1.深度神经网络

1.以往神经网络采用单或双隐层结构,虽然参照了生物上的神经元,但是从本质上来说还是数学,以函数嵌套形成。
2.通常使用的激活函数是连续可微(differentiable)的,sigmoid函数或者是右侧的,本质上是减少梯度的降低速度。
3.现在神经网络的层数在逐级增加,几千层的也比较常见。
4.机器学习普遍存在的问题就是过拟合,如果没有过拟合,那么就非常简单了。
2.为什么要使用深度的?

增加学习复杂度->增强学习能力:
①增加隐藏层数的节点,即增加模型宽度;
②增加隐藏层的层数,即增加模型深度。
事实上,增加模型层数比增加单元数更加有效。
同时,增加模型的复杂度也是增加过拟合的风险,增加训练的困难:
①对于过拟合,使用大数据训练
②对于训练,使用更好的设备
当在很多层里传播时,误差函数梯度会分散,很难去使用BP算法,因为BP算法是要求梯度的。
3.表示学习

以前的学习方法中,对于图片或者其他都有特征提取,特征是人为规定的,所以有特征工程,提取特征之后进行分类学习。
在深度学习中,特征提取是表示学习种自动进行的,就是输入图片直接出来结果,称为端到端的学习。
4.模型复杂度与数据
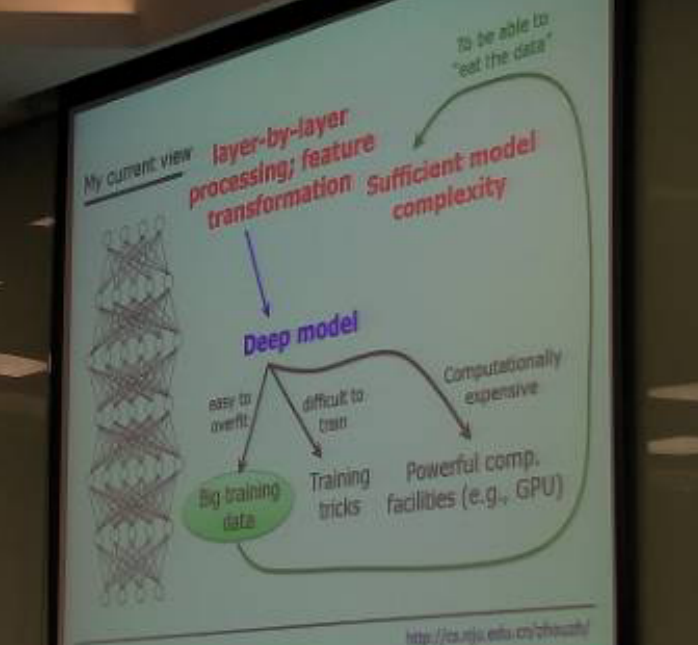
层到层的处理,特征转换,用到深度模型,深度模型又容易过拟合,难以训练,计算代价高。
所以针对上述三点:大数据,训练技巧,强有力的计算工具(GPU)。
那么对于上一点的大数据又eat big data,那么只能是足够的模型复杂度,对于线性模型来说,三千个数据和三千万个数据效果可能是一样的,所以就需要提高模型复杂度。
而复杂的模型就又回到了deep model上面。
5.对于深度模型重要的点

1.层到层的处理
2.特征转换
3.足够的模型复杂度
从应用角度来说,在视频图像语音之外的很多任务上,深度神经网络并非最佳选择,甚至表现不佳,比如在很多Kaggle上,随机森林后者XGBoost表表现更好。
最后周老师还提到,现在随机森林这个方面刚刚开始还是有许多问题可以研究的。
6.重新审视深度模型

1.目前的深度模型就是深度神经网络,深度学习也是指深度神经网络。
2.现在很多规律性质并非可微,通过可微构件建模最优。
3.机器学习中有很多不可微构建,无法通过BP训练。
所以目前寻找不需要梯度的算法来训练神经网络是需要的。
7.新探索

深度森林:
1.使用不可微的数模型,不通过BP训练。
2.超参数数目远少于DNN,易于训练
3.模型复杂度可以根据数目自定义确定,小数据也适用
4.在很多任务上性能接近或者超过DNN
8.关于深度森林

可微是模型的根本弱点;放弃BP。
新型深度学习模型,例如基于非可微构建的、非神经网络深度模型的探索,可望成为新兴研究方向
9.深度森林效果
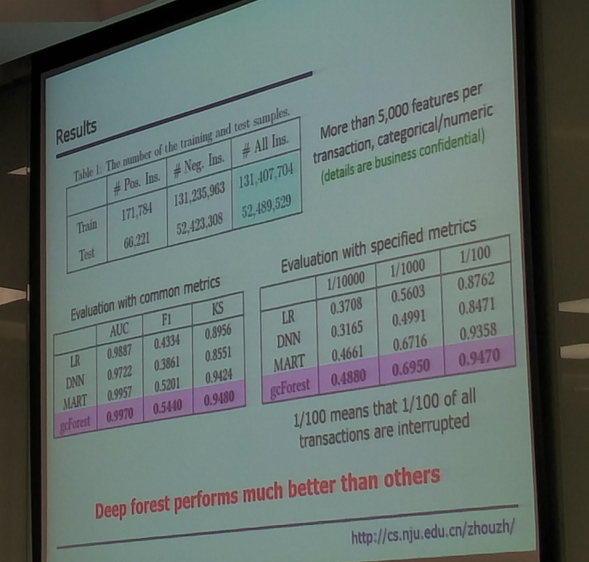
关于这个支付套现的系统设计,发现深度森林比其他更好。
10.思考1

打破垄断。如果有DNN替代方案,那么垄断消失。
11.弱监督学习缺点


监督信息不完全:半监督学习、主动学习;
监督信息不具体:多示例学习、MIML
监督信息不精确:带噪学习、众包学习...
12.openAI

关于游戏模拟的,只给出部分关卡,对于未知的关卡进行比赛。
多样激励模型能自己主动去寻找,好奇心模型。
13.老师的观点

对于开放环境学习:阿尔法勾是因为环境不变,也就是围棋规则不变,如果改变那是赢不了的。
现在还出现了薪工作,信息标注岗位。