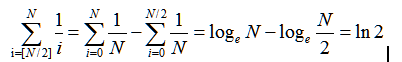(1)问题引入
问题一:
解决一个流行的字谜,输入是由一些字母和单词的二维数组组成。目标是要找出字谜中的单词,这些单词可能是水平、垂直、或沿对角线以任何方式放置的。作为例子下表中所示的字谜由单词“this”,"two","fat"和“that”组成。单词this从(1,1)开始,并延伸至(1,4),单词two从(1,1)到(3,1),fat从(4,1)到(2,3),that从(4,4)到(1,1)。
| 1 | 2 | 3 | 4 | |
| 1 | t | h | i | s |
| 2 | w | a | t | s |
| 3 | o | a | h | g |
| 4 | f | g | d | t |
方法1:对单词表中的每一个单词,我们检查每个有序三元组(行,列,方向),验证是否有单词存在。
方法2:对每一个尚未进行刀子米最后的有序四元组(行,列,方向,字符数)我们可以测试所指的单词是否在单词表中。
这两种方法是相对的。
上述两种方法相对来说都不难编码并可求解通常发表于杂志上的许多现实的字谜游戏。这些字谜通常有16行16列以及40个左右的单词。然而,假设我们只给出谜板而单词表基本上是一本英语词典,则上面提出的两种解法需要相当长的时间,显然是不可接受的。不过这样的问题还是有可能在数秒内完成的,即便单词表很大也可以。
问题二:
设有一组n个数而要确定其中的第k个最大者。我们称之为选择问题。
方法1:将这n个数读到一个数组里,再通过简单的算法,比如冒泡排序法,以递减顺序将数组排序,然后返回位置k上的元素。
方法2:可以先把前k个元素读入数组(以递减的顺序)对其进行排序。接着,将剩下的元素再逐个读入。当新元素被读到时,如果它小于数组中的第k个元素将被忽略,否则将数组的一个元素基础数组。当算法终止时,位于第k个位置上的元素作为答案返回。
在许多问题当中,一个重要的观念是:写出一个可以工作的程序并不够。如果这个程序在巨大的数据集上运行,那么运行时间就变成了中要的问题。我们将后续讨论对于大量的输入如何估计程序的运行时间,尤其是如何在尚未具体编码的情况下比较两个程序的运行时间。我们还将看到彻底改进程序速度以及确定程序瓶颈的方法。这些方法将使我们能够找到需要大力优化的那些代码段。
(2)递归简论
1)一个递归函数:
int F(int x){ if(x==0) return 0; else return 2*F(x-1)+x*x; }
一个无终止递归函数:
int Bad(unsigned int N){ if(N==0) return 0; else return Bad(N/3+1)+N/1; }
无终止递归函数产生的原因是产生了循环调用,在上例子中,Bad(1)的求解需要利用到Bad(1)。计算机将反复调用Bad(1)以期求解出它的值,计算机薄记系统将占满空间,程序崩溃。
2)打印输出数(一个整数)
void PrintOut(unsigned int N){ if(N>=10){ PrintOut(N/10); } PrintDigit(N%10); } //printDigit()用于输出单个数字到终端 void PrintDigit(int N){ printf("%d",N); }
如果是倒序输出的话,就将PrintOut()函数中的if语句与PrintDigit()函数调换顺序即可。
我们并没有努力地去高效做这件事,我们本可以避免使用mod操作(它的耗费是很大的),因为N%10=N-[N/10]*10。([x]意为小于或等于x的最大整数)
3)在编写递归例程的时候,关键要牢记递归的四条基本法则:
1.基准情形。
2.不断推进。
3.设计法则。
4.合成效益法则
(3)编程练习
1)编写一个程序解决选择问题。令k=N/2.画出表格显示你的程序对于不同N的运行时间。
#include<stdio.h> #include<stdlib.h> #include<sys/timeb.h> #include<time.h> #define N 1000//N的最大值为30000 void insertArray(long num,long *numGroup,int low,int high,int size){ int mid=(low+high)/2; int temp; int w; if((high-low)<=1){ for(w=size-1;w>low;w--){ numGroup[w+1]=numGroup[w]; } numGroup[w]=num; return 0; } if(num<=numGroup[low]&&num>numGroup[high]){ if(num>=numGroup[mid]){ insertArray(num,numGroup,low,mid,size); }else{ insertArray(num,numGroup,mid,high,size); } } } int main(){ long numArry[N]; int i,j; struct timeb p; ftime(&p); long preTime=p.time*1000+p.millitm; //1.利用随机数给数组赋值 srand(time(NULL)); for(i=0;i<N;i++){ numArry[i]=rand()%32767; } int k=N/2; long *maxArray=malloc(k*sizeof(long)); //2.