小2的n次方倍,所以最后对应了一个upsampling把缩小的图片通过卷积扩大为原来的大小)。这有助于防止通常因为使用池化层造成的低层面特征的丢失(很好理解,不管是最大池化还是平均池化都会把filter大小内的多个特征丢弃只剩1个)。
因为基于FCN的思想,YOLO对输入图像的大小是恒定不变的(上一段说了先数个downsampling然后一个upsampling,说白了就是先依次缩小数倍最后再扩大回去)。然而,在实际应用中,我们可能希望保持恒定的输入大小来应付不同的问题。(输入标准化,用过深度学习框架的都知道)
其中一个大问题是,如果我们想成批处理我们的图像(成批的图像可以由GPU并行处理,从而提高速度),我们需要有固定高度和宽度的图像。这需要将多个图像连接成一个大批量(将多个PyTorch张量连接成一个张量)。这句话不知道意思的可以去了解一下pytorch在处理图像时用的torchvision是怎么加载图像划分baby batch的,先导知识是关于mini batch梯度下降法加速训练的理论。
网络通过使用步长stride的方式来对图片进行降采样,例如,如果网络的步幅是32,那么大小为416x416的输入图像将产生大小为13x13的输出。(说白了就是卷积(n-f)/ s + 1)
Generally, stride of any layer in the network is equal to the factor by which the output of the layer is smaller than the input image to the network.
直译过来就是网络中任何层的步幅等于该层的输出且小于输入图像的大小。这一句先做保留,因为根据我对神经网络的经验有些CNN的stride是2的次方,有些是人为指定的步长,还有一些是从经典网络迁移过来的卷积层步长参数,所以步长到底多少在我看来是不一定的。
4.Interpreting the output
下面来对输出进行解释。
典型地来说,对于所有目标检测器都存在这种情况,通过卷积层学习到的特征会被传递进入分类器/回归器来预测一种检测,包括bounding box的坐标,类标等等。
在YOLO中,通过使用1 x 1的卷积来完成预测,前面说了因为不用全连接层展开维数,经过若干次卷积后得到的图片必然是n x n x c,也就是说有很多个channel的,1x1xA的卷积可以改变channel的数量,起到降维的效果,假设A=1则我们可以把输出变成n x n的图像。
现在,首先注意到我们的输出是一个特征图(即通过卷积层提取到特征构成的图)。既然我们使用了1 x 1卷积,预测图的大小就正好是之前特征图的大小。(把多通道高维特征压缩到平面来预测)。在YOLO v3(及其后续)中,解释此预测图的方式是每个细胞单元格可以预测固定数量的边界框。(假设原图像1080x1080,最后压缩在64x64的预测图中,那么每一个1x1的格子都可以对边界框给出一个预测)
尽管技术上来说正确的描述每一个细胞单元格的名称是神经元,称其为细胞会使我们的上下文更容易理解。
在深度层面上,特征图有Bx(5+C)个条目,B表示每个细胞单元格可以预测的边界框的数量,根据论文,每个B都可以对应检测一个特定对象,比如B1的5+C个特征来预测车辆,B2的5+C个特征来预测行人。每个边界框都有5+C个属性,这里我不用晦涩的原文了,一句话解释一下5+C属性的意思,5就是(p、x、y、h、w),p是置信度在0到1之间如果大于某个阈值那么就认为此时可以框出待检测物体,然后xyhw是中心坐标xy和框的长宽hw,C的意思是如果此时B有两个分别检测人和车,那么C就表示人和车的独热编码,可以是一个数字0或1,也可以是两个01,10,11,以此类推多个物体检测。当然在实际预测中才用了多个数字来表示不同物体的时候,通常每一个数字也是0到1之间的置信度。YOLO v3会为每个单元格预测3个边界框。当然了实际问题实际分析,需要预测多少个类别的物体就设置多少个边界框。
You expect each cell of the feature map to predict an object through one of it's bounding boxes if the center of the object falls in the receptive field of that cell. (Receptive field is the region of the input image visible to the cell. Refer to the link on convolutional neural networks for further clarification).
