解决大部分字符串问题的大杀器
给一下clj课件:戳我
SAM是一个博大精深的算法。虽然没有像网络流家族,Tarjan家族一样拉帮结派,但是自身包含很多方法。
一、前言
字符串常见问题:各种匹配
1.LCP
2.子串匹配
3.模式串和主串匹配
4.回文串?也算匹配吧。。。
经典例子:
给两个串,求最长公共子串长度。
用hash表+二分,可以做到nlogn
后缀自动机可以做到O(n)
二、概念
我们需要一个可以识别某个串是否为某个主串的子串、处理主串的子串信息、串和串之间进行匹配的问题。
朴素的做法是,对每个子串建立一个节点,然后连边,O(n^2)
考虑的优化是,发现一些子串会出现很多次,一些子串出现所有的出现位置的集合是同一个集合!
对这个进行优化
1.Right集合
对于某个串s,所有出现的位置的集合是:{r1,r2,...,rm}
那么,这个集合就是Right(s)
由于许多的串si,可能Right集合都是Right(s)
如果我们给定集合Right(t)
再给定属于这个集合的字符串的长度len
随便选择一个r,那么这个字符串就已经唯一确定了。
一个Right集合会包含若干个字符串
那么,其len的范围一定是一个区间[max,min]
那么,为了处理方便,我们会把这些串压缩在一起。
保留这个Right集合的max
我们就会定义Right(s)为一个“状态”
这个“状态”,包含了所有的可能匹配到的节点末尾的位置ri,以及可能已经匹配出来的字符串集合si
*性质:两个Right集合要么不相交,要么一个是另一个的真子集
证明:
首先易证,一个字符串属于且仅属于一个Right集合。
设两个集合s1,s2相交,r是交集的某个元素
那么对于一个属于s1的字符串string1
一个属于s2的字符串string2
由于两个字符串都可以以r作为末尾出现一次,由于一个字符串属于且仅属于一个集合
所以,string1!=string2
不妨设len(string1)=l1<len(string2)=l2
那么,显然地,string2出现的位置,string1必然也会出现。
所以,s2中有的元素ri,s1中必然也有
并且,必然存在一个元素r0,满足s1中有,但是s2中没有(否则s1,s2其实是一个集合)
那么s2就是s1的真子集。
证毕。
2.Parent树
发现,Right集合的两个性质非常给力。
真子集的包含关系可以看做父子关系
Right集合之间的不相交关系可以看做非祖宗关系。
图示:from clj
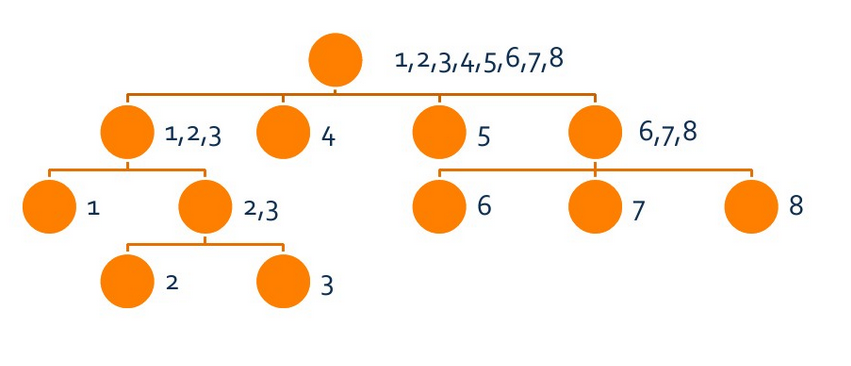
可以发现,对于集合字符串长度,有mx[fa[i]]+1=min[i]
进而可以这样理解:
father集合的结束位置更多,所以满足的字符串长度必然更短。
而且,有mx[fa[i]]+1=min[i]
叶子节点只有一个r
那么,如果从某个叶子节点往上找,那么所遍历的长度,就是以r结尾的所有子串。
三、SAM的构造
数组:(节点及$Right$集合,即所谓的“状态”)
$fa[i]$——节点$parent$树上的$father$
$ch[i][∑]$——节点的出边(类比$trie$树),指向添加字符$x$后到达的下一个节点($s[ri+1]==x$的会继续匹配上,这些$ri$就构成了目标的节点。如果没有,那么就指向$NULL$(实际不会操作,即$0$号节点就是$NULL$节点))。$∑$是字符集大小
$len[i]$——某个节点的所有字符串中最长的长度。
$nd$——当前匹配的最后一个节点$p$。若当前是$L$,则$Right(p)={L}$
$cnt$——节点个数。
我令$rt$节点为$1$
开始$nd=rt$
增量法构造,即每次插入一个字符$x$。设当前已经插入的字符串长度是$L$
我们要做的,就是新加入这个节点之后,维护好所有的后缀(使得后缀都能走出来)。
需要维护$fa$指针,和$ch[∑]$指针。
(以下祖先指$parent$树上的祖先)
建立一个$np$节点,其实有$Right(np)={L+1}$
赋值:$len[np]=L+1$
对于$p$的祖先,$p_1,p_2,...p_k$
存在一段$p_1,p_2,...p_{v-1}$
满足都没有$ch[*][x]$的边(也即都指向$NULL$)
对于$p_v$存在一个指向$x$的边
设$q=ch[p_v][x]$,
存在两种情况
$I$
$len[q]==len[p_v]+1$
那么意味着,之前所有的状态$q$代表的位置都可以加一个$x$匹配上将要加入的字符
那么可以直接把$q$当做$np$的$father$
(这个时候,其实$q$的$Right$集合发生了变化,已经加入了一个位置$L+1$)
就可以结束这次插入。
$II$
$len[q]>len[p_v]+1$
这是什么意思?
图示:(第一个串有一个B错了)
那么意味着,$q$抛弃了一些$p_v$的存在位置,并且使得长度增加了。
那么,$q$一定抛弃了以$L$结尾的位置。
否则,会存在一个离p更近的祖先,满足存在指向$x$的边。
所以,这样的$q$匹配上$x$之后,一定不会包含$L+1$位置。
那么,这个$q$,一定不能作为$np$的$father$(因为不包含$L+1$这个位置)
所以,我们新建一个节点$nq$
这个$nq$的$Right$集合,其实是:$Right(q)∪{L+1}$
我们还要对$nq$进行一些处理。
$fa[nq]=fa[q]$
$fa[q]=nq$
$fa[np]=nq$
$len[nq]=len[p_v]+1$
对于$nq$,所有$q$的出边,都是$nq$的出边
对于$ch[p_i][x]==q$的$p$的祖先(一定是连续一段),把出边$ch[p_i][x]$都设置为$nq$
(这里并不会存在这种情况:p的某个祖先$p'$
使得$len[ch[p'][x]]>len[p']+1$
因为,处理$q$的时候,就相当于在那个时候,加入一个$x$,$p'$会是当时的$p_v$
在那个时候会考虑到的。
)
然后就可以结束了。
代码:
luoguP3804 【模板】后缀自动机
(注意,点数是2倍)
#include<bits/stdc++.h> #define reg register int #define il inline #define numb (ch^'0') using namespace std; typedef long long ll; il void rd(int &x){ char ch;x=0;bool fl=false; while(!isdigit(ch=getchar()))(ch=='-')&&(fl=true); for(x=numb;isdigit(ch=getchar());x=x*10+numb); (fl==true)&&(x=-x); } namespace Miracle{ const int N=3e6+6; int n,m; ll ans; char s[N]; struct SAM{ int ch[N][30],cnt; int fa[N],nd;int sz[N]; int hd[N],tot; int len[N]; struct node{ int nxt,to; }e[2*N]; void init(){nd=1;cnt=1;} void add(int x,int y){ e[++tot].nxt=hd[x]; e[tot].to=y; hd[x]=tot; } void ins(int c,int pos){ int p=nd;sz[nd=++cnt]=1; len[nd]=pos; for(;p&&ch[p][c]==0;p=fa[p]) ch[p][c]=nd; if(p==0) {fa[nd]=1;return;} int q=ch[p][c]; if(len[q]==len[p]+1){fa[nd]=q;return;} len[++cnt]=len[p]+1; for(reg i=1;i<=26;++i) ch[cnt][i]=ch[q][i]; fa[cnt]=fa[q];fa[q]=cnt;fa[nd]=cnt; for(;p&&ch[p][c]==q;p=fa[p]) ch[p][c]=cnt; } void build(){ for(reg i=2;i<=cnt;++i) add(fa[i],i); } void dfs(int x){ for(reg i=hd[x];i;i=e[i].nxt){ dfs(e[i].to);sz[x]+=sz[e[i].to]; } if(sz[x]!=1) ans=max(ans,(ll)sz[x]*len[x]); } }sam; int main(){ scanf("%s",s+1); n=strlen(s+1);sam.init(); for(reg i=1;i<=n;++i) sam.ins(s[i]-'a'+1,i); sam.build();sam.dfs(1); printf("%lld",ans);return 0; } } int main(){ Miracle::main(); return 0; } /* Author: *Miracle* Date: 2018/11/16 21:54:31 */
四、构造正确性证明(理解)
其实就是实时维护好fa,len,ch[∑]
这样就可以保证Right集合,和Parent树的结构和定义。
观察步骤,我们可以保证,从某个状态出发,加一个字符,一定能走到新的字符串的集合的节点;
从某个状态出发,跳father,一定可以找到一个包含当前所有匹配位置的超集的集合。从而寻求更多的可能出边。
维护了所有的后缀,所以维护了所有的子串。
并且Parent指针类似于AC自动机的fail指针,转到了可能可以继续匹配的某个出现过的、更短的字符串。
跳一次Parent,匹配长度至少-1
所以,能失配后,快速利用保留信息,所以也可以支持匹配。
五、应用
1.匹配
SP1811 LCS - Longest Common Substring
暴力匹配。
对A建SAM。
B在上面跑。
如果可以匹配,那么就匹配。len++
否则,不断跳parent,直到有当前字符的出边。本质上是通过减少匹配长度,从而增加匹配位置,从而有机会进行匹配。
然后,len=max[new]+1
随时更新最长匹配长度,即答案。
B串的匹配情况,实际上类似于尺取法
A串放在SAM上,实际上是从多个位置一起尝试匹配。(因为某个点是一个集合)
2.Parent树
Parent树上DP size。
size相同的点选择最长的。
本质上考虑到了所有的子串,每个子串会在自己出现所有出现位置的Right处被考虑到。
利用Parent树处理出长度为某个长度的最大出现次数。
儿子的出现次数,缩短之后,必然可以作为father的出现次数。
所以,对于全局的数组,最后从后往前,ans[i]=max(ans[i],ans[i+1])处理即可
本质上,考虑Parent树上的每个节点,就相当于考虑到了每个状态,也就考虑到了每个字符串。
开始每个节点只保留最长的子串
最后倒序取max,就相当于考虑到了更小的子串。
化简式子之后,就是两两后缀LCP长度之和*2
后缀数组+单调栈/分治
在SA序列上考虑。直接+单调栈/分治即可
SAM+Parent树上DP
把原串反过来。后缀的最长公共前缀,就变成了前缀的最长公共后缀
两个前缀的最长公共后缀长度,即Parent树上LCA点的len长度。
所以,只要统计Parent树上,某个点是多少个叶子节点的LCA,然后乘上2*len即可。
直接树形DP即可处理。
正确性考虑每个前缀,显然和所有的前缀在LCA处正确统计了贡献。
(其实不建反串也没有问题,其实长度本质是对应的。虽然串本身有所不同)
 差异
差异3.第k大子串
循环同构
SAM或者最小表示法
SAM:
把串复制一倍加进去。
要选择一个长度为n的子串,使得字典序最小。
从起始位置随便走n步,一定不会停止。
从起始位置走n步的所有方案数,对应所有长度为n的子串。
每次贪心选择字典序最小的走即可。
(字符集比较大,用map存出边)
最小表示法:
开始,i=0,j=1,k=0
不断往后匹配,如果s[i+k]<s[j+k],那么,j=j+k+1,k=0
如果s[i+k]>s[j+k],那么,i=i+k+1,k=0
如果相同,++k
i,j跳的原因是,可以直接跳过一段不可能成为最优解开头的位置。
最后,因为i,j两个点之一一定保留了最优解。另一个超过了n
所以min(i,j)就是答案。

#include<bits/stdc++.h> #define reg register int #define il inline #define numb (ch^'0') using namespace std; typedef long long ll; il void rd(int &x){ char ch;x=0;bool fl=false; while(!isdigit(ch=getchar()))(ch=='-')&&(fl=true); for(x=numb;isdigit(ch=getchar());x=x*10+numb); (fl==true)&&(x=-x); } namespace Miracle{ const int N=300000+5; int s[2*N]; int n; int wrk(){ int i=0,j=1,k=0; while(i<n&&j<n&&k<n){ int t=s[(i+k)%n]-s[(j+k)%n]; if(t==0) ++k; else{ if(t<0) j+=k+1; else i+=k+1; if(i==j) ++j; k=0; } } return min(i,j); } int main(){ scanf("%d",&n); for(reg i=0;i<n;++i) scanf("%d",&s[i]),s[i+n]=s[i]; int st=wrk(); for(reg i=st;i<=st+n-1;++i) printf("%d ",s[i]); return 0; } } int main(){ Miracle::main(); return 0; } /* Author: *Miracle* Date: 2018/11/17 10:20:49 */
SP7258 SUBLEX - Lexicographical Substring Search
本质不同的第k大串
(后缀数组可以O(nlogn)解决)
(SAM)
DAG上,从起点出发的路径条数就是本质不同子串个数。
所以,如果走到一个状态节点,那么从这个节点出发的路径条数就是固定的。
把这些串接到之前走出来的串后面,就构成了一个完整子串。
所以,可以反向建图,topo+DP
就可以得到从某个点出发,往后走,走出来的本质不同子串个数了。
注意,可以在每个点停止一次。所以DP值还要特殊+1
然后,从起点开始走,选择可以走的出边即可。
走的时候,要减去每个点的1.如果是起始点,则不能减(因为认为空串不是一个串)
(当然,如果嫌每次枚举26条出边太慢,可以考虑每次进行二分,降低常数)
重复子串可以算多个的第K大。
区别就是,可以在每个点多“结束”几次。(原来是1次)
换句话说,可以创造出多个相同的字符串,接到原来的路径上。
这个次数,就是节点Right集合的大小。
Parent树dfs处理大小。
然后直接类似上面一个题走即可。
#include<bits/stdc++.h> #define il inline #define reg register int #define numb (ch^'0') using namespace std; typedef long long ll; namespace Miracle{ const int N=500000+5; int n,t; char s[N]; struct SAM{ int fa[2*N],len[2*N],sz[2*N],dp[2*N]; int ch[2*N][28]; int cnt,nd; int du[2*N]; struct node{ int nxt,to; }e[3*N],bian[2*N]; int hd[2*N],ee; int pre[2*N],bb; SAM(){ cnt=nd=1; } void upda(int x,int y){ bian[++bb].nxt=pre[x]; bian[bb].to=y; pre[x]=bb; } void add(int x,int y){ e[++ee].nxt=hd[x]; e[ee].to=y; hd[x]=ee; } void ins(int c,int pos){ int p=nd;len[nd=++cnt]=pos; sz[cnt]=1; for(;p&&ch[p][c]==0;p=fa[p]) ch[p][c]=cnt; if(p==0){ fa[cnt]=1;return; } int q=ch[p][c]; if(len[q]==len[p]+1){ fa[cnt]=q;return; } len[++cnt]=len[p]+1; for(reg i=1;i<=26;++i) ch[cnt][i]=ch[q][i]; fa[cnt]=fa[q];fa[q]=fa[nd]=cnt; for(;p&&ch[p][c]==q;p=fa[p]) ch[p][c]=cnt; } void tree(){ for(reg i=2;i<=cnt;++i) upda(fa[i],i); } void dfs(int x){ for(reg i=pre[x];i;i=bian[i].nxt){ int y=bian[i].to;dfs(y);sz[x]+=sz[y]; } } void DAG(){ for(reg i=1;i<=cnt;++i){ for(reg j=1;j<=26;++j){ if(ch[i][j]){ add(ch[i][j],i); ++du[i]; } } } } void topo(){ if(!t){ for(reg i=2;i<=cnt;++i)sz[i]=1; } sz[1]=0; queue<int>q; for(reg i=1;i<=cnt;++i){ if(du[i]==0) q.push(i); } while(!q.empty()){ int x=q.front();q.pop(); dp[x]+=sz[x]; for(reg i=hd[x];i;i=e[i].nxt){ int y=e[i].to; dp[y]+=dp[x]; du[y]--; if(du[y]==0) q.push(y); } } } void query(int k){ int now=1; //cout<<" dp "<<dp[now]<<endl; if(k>dp[now]) { printf("-1");return; } while(1){ //cout<<" jhaahah "<<now<<" "<<sz[now]<<endl; if(k<=sz[now]) break; k-=sz[now]; for(reg i=1;i<=26;++i){ if(ch[now][i]){ if(k>dp[ch[now][i]]) k-=dp[ch[now][i]]; else { putchar('a'+i-1); now=ch[now][i];break; } } } } } }sam; int main(){ scanf("%s",s+1); n=strlen(s+1); int k; scanf("%d%d",&t,&k); for(reg i=1;i<=n;++i){ sam.ins(s[i]-'a'+1,i); } if(t){ sam.tree(); sam.dfs(1); } sam.DAG(); sam.topo(); sam.query(k); return 0; } } int main(){ Miracle::main(); return 0; } /* Author: *Miracle* Date: 2018/11/18 9:06:05 */
4.与其他算法结合
二分+DP+单调队列+SAM
二分L
对于分段dp,可以直接列出式子:
dp[i]=max(dp[j]+i-j,dp[i-1]) (i-maxlen[i]<=j<=i-L)
其中,maxlen[i],表示,到了i位置,最长往前匹配的子串长度,使得这个子串是某个模板串的子串。
把模板串用'2'接起来,然后建SAM。跑出每个位置的maxlen
发现,maxlen[i]每次最多+1,i每次加1,所以,i-maxlen[i]单调不减。
单调队列优化即可。
判断dp[n]>=0.9*n即可。
O(nlogn)
本质不同O(n)个回文串,求出所有本质不同的回文串,然后找每个串的出现次数。
(SA+二分+manacher
每一个串,通过SA数组二分左右边界。然后出现次数就是(R-L+1)
SAM+倍增+manacher
每一个串,parent树上,从叶子开始,倍增找符合min[i]<=len<=max[i]的节点i。i的Right集合大小就是该回文串出现次数。
六、广义后缀自动机
多个主串匹配。
建造方法一般有两个:
法一:
把每个主串依次放进SAM
不同主串之间,强制使得从root开始构造。
法二:
对所有的主串依次插入建造出一个trie
trie上建SAM,可以dfs,或者bfs建。
只要记录树上x的father的SAM上的节点编号p,从这个p作为nd开始建即可。
点数O(2*总长度)
Parent树,DAG图,仍然可以使用。
Parent树,仍然可以统计size等等。Right集合size的意义,是后x个主串的某些子串的出现个数和。。。。(对于第i个串,x应该是n-i+1,,,n是主串个数)
利用Parent树,可以统计某些子串在所有串的分别出现次数(用size[p][i]统计),或者,可以判断一个字符串是否仅属于某个(某几个)模式串
发现:
画图发现,
如果对于多个主串,可能某些节点不能从根节点出发到达。那么,这样的节点的路径一定可以从其他的节点表示。
这样的节点其实不具备实际意义(一般不予统计答案,但是作为一个叶子,也就是信息的存储点,一定从树上要往上传信息。)
因为,一定有len[i]==len[fa[i]],否则,这个点就有了串,但是不能从根节点到达。(假装这么证是对的)
如果忽视这样的点,那么剩下的点的Right集合就有意义。
它一定代表着,这些串在所有的主串的所有出现位置的集合
所以,我们可以利用Parent树,处理某个、某些字符串在个个主串的出现情况。
(当然,如果广义SAM要处理Right集合的大小的话,要根据建造的方法处理
1.所有的串依次从rt=1开始插入
叶子sz赋值为1,然后Parent树上往上push。注意,不管节点是否有实际意义,都要push上去。因为代表一个出现的位置
2.trie树(其实这个就是把前缀合并在了一起,理论上更节省SAM的空间)
先要找到trie树某个点的sz[x],然后插入的时候sz就是这个sz[x]
)
例题:
P4081 [USACO17DEC]Standing Out from the Herd
建立广义SAM
每个叶子节点,保留所属主串的id
Parent树上DP,统计某个节点所代表的那些字符串对某个主串答案的贡献(显然同一个节点,最多为一个主串贡献答案)
当id只有一个的时候,ans[id[x]]+=len[id[x]]-len[fa[x]]
代码:
#include<bits/stdc++.h> #define reg register int #define il inline #define numb (ch^'0') using namespace std; typedef long long ll; il void rd(int &x){ char ch;x=0;bool fl=false; while(!isdigit(ch=getchar()))(ch=='-')&&(fl=true); for(x=numb;isdigit(ch=getchar());x=x*10+numb); (fl==true)&&(x=-x); } namespace Miracle{ const int N=1e5+5; int n,m; char s[N]; ll ans[N]; struct SAM{ int ch[2*N][27]; int nd,cnt; int len[2*N],fa[2*N]; int id[2*N]; SAM(){nd=cnt=1;} struct