读入数组的前k个元素给maxArray数组 for(i=0;i<k;i++){ maxArray[i]=numArry[i]; } //3.max对数组进行一次选择排序 int temp; for (i=0;i<k;i++) { temp=i; for(j=i;j<k;j++){ if(maxArray[temp]<maxArray[j]){ temp=j; } } if(temp!=i){ long t; t=maxArray[i]; maxArray[i]=maxArray[temp]; maxArray[temp]=t; } } //4.逐个选取后续的元素,插入到已经排好序的数组中 for(i=k;i<N;i++){ insertArray(numArry[i],maxArray,0,k-1,k-1); } ftime(&p); long lastTime=p.time*1000+p.millitm; printf("第%d个最大值为%ld,%d个最大值为%ld ",1,maxArray[0],k-1,maxArray[k-1]); printf("排过序的包含%d个最大值的数组为 ",k); for(i=0;i<k;i++){ printf("%7ld",maxArray[i]); if((i+1)%15==0){ printf(" "); } } printf("运行时间为:%d毫秒",lastTime-preTime); }
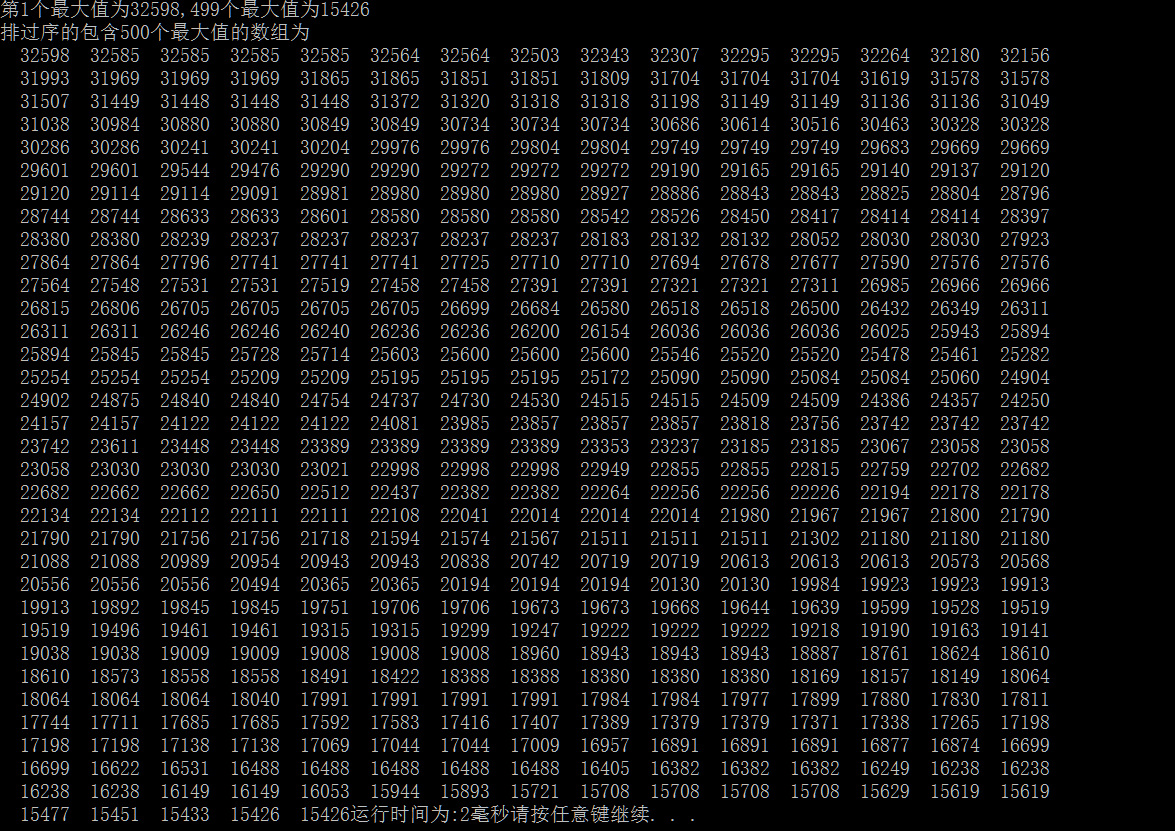
| 数组大小N | 1000 | 10000 | 30000 | 50000 |
| 运行时间 | 2毫秒 | 210毫秒 | 1314毫秒 | 3421毫秒 |
当测试算法所需时间时只需将N改为相应的值即可。
2)编写一个程序解决字谜游戏。
//1.2编写一个程序求解字谜游戏问题 #include <iostream> using namespace std;
//等价于#include<stdlib.h>,#include<stdio.h>
/* directions: 1------从左到右 2------从右到左 3------从上到下 4------从下到上 5------从左下到右上 6------从左上到右下 7------从右下到左上 8------从右上到左下 */ int compare(char *word1,char *word2){ int index1=0,index2=0; while(word1[index1]&&word2[index2]){ if(word1[index1]<word2[index2]) return 0; else if(word1[index1]>word2[index2]) return 1; index1++; index2++; } if(word1[index1]) return 1; else return 0; } //对字典进行排序,冒泡法 void sort(char **direc,int m){ int i,j; char* word1; char* word2; for(i = m;i>0;i--){ for(j = 0;j<i-1;j++){ word1 = direc[j]; word2 = direc[j+1]; if(compare(word1,word2)){//word1>word2 direc[j] = word2; direc[j+1] = word1; } } } } char **findOne(char **puzzle,int row,int col,int n,char **direct,int m,int index,int *returnSize){ char **res = (char **)malloc(sizeof(char*)*m); int count = 0; int dir; int i; char head = puzzle[row][col]; int tmpRow,tmpCol; int directIndex; for(dir = 1;dir<=8;dir++){ directIndex = 0; tmpRow = row; tmpCol = col; switch (dir) { case 1://左到右 for(i = index;i<m&&direct[i][0]==head;i++){ while(direct[i][directIndex]&&tmpCol<n){ if(direct[i][directIndex]!=puzzle[tmpRow][tmpCol]){ break; } tmpCol++; directIndex++; } if(!direct[i][directIndex]){ res[count++] = direct[i]; break; } } break; case 2://从右向左 for(i = index;i<m&&direct[i][0]==head;i++){ while(direct[i][directIndex]&&tmpCol>=0){ if(direct[i][directIndex]!=puzzle[tmpRow][tmpCol]){ break; } tmpCol--; directIndex++; } if(!direct[i][directIndex]){ res[count++] = direct[i]; break; } } break; case 3://从上到下 for(i = index;i<m&&direct[i][0]==head;i++){ while(direct[i][directIndex]&&tmpRow<n){ if(direct[i][directIndex]!=puzzle[tmpRow][tmpCol]){ break; } tmpRow++; directIndex++; } if(!direct[i][directIndex]){ res[count++] = direct[i]; break; } } break; case 4://从下到上 for(i = index;i<m&&direct[i][0]==head;i++){ while(direct[i][directIndex]&&tmpRow>=0){ if(direct[i][directIndex]!=puzzle[tmpRow][tmpCol]){ break; } tmpRow--; directIndex++; } if(!direct[i][directIndex]){ res[count++] = direct[i]; break; } } break; case 5://从左下到右上 for(i = index;i<m&&direct[i][0]==head;i++){ while(direct[i][directIndex]&&tmpCol<n&&tmpRow>=0){ if(direct[i][directIndex]!=puzzle[tmpRow][tmpCol]){ break; } tmpRow--; tmpCol++; directIndex++; } if(!direct[i][directIndex]){ res[count++] = direct[i]; break; } } break; case 6://从左上到右下 for(i = index;i<m&&direct[i][0]==head;i++){ while(direct[i][directIndex]&&tmpCol<n&&tmpRow<n){ if(direct[i][directIndex]!=puzzle[tmpRow][tmpCol]){ break; } tmpRow++; tmpCol++; directIndex++; } if(!direct[i][directIndex]){ res[count++] = direct[i]; break; } } break; case 7://从右下到左上 for(i = index;i<m&&direct[i][0]==head;i++){ while(direct[i][directIndex]&&tmpCol>=0&&tmpRow>=0){ if(direct[i][directIndex]!=puzzle[tmpRow][tmpCol]){ break; } tmpRow--; tmpCol--; directIndex++; } if(!direct[i][directIndex]){ res[count++] = direct[i]; break; } } break; case 8://从右上到左下 for(i = index;i<m&&direct[i][0]==head;i++){ while(direct[i][directIndex]&&tmpCol>=0&&tmpRow<n){ if(direct[i][directIndex]!=puzzle[tmpRow][tmpCol]){ break; } tmpRow++; tmpCol--; directIndex++; } if(!direct[i][directIndex]){ res[count++] = direct[i]; break; } } break; default: break; } } *returnSize = count; return res; } char **findWord(char **puzzle,int n,char **direc,int m,int *returnSize){ char **res = (char **)malloc(sizeof(char *)*m);//返回值 int count = 0;//res index int row,col; int i; char tmp; char hash[26];//store first word char index; sort(direc,m);//将direct排序 for(i = 0;i<26;i++) hash[i] = -1; for(i = 0;i<m;i++){ tmp = direc[i][0]; if(hash[tmp-'a']==-1) hash[tmp-'a'] = i;//存储direc的开始索引 } //print direc and hash table //for(i = 0;i<m;i++) // printf("%s ",direc[i]); //for(i = 0;i<26;i++) // printf("%d ",hash[i]); for(row = 0;row<n;row++){ for(col = 0;col<n;col++){ tmp = puzzle[row][col]; //check hash table; index = hash[tmp-'a']; if(index==-1) continue; int size; char **word = findOne(puzzle,row,col,n,direc,m,index,&size); if(size){ for(i = 