如果对象的中心落在该单元的接受域中,则可以期望特征图的每个单元通过其边界框之一来预测该对象。 (可感受视野是输入图像对细胞可见的区域。有关进一步的说明,请参见卷积神经网络上的链接)。就是说在置信度超过阈值后就认为其落在该cell上,然后启动数个box来分别预测xyhw+C。
这与YOLO的训练方式有关,其中只有一个边界框负责检测任何给定的对象。 首先,我们必须确定此边界框属于哪个单元格。为此,我们将输入图像划分为尺寸等于最终特征图尺寸的网格。
让我们考虑下面的示例,其中输入图像为416 x 416,网络的步幅为32。如前所述,特征图的尺寸为13 x13。然后将输入图像划分为13 x 13 细胞。
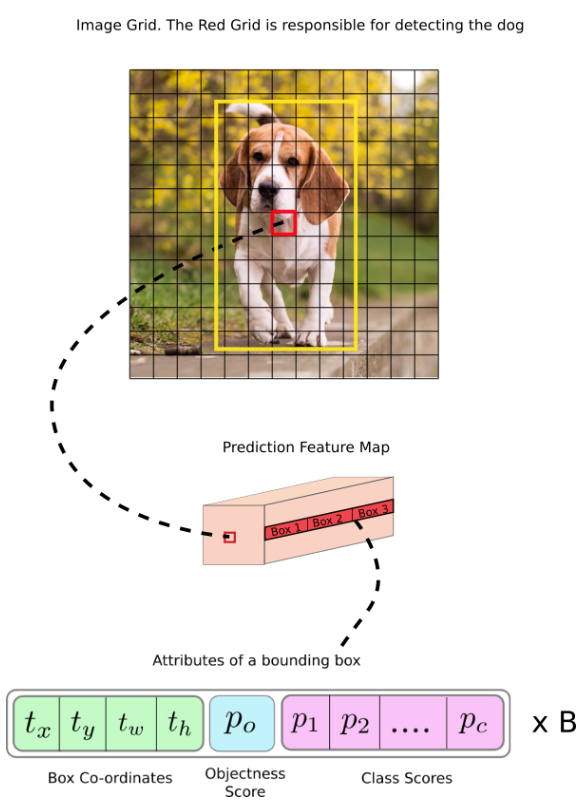
然后,在输入图像的细胞单元格上将包含对象真实中心的细胞单元格选中,来负责预测对象。在上图中,就是那个红色的cell,因为包含了真实对象(黄色)的中心,所以被选中来负责预测对象。
现在,红色单元格是网格图中第7行的第7个单元格。我们将特征图上第7行中的第7个单元格(特征图上的对应单元格)分配为负责检测狗的那个单元格。
现在,该单元格可以预测三个边界框。 哪一个将被分配来预测狗的真实标签? 为了理解这一点,我们必须围绕锚的概念展开思考。(引入Anchor boxes)
请注意,我们在此讨论的单元格是预测特征图上的单元格。 我们将输入图像划分为一个网格只是为了确定预测特征图的哪个单元负责预测。(很显然经过多层卷积和1x1卷积降维后的特征图的每个单元都包含了很多已经提取到的特征,所以需要在特征图上进行预测,上面例子的原图划分只是为了直观表示预测而已)
5.Anchor Boxes
预测边界框的宽度和高度可能很有意义,但是在实践中,这会导致训练过程中出现不稳定的变化。 取而代之的是,大多数现代目标检测器会预测对数空间转换,或者只是偏移到称为锚点的预定义默认边界框。
然后,将这些变换应用于锚盒以获得预测。 YOLO v3具有三个锚点,可在每个细胞单元格上预测三个边界框。
回到我们前面的问题,负责检测狗的边界框的锚点,是和真实框体具有最高交并比的框体。
6.Making Predictions
以下公式描述了如何转换网络输出以获得边界框预测。
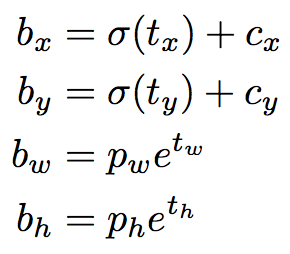
bx,by是我们预测边框的中心坐标,bw,bh是我们预测边框的宽度和高度。
tx,ty,tw,th是网络的输出值。
cx,cy是网格的左上角坐标。
pw,ph是锚盒的尺寸。
6.1 Center Coordinates
注意,我们通过sigmoid函数来预测中心坐标,这将会强制将值压缩在0到1之间,为何要这样呢?
