Java进阶教程:HashMap实现原理
有一段时间没写博客了,现在连组织语言的能力都下降了...
关于HashMap
你必须要知道的
HashMap是我们开发中最常用的数据结构,功能强大,但是说句实话,却又是最陌生的,如果没有打开JDK拜读过他的代码,研究他的实现,甚是可惜。今天我们一起来研究一下HashMap。
当然如果只是面试需要的话,记住这三点也可以蒙混过关:
- HashMap线程不安全,HashTable(上古产物)是线程安全的,如果要保证线程安全可以用ConcurrentHashMap。
- HashMap内部维护一个Node数组(即键值对),当空间不够时,该数组会按1.5倍自动扩容。
- HashMap允许放入空值。
HashMap存储结构
最底层为数组
从结构实现来讲,HashMap是数组+链表+红黑树(JDK1.8新增)实现的,就像下面这样子
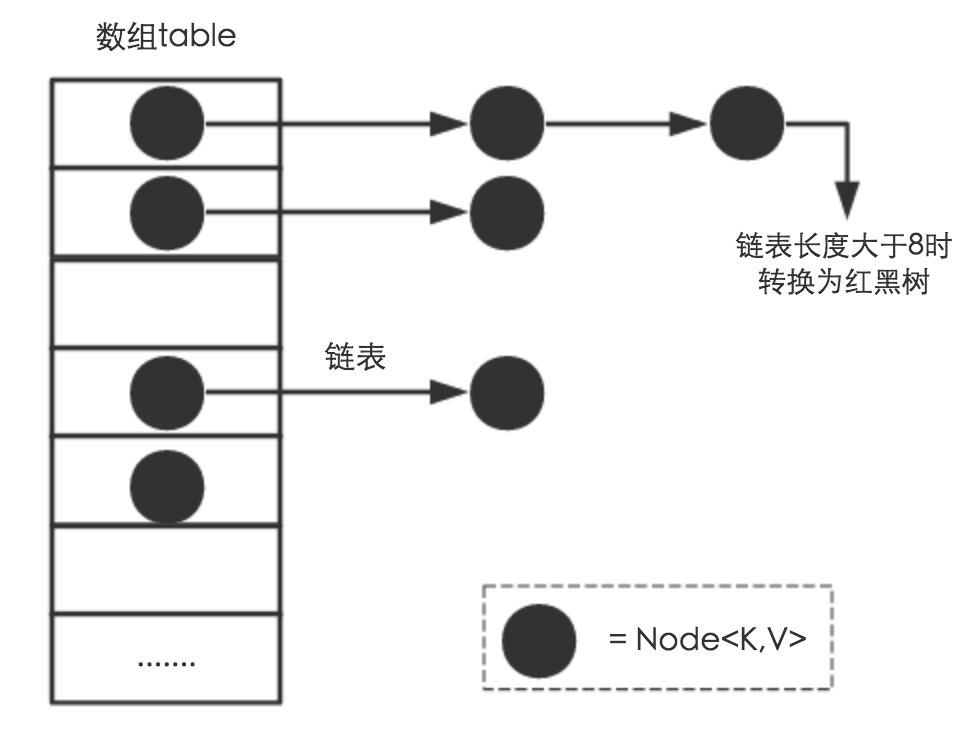
最底层呢是一个Node对象数组,它实现了Map.Entry接口,所以本质是一个键值对。
哈希散列
HashMap一个重要的概念是Hash。Java中的HashMap采用了链地址法。简单来说,就是数组加链表的结合。在每个数组元素上绑定一个链表,当数据被Hash后,得到数组下标,把数据放在对应下标元素的链表上。
Hash算法计算结果越分散均匀,Hash碰撞的概率就越小,Map的存取效率就会越高。
如果哈希桶数组很大,即使较差的Hash算法也会比较分散,如果哈希桶数组很小,就算最好的Hash算法也会出现较多碰撞。所以需要在空间成本和时间成本之间权衡,其实就是根据实际情况确定哈哈希桶数组的大小,并在此基础上设计好的Hash算法以减少Hash碰撞。通过什么方式来控制Map使得Hash碰撞的概率又小、哈希桶数组占用的空间又少呢?答案就是好的Hash算法和扩容机制。
参考资料
- 未完待续