参考:https://blog.csdn.net/wxyangid/article/details/80209156
1.one-hot编码
中文名叫独热编码、一位有效编码。方法是使用N位状态寄存器来对N个状态进行编码,每个状态都有其独立的寄存器位,并且任意时刻,有且仅有一个状态位是有效的。比如,手写数字识别,数字为0-9共10个,那么每个数字的one-hot编码为10位,数字i的第i位为1,其余为0,如数字2的one-hot表示为:[0,0,1,0,0,0,0,0,0,0]。
1.2one-hot在提取文本特征上的应用
one-hot在特征提取上属于词袋模型(bags of words)
假设语料库有这么三段话:
我爱中国
爸爸妈妈爱我
爸爸妈妈爱中国
对语料库分词并进行编号
1我;2爱;3爸爸;4妈妈;5中国
对每段话用onehot提取特征向量
则三段话由onehot表示为:
我爱中国 -> 1,1,0,0,1
爸爸妈妈爱我 ->1,1,1,1,0
爸爸妈妈爱中国 ->0,1,1,1,1
优点:可以将数据用onehot进行离散化,在一定程度上起到了扩充特征的作用
缺点:没有考虑词与词之间的顺序,并且假设词与词之间相互独立,得到的特征是离散稀疏的(如果365天用onehot,就是365维,会很稀疏)
在实际的机器学习的应用任务中,特征有时候并不总是连续值,有可能是一些分类值,如性别可分为“male”和“female”。在机器学习任务中,对于这样的特征,通常我们需要对其进行特征数字化,如下面的例子:
有如下三个特征属性:
性别:["male","female"] # 所有可能取值,0,1 两种情况
地区:["Europe","US","Asia"] #0,1,2 三种情况
浏览器:["Firefox","Chrome","Safari","Internet Explorer"] #0,1,2,3四种情况
所以样本的第一维只能是0或者1,第二维是0,1,2三种情况中的一种,第三维,是0,1,2,3四种情况中的一种。
对于某一个样本,如["male","US","Internet Explorer"],我们需要将这个分类值的特征数字化,最直接的方法,我们可以采用序列化的方式:[0,1,3]。但是这样的特征处理并不能直接放入机器学习算法中。
对上述问题,我们发现性别2维,地区3维,浏览器4维则我们进行onehot编码需要9维。对["male","US","Internet Explorer"]进行onehot编码为:[1,0,0,1,0,0,0,0,1]
下面看如何用代码实现:
1 from sklearn import preprocessing 2 oh = preprocessing.OneHotEncoder() 3 oh.fit([[0,0,3],[1,1,0],[0,2,1],[1,0,2]])#四个样本 4 oh.transform([[0,1,3]]).toarray()
结果:[[ 1. 0. 0. 1. 0. 0. 0. 0. 1.]]
[0,0,3] #表示是该样本是,male Europe Internet Explorer
[1,1,0] #表示是 female,us Firefox
[0,2,1]#表示是 male Asia Chrome
[1,0,2] #表示是 female Europe Safari
word2vec
word2vec的两种重要模型:
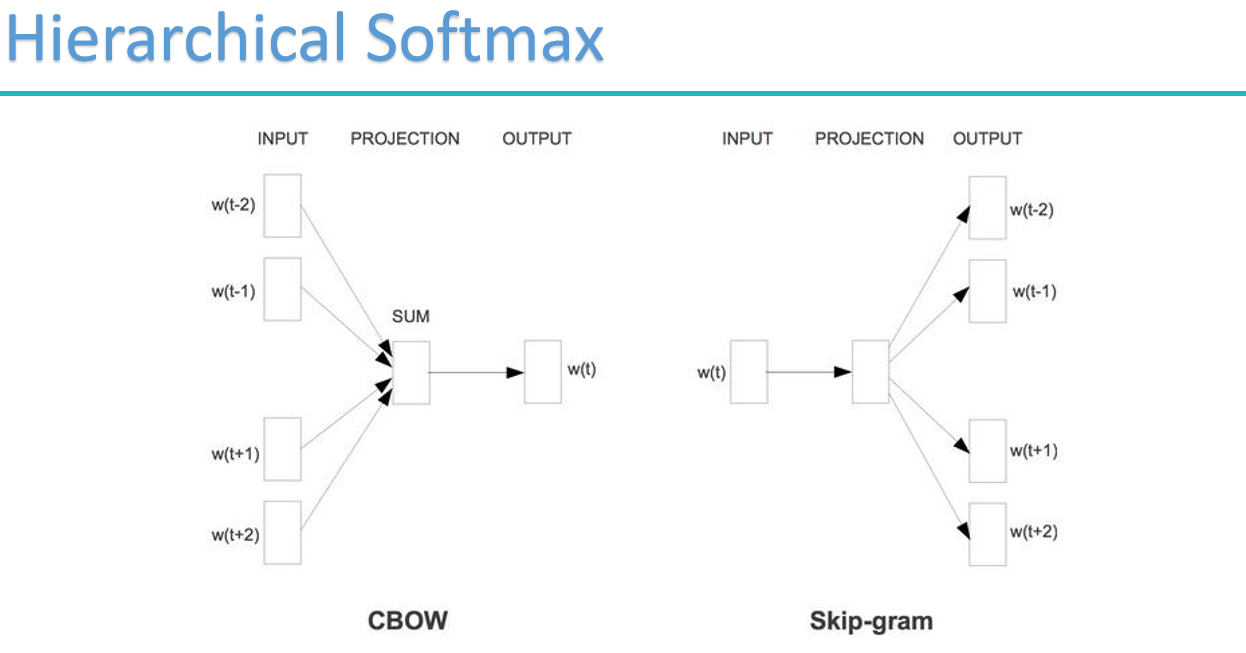






梯度计算



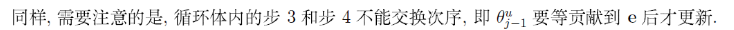




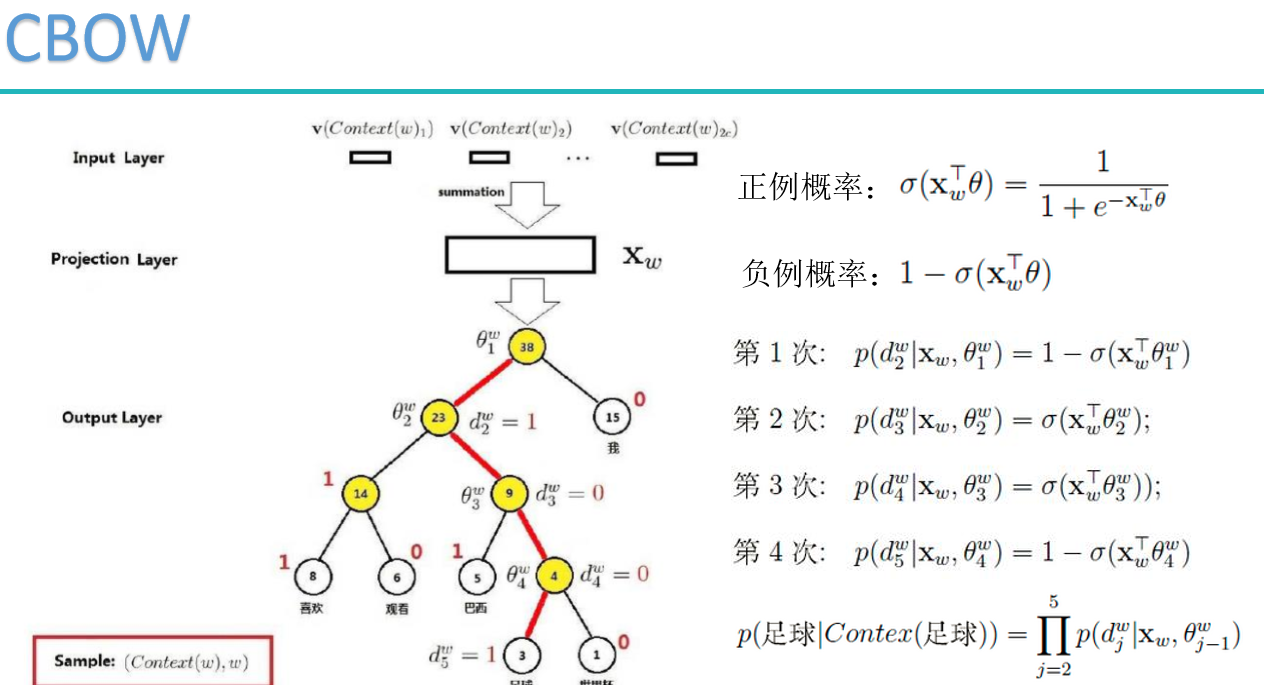
cbow:

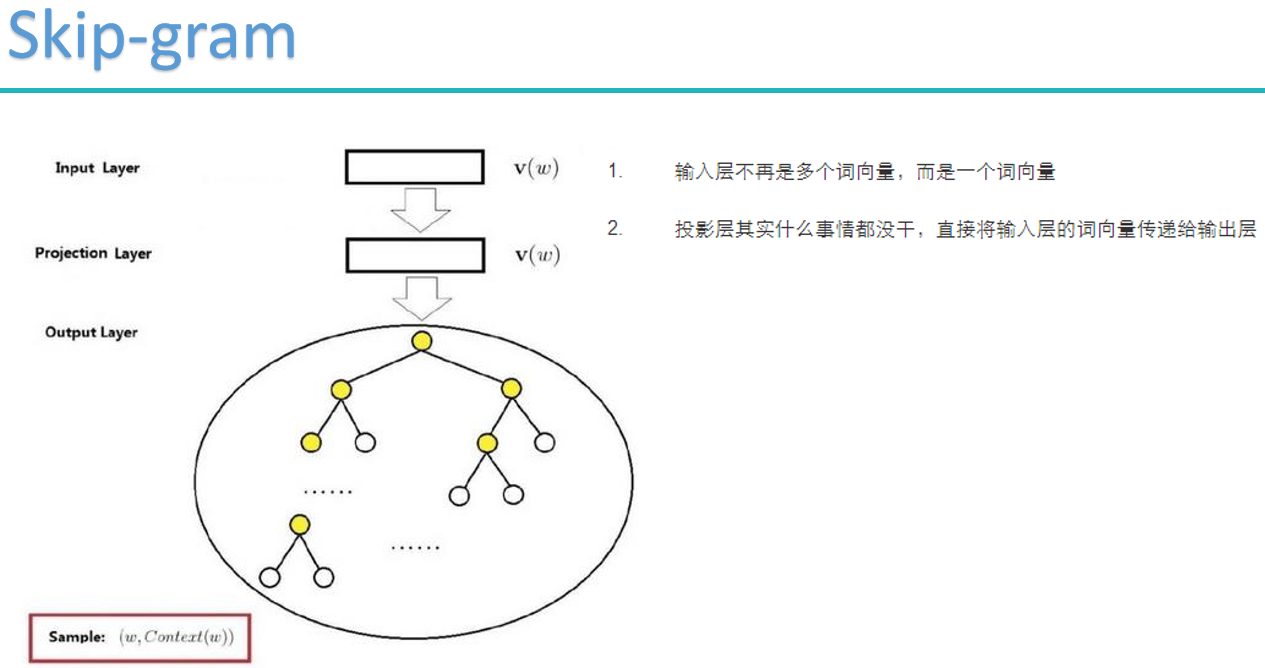
skip-gram