通常,YOLO不会预测边界框中心的绝对坐标。 它预测的偏移量是:
- 相对于预测对象的细胞单元的左上角。
- 通过来自于特征图的细胞单元的维数来进行归一化,也就是1。
例如,考虑到我们上面狗的照片,如果预测的中心坐标为(0.4,0.7),那么这意味着实际中心坐标位于13x13特征图上的(6.4,6.7)。因为红色细胞单元格左上角的坐标为(6,6)。
但是,等等,如果预测的x,y坐标大于1,例如(1.2,0.7),会发生什么?这意味着中心位于(7.2,6.7)。 请注意,中心现在位于的单元格,恰好在我们的红色单元格的右边,也就是第7行的第8个单元格中。 这打破了YOLO的理论,因为如果我们假设红框负责预测这只狗,那么该狗的中心必须位于红色细胞单元格中,而不是位于其旁边的那个细胞单元格中。
因此,为解决此问题,通过sigmoid函数输出,该函数将输出压缩在0到1的范围内,从而有效地将中心保持在所预测的网格中。
6.2 Dimensions of the Bounding Box
通过对输出应用对数空间转换,然后与锚点相乘,可以预测边界框的尺寸。
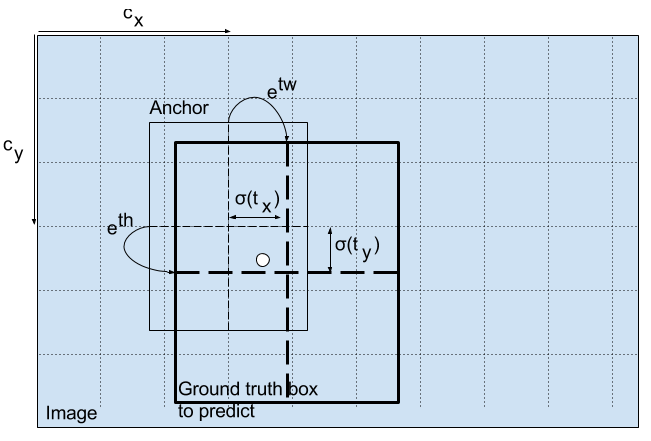
How the detector output is transformed to give the final prediction. Image Credits. http://christopher5106.github.io/
bw和bh作为组合的预测,由图像的高度和宽度进行标准化。(以这种方式选择训练标签)。因此,如果对包含狗的盒子的预测值,bx和by为(0.3,0.8),则13 x 13特征图上的实际宽度和高度为(13 x 0.3,13 x 0.8)。
6.3 Objectness Score
对象分数表示目标被包含在边界框中的概率。红色和相邻的网格应该接近1,而角落的网格应该接近0。
对象分数也将通过sigmoid函数传递,因为它将被解释为概率。
6.4 Class Confidences
类别置信度表示检测到的对象属于特定类别(狗,猫,香蕉,汽车等)的概率。 在v3版本之前,YOLO曾使用softmax来评分。
但是,该设计已在v3中删除,作者选择使用Sigmoid代替。 原因是Softmaxing类别分数假定这些类是互斥的。 用简单的话说,如果一个对象属于一个类,那么可以保证它不能属于另一个类。 这对于我们基于COCO数据库的检测器是正确的。
但是,当我们有类似于“女人”和“人”这样的类别时,这种假设可能不成立。 这就是作者避免使用Softmax激活的原因。
6.5 Prediction across different scales
YOLO v3可以进行3种不同尺度的预测。 该检测层用于在三个不同大小的特征图上进行检测,分别具有步幅32、16、8。 这意味着,使用416 x 416的输入,我们将以13 x 13、26 x 26和52 x 52的尺度进行检测。
网络对输入图像进行下采样,直到第一检测层为止,在该检测层中,使用步幅为32的特征图层进行检测。此外,各层的上采样系数为2,并与具有相同特征图大小的先前图层的特征图连接。 现在在步幅为16的层上进行另一次检测。重复相同的上采样过程,并在步幅8的层上进行最终检测。
在每个尺度上,每个细胞单元格使用3个锚盒来预测3个边界框,所以使用的锚盒总数为9。(不同尺度的锚是不同的)

作者报告说,这有助于YOLO v3更好地检测小物体,这是YOLO早期版本的常见问题。 上采样可以帮助网络学习细粒度的功能,这些功能对于检测小物体很有帮助。
6.6 Output Processing
对于一个尺寸为416 x 416的图片, YOLO 会预测 ((52 x 52) + (26 x 26) + 13 x 13)) x 3 = 10647 个边框盒子。然而,在我们的例子中只有一个物体,一只狗。 我们如何将检测结果从10647减少到1?
6.6.1 Thresholding by Object Confidence
首先,我们根据盒子的目标得分对其进行过滤。通常,分数低于阈值的框将被忽略。
6.6.2 Non-maximum Suppression
NMS旨在解决同一图像的多次检测问题。 例如,红色细胞单元的所有3个边界框可能检测到一个框,或者相邻单元可以检测到同一对象。

7.Our Implementation
YOLO只能检测类别属于训练网络的训练数据集中已存在类的对象。 我们将使用检测器的官方权重文件。 这些权重是通过在COCO数据集上训练网络获得的,因此我们可以检测80个对象类别。
这是第一部分。 这篇文章介绍了有关YOLO算法的足够知识,使您能够实现检测器。 但是,如果您想深入了解YOLO的工作原理,训练方式以及与其他检测器相比的性能,则可以阅读原始文章,下面提供了这些文章的链接。
这部分就是这样。 在下一部分中,我们将要实现组装检测器所需的各个层。