node{ int nxt,to; }e[2*N]; int hd[2*N],tot; void add(int x,int y){ e[++tot].nxt=hd[x]; e[tot].to=y; hd[x]=tot; } void ins(int c,int pos,int lp){ int p=nd;len[nd=++cnt]=pos; id[cnt]=lp; for(;p&&ch[p][c]==0;p=fa[p]) ch[p][c]=cnt; if(p==0){ fa[cnt]=1;return; } int q=ch[p][c]; if(len[q]==len[p]+1){ fa[cnt]=q;return; } len[++cnt]=len[p]+1; for(reg i=1;i<=26;++i) ch[cnt][i]=ch[q][i]; fa[cnt]=fa[q];fa[q]=fa[nd]=cnt; for(;p&&ch[p][c]==q;p=fa[p]) ch[p][c]=cnt; } void build(){ //cout<<" cnt "<<cnt<<endl; for(reg i=2;i<=cnt;++i) add(fa[i],i); } void dfs(int x){ for(reg i=hd[x];i;i=e[i].nxt){ int y=e[i].to; dfs(y); if(id[x]==-1) continue; if(id[y]){ if(id[y]==-1) id[x]=-1; else if(id[x]){ if(id[x]!=id[y]) id[x]=-1; } else id[x]=id[y]; } } if(id[x]!=-1) ans[id[x]]+=len[x]-len[fa[x]]; //cout<<x<<" : "<<id[x]<<endl; } }sam; int main(){ rd(m); for(reg i=1;i<=m;++i){ sam.nd=1; scanf("%s",s+1); n=strlen(s+1); for(reg j=1;j<=n;++j){ sam.ins(s[j]-'a'+1,j,i); } } sam.build(); sam.dfs(1); for(reg i=1;i<=m;++i){ printf("%lld ",ans[i]); } return 0; } } int main(){ Miracle::main(); return 0; } /* Author: *Miracle* Date: 2018/11/19 17:09:46 */
七、理解
1.和AC自动机比较
都是通过类似失配指针的思想,在失配的时候,尽量小地减少匹配长度,找到能够匹配的位点。
SAM还是完爆AC自动机的。毕竟AC自动机只能处理前缀问题。。不能处理子串匹配。
2.SAM的用法:
SAM虽然就是一个图但是其实博大精深!!
有一棵树,一张DAG,方法自然多了很多。
①Parent树(子串整体考虑)
树形DP以及信息转移——>可以赋予每个节点的Right以实际意义。
同样,father关系可以推出某个状态的最短长度min
②出边(trans)的DAG(处理匹配以及单个子串)
支持topo排序DP。通常用于考虑路径条数——对应子串个数
支持字符串匹配。
③与其他算法结合(一起用)
与SA:倒不算是结合,,大部分时候,SA能做的,SAM都能做。SA不能做的,SAM也能做。
SA和SAM的思路不太一样。
毕竟,SA:区间、区间取min、二分、ST表、单调队列、单调栈、分治
SAM:树形结构,DAG(路径问题),topo排序,DP,贪心。。
用法就要看题了。
3.小结论/小观察:
①某个节点i所管辖的字符串长度为[mini,maxi]的,有且仅有这些字符串在SAM上跑,会在i点结束匹配。
②跳father就是跳fail,通过减少匹配长度(当然,这个减少后的长度必须之前跑出过。(这也是为什么要建立nq节点。否则跑出来的串之前都没有存在23333)),进而增加出现位置,从而寻找更多的可能有当前字符x出边的位置。从而进行状态的转移。
由于max[fa[i]]+1=min[fa[i]],所以,其实减少匹配长度时,本质上考虑到了所有的长度。(只不过匹配位置不增加的我们不特殊考虑)
③SAM和思想核心在于,对于本质相同的字符串进行压缩,对所有结尾出现位置相同的字符串再进行压缩。一个点的集合,其实可以是很多个字符串。
我们相当于,对一个串的所有子串,按照它们的所有结束位置分类,一起来考虑。
我们不但节省了时间和空间、考虑了所有的子串,
并且,一个子串的出现次数,出现位置,以及不同子串的LCP,大小,出现位置比较,匹配,都可以比较轻松地处理。
4.Parent树和出边DAG的联系
DAG为Parent树提供构造基础。
Parent树为DAG的点赋予实际意义。(例如Right集合实际大小)