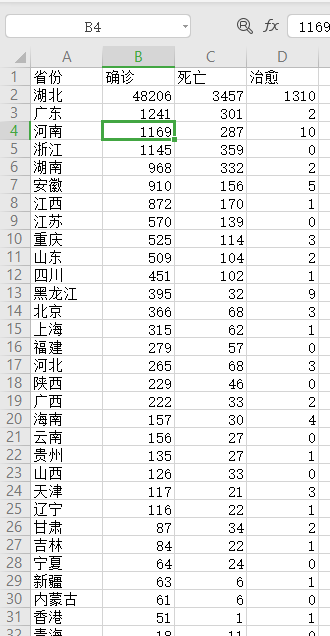
ExcelName = 'D:/2.13.csv'
links1=[]
links2=[]
links3=[]
links4=[]
selector=lxml.etree.HTML(html)
links1=selector.xpath('//*[@id="app2"]/div[1]/ul[2]/li/span[1]/text()')
links2=selector.xpath('//*[@id="app2"]/div[1]/ul[2]/li/span[2]/text()')
links3=selector.xpath('//*[@id="app2"]/div[1]/ul[2]/li/span[3]/text()')
links4=selector.xpath('//*[@id="app2"]/div[1]/ul[2]/li/span[4]/text()')
# for i in range(len(links1)):
# print(links1[i])
# print(links2[i])
# print(links3[i])
# print(links4[i])
with open(ExcelName, 'w', encoding='utf-8', newline='') as csvfile:
writer = csv.writer(csvfile)
writer.writerow(["省份","确诊","死亡","治愈",""])
for i in range(len(links1)):
with open(ExcelName, 'a', encoding='utf-8', newline='') as csvfile:
writer = csv.writer(csvfile)
writer.writerow([links1[i],links2[i],links3[i],links4[i]])
网址:http://health.people.com.cn/GB/26466/431463/431576/index.html
效果: