1、爬取页面 http://www.quanshu.net/book/9/9055/
2、用到模块urllib(网页下载),re正则匹配取得title及titleurl,urlparse(拼接完整url),MySQLdb(导入MySQL) 数据库
3、for 循环遍历列表 取得盗墓笔记章节title 和 titleurl
4、try except 异常处理
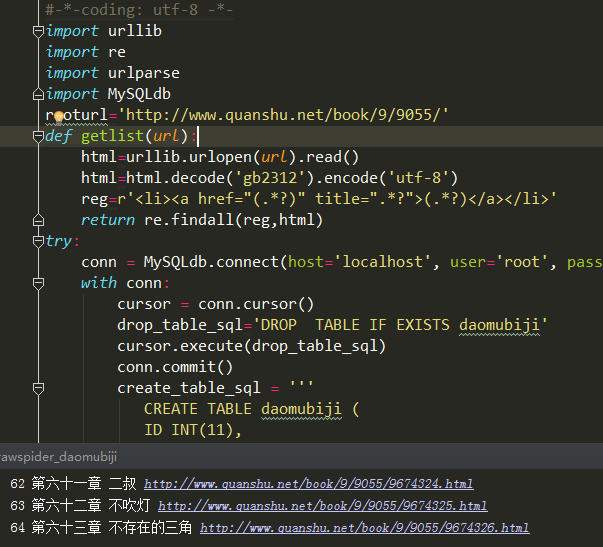
5、python 代码
#-*-coding: utf-8 -*-
import urllib
import re
import urlparse
import MySQLdb
rooturl='http://www.quanshu.net/book/9/9055/'
#getlist返回包含title 和titleurl的列表
def getlist(url):
html=urllib.urlopen(url).read()
html=html.decode('gb2312').encode('utf-8')
reg=r'<li><a href="(.*?)" title=".*?">(.*?)</a></li>'
return re.findall(reg,html)
try:
conn = MySQLdb.connect(host='localhost', user='root', passwd='Admin@', db='local_db', port=3306, charset='utf8')
with conn:
cursor = conn.cursor()
#如果存在daomubiji数据表先删除
drop_table_sql='DROP TABLE IF EXISTS daomubiji'
cursor.execute(drop_table_sql)
conn.commit()
#如果存在daomubiji数据表 先删除后接着创建daomubiji表
create_table_sql = '''
CREATE TABLE daomubiji (
ID INT(11),
title VARCHAR(255),
titleurl VARCHAR(255)
)ENGINE=INNODB DEFAULT CHARSET=utf8
'''
cursor.execute(create_table_sql)
conn.commit()
#下面调用getlist()函数获取rooturl下所有章节的titleurl 和title 组成的列表
urllist = getlist(rooturl)
#href属性取得的url不完整 仅取出了完整url的右半段 因此下面for循环变量名起名righturl
ID=0
#对列表进行遍历 取 titleurl 和title
for righturl in urllist:
title = righturl[1]
newurl = righturl[0]
#urlparse 模块的urlparse.urljoin方法将righturl 按照rooturl格式拼接成完整url
titleurl = urlparse.urljoin(rooturl, newurl)
ID+=1
print ID,title, titleurl
cursor.execute("INSERT INTO daomubiji values(%s,%s,%s)", (ID,title, titleurl))
conn.commit()
print "输入了"+ str(ID) +"条数据"
except MySQLdb.Error:
print "连接失败!"
代码执行情况:
6、MySQL数据库查询是否导入成功
SELECT * FROM daomubiji
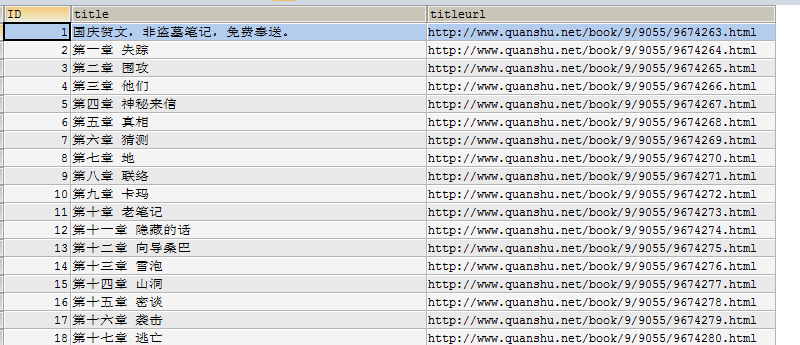
7、执行成功