0;i<size;i++) res[count++] = word[i]; } } } *returnSize = count; return res; } int main(){ int n = 4; char *puzzle[4]; char p1[4] = {'t','h','i','s'}; char p2[4] = {'w','a','t','s'}; char p3[4] = {'o','a','h','g'}; char p4[4] = {'f','g','d','t'}; puzzle[0] = p1; puzzle[1] = p2; puzzle[2] = p3; puzzle[3] = p4; char *s1 = "this"; char *s2 = "two"; char *s3 = "otw"; char *s4 = "fat"; char *s5 = "that"; char *s6 = "hello"; char *s7 = "fuck"; char *direc[7]; direc[0] = s1; direc[1] = s2; direc[2] = s3; direc[3] = s4; direc[4] = s5; direc[5] = s6; direc[6] = s7; int size; char ** res = findWord(puzzle,4,direc,7,&size); int i; for(i = 0;i<size;i++) printf("%s ",res[i]); system("pause"); }

3)只是用处理I/O的PrintDigit函数,编写一个过程以输出任意实数。
能够指定输出小数的位数的函数:
#include <stdio.h> #define PrintDigit( Ch ) ( putchar( ( Ch ) + '0' ) ) void PrintInt(unsigned int N) /* Print nonnegative N */ { if (N >= 10) PrintInt(N / 10); PrintDigit(N % 10); } void PrintOut(double N,int accuracy) { if (N < 0){ putchar('-'); N = -N; } int n = (int)N; PrintInt(n); double decimal = N - n; if (decimal > 0){ putchar('.'); double add = 0.5; for (int i = 0; i < accuracy; i++) { add /= 10; } N += add; for (int i = 0; i < accuracy; i++){ decimal *= 10; } PrintInt(decimal); } } int main() { PrintOut(1208.123456,4); putchar(' '); return 0; }

原封不动的输出:
#include<stdio.h> void printDigit(int n){ printf("%d",n); } void printInt(int N){ if(N>=10){ printInt(N/10); } printDigit(N%10); } void printNumber(float x){ if(x<0){ putchar('-'); x=-x; } long n=(long)x; double dec=x-n; printInt(n); putchar('.'); while(dec!=0){ dec=dec*10; printDigit(int(dec)); dec=dec-(int)dec; } } int main(){ printf("请输入任意实数"); float x; scanf("%f",&x); printNumber(x); printf(" %f",x); }

出现这种情况可能是由于float的精度的问题。
4)c语言提供形如:
#include filename 的语句,它读入文件filename并将其插入到include语句处。include语句可以嵌套;换句话说,文件filename本身还可以包含include语句,但是显然一个文件在任何链接中都不能包含他自己。编写一个程序,是它读入被include修饰的文件,并输出这个文件。
#include <stdio.h> #include <stdlib.h> #include <string.h> #define Max 100 #define Od 50 #define Sm 20 //字符串数组,用来保存已经打开的文件名,以防止重复打开。最多能够打开100个。 char openedFile[Max][Sm]; int openedNumber=-1; //str存的是cfree中的库文件所在的目录 const char str[Max]="C:/C-Free 5/mingw/include/"; void processLine(char *p){ //if(strcmp(p,"FileInclude.c")){ printf("--------------------%20s--------------------- ",p); //} FILE *fp; char line[Max]; int i=0,j=0; if((fp=fopen(p,"r"))==NULL){ printf("打开文件失败"); exit(0); } //每一个子文件中可能包含的其他文件,最多20个! char notOpenedFile[Sm][Sm]; int notOpenedNum=-1; while(!feof(fp)){ fgets(line,100,fp); //printf("%s",line); //用来判断一个字符串中是否包含另一个字符串 char *newFile; //如果此行是用来包含文件的,存下来 if(newFile=strstr(line,"#include <")){ if(newFile=strstr(line,">")){ char *start = (char *)strchr(line, '<'); char temp[Od]; strcpy(temp, start + 1); temp[strlen(temp)-2] = '�';//去掉结尾的> strcpy(notOpenedFile[++notOpenedNum],temp); } } } free(fp); printf("文件%s需要再次引入的文件有: ",p); if(notOpenedNum==-1){ printf("%s ","无"); return; } for(i=0;i<=notOpenedNum;i++){ printf("%2d: %s",i+1,notOpenedFile[i]); printf(" "); //如果这个需要再次引入的文件已经输出过,则不必再次输出 for(j=0;j<=openedNumber;j++){ if(strcmp(notOpenedFile[i],openedFile[j])==0){ strcpy(notOpenedFile[i],""); }else{ //printf("未打开的文件%s ",openedFile[openedNumber]); } } } char string[50]; for(i=0;i<=notOpenedNum;i++){ if(strcmp("",notOpenedFile[i])!=0){ strcpy(string,str); strcat(string,notOpenedFile[i]); strcpy(openedFile[++openedNumber],notOpenedFile[i]); processLine(string); } } fclose(fp); } void printsingleFile(char *p){ printf(" --------------------%s--------------------- ",p); FILE *fp; if((fp=fopen(p,"r"))==NULL){ printf("打开文件失败"); exit(0); }else printf("打开文件成功! "); //用来存读到的东西 char line[Max]; while(!feof(fp)){ fgets(line,100,fp); printf("%s",line); } fclose(fp); } void printAllFile(){ int i; for(i=0;i<=openedNumber;i++){ char temp[Od]; strcpy(temp,""); if(i==0){ strcat(temp,openedFile[i]); printsingleFile(temp); }else if(i>=1){ strcpy(temp,str); strcat(temp,openedFile[i]); printsingleFile(temp); } } } int main(){ printf("下面打印出本程序的源文件内容: "); char string[Od]; strcpy(string,"FileInclude.c"); strcpy(openedFile[++openedNumber],"FileInclude.c"); char temp[10]; processLine(string); int i; //printAllFile(); return 0; }

写这个程序用了大概3个小时,调试到尽善尽美大概4个小时,总共7个小时,下面总结其中遇到的一些问题:
问题1:由于要分析打开的文件的每一行的文本,因此,首先要将文件打开一行一行的读,用fget()函数,将自定义的读取字节数足够大,那么唯一能引起读操作结束的就是遇到换行符了!
问题2:strstr()函数用于在特定行找到特定的字符串,返回值是一个字符指针类型。可以当if的判断条件。
问题3: strchr函数用于从一个字符串中的特定的子字符串开始,将其后的所有字符返回给一个字符指针类型(包括本身)。
问题4:用完文件指针要用fclose关闭,用free也不会报错!
问题5:调试程序时,f7能进入主调函数中的被调函数,f8则直接运行完整个被调函数,不离开主调函数的栈区。而且在程序运行时也可以打断点,按f9键可以一下子运行到打的断点处!(即是在运行中)
问题6:标准的c程序的#include语句中,与<"文件名">中间有一个空格!
问题7:不能给字符串直接赋值,例如:char str[20];str="";(错误)char str[20]="";(正确)
问题8:如果全局变量与局部变量同名,局部变量将屏蔽全局变量。不能同时使用了!所以命名时要将全局变量命生涩的名,这样才不会发生冲突!
5)估计1/i的累加和(i从[n/2]到n):估计:![]()
知识:Hn为调和数,其和为调和和。下面近似式中的误差趋向于约等于0.5772,这个值称为欧拉常数:
![]()
结果: