第 10 章 Elasticsearch 生态圈
天际浮云入思深
物情生态看销沉
第 9 章介绍了 Elasticsearch 的插件生态,插件生态是依托于 Elasticsearch 内部的,属于一种相对狭义、微观的生态;本章主要介绍 Elasticsearch 的宏观生态。
10.6 小结
本章主要介绍了 Elasticsearch 的生态圈,即 ELK Stack。先后介绍了 ELK Stack 的背景、ELK 的实战部署架构设计,以及 Logstash、Kibana 和 Beats。
10.1 ELK
提到 Elasticsearch 生态,很多人第一反应就是 ELK Stack。什么是 ELK Stack 呢?很简单,ELK Stack 指的就是 Elastic Stack。
10.1.1 Elastic Stack
「ELK」是三个开源项目的首字母缩写,这三个项目分别是:Elasticsearch、Logstash 和 Kibana,如图 10-1 所示。当然,这并非是 Elastic Stack 的全部,读者可以根据需要在生态中添加 Redis、Kafka、Filebeat 等软件。

当前的 Elastic Stack 其实是 ELK Stack 的更新换代产品。2015 年,ELK Stack 中加入了一系列轻量级的单一功能数据采集器,并把它们叫作 Beats。
Beats 加入 ELK 家族后,再叫 ELK 显然不太合适,那么新的家族叫什么呢?
其实,Elastic 官方当时也的确想继续沿用首字母缩写的方式,但 Elastic 又相继收购了 APM 公司 Opbeat、机器学习公司 Prelert、SaaS 服务公司 Found、搜索服务公司 Swiftype、终端安全公司 Endgame 等来扩大自己的商业版图。
对于 Elastic 扩展速度如此之快的生态而言,一直采用首字母缩写的确不是长久之计。于是,Elastic Stack 这个「一劳永逸」般的名字就诞生了。
10.1.2 Elastic Stack 版本的由来
Elasticsearch 的版本号从 2 直接升到 5 是怎么回事呢?
在最初的 Elastic Stack 生态中,Elasticsearch、Logstash、Kibana 和 Beats 有各自的版本号,如当 Elasticsearch 和 Logstash 的版本号是 V2.3.4 时,Kibana 的版本号是 V4.5.3,而 Beats 的版本号是 V1.2.3。
因此,Elastic Stack 官方将产品版本号也进行了统一,从 V5.0 开始。因为当时的 Kibana 版本号已经是 4.x 了,其下个版本只能是 5.0,所以其他产品的版本号也随之「跳级」,于是 V5.0 版本的 Elastic Stack 在 2016 年就面世了。
10.1.3 ELK 实战的背景
在实际使用过程中,什么场景适合使用 ELK 呢?
在实战中,我们既可以用 ELK 管理和分析日志,也可以用 ELK 分析索引中的数据。
在当前的软件开发过程中,业务发展节奏越来越快,服务器梳理越来越多,随之而来的就是各种访问日志、应用日志和错误日志。随着时间的流逝,日志的累积也越来越多。
此时,会出现这样的问题:运维人员无法很好地管理日志;开发人员排查业务问题时需要到服务器上查询大量日志;当运营人员需要一些业务数据时,需要到服务器上分析日志。
在上述场景中,通常意义上的「awk」和「grep」命令已经力不从心,而且效率很低。这时 ELK 就可以「隆重登场」啦!
ELK 的三个组件是如何分工协作的呢?
首先,我们使用 Logstash 进行日志的搜集、分析和过滤。一般工作方式为 C/S 架构,Client 端会被安装在需要收集日志的主机上,Server 端则负责收集的各节点的日志数据,并进行过滤、修改和分析等操作,预处理过的数据会一并发到 Elasticsearch 上。
随后将 Kibana 接入 Elasticsearch,并为 Logstash 和 Elasticsearch 提供日志分析友好的 Web 界面,帮助用户汇总、分析和搜索重要数据的日志。
10.1.4 ELK 的部署架构变迁
ELK 架构为数据分布式存储、可视化查询和日志解析创建了一个功能强大的管理链。ELK 架构为用户建立了集中式日志收集系统,将所有节点上的日志统一收集、管理和访问。三者相互配合,取长补短,共同完成分布式大数据处理工作。
当前官方推荐的 ELK 部署架构并非一步到位,而是经过迭代演进发展而来的。下面简单介绍 ELK 架构的发展历程。
最简单的一种 ELK 部署架构方式如图 10-2 所示。

首先由分布于各个服务节点上的 Logstash 搜集相关日志和数据,经过 Logstash 的分析和过滤后发送给远端服务器上的 Elasticsearch 进行存储。Elasticsearch 将数据以分片的形式压缩存储,并提供多种 API 供用户进行查询操作。用户还可以通过配置 Kibana Web Portal 对日志进行查询,并根据数据生成报表。
该架构最显著的优点是搭建简单,易于上手。但缺点同样很突出,因为 Logstash 消耗资源较大,所以在运行时会占用很多的 CPU 和内存。并且系统中没有消息队列缓存等持久化手段,因而存在数据丢失隐患。因此,一般这种部署架构通常用于学习和小规模集群。
基于第一种 ELK 部署架构的优缺点,第二种架构引入了消息队列机制,如图 10-3 所示。
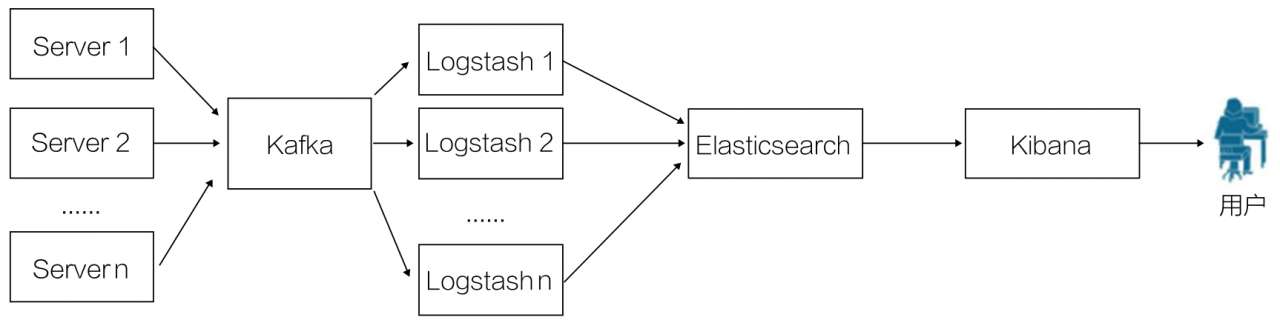
位于各个节点上的 Logstash 客户端先将数据和日志等内容传递给 Kafka,当然,也可以用其他消息机制,如各类 MQ(Message Queue)和 Redis 等。
Kafka 会将队列中的消息和数据传递给 Logstash,经过 Logstash 的过滤和分析等处理后,传递给 Elasticsearch 进行存储。最后由 Kibana 将日志和数据呈现给用户。
在该部署架构中,Kafka 的引入使得即使远端 Logstash 因故障而停止运行,数据也会被存储下来,从而避免数据丢失。
第二种部署架构解决了数据的可靠性问题,但 Logstash 的资源消耗依然较多,因而引出第三种架构。第三种架构引入了 Logstash-forwarder,如图 10-4 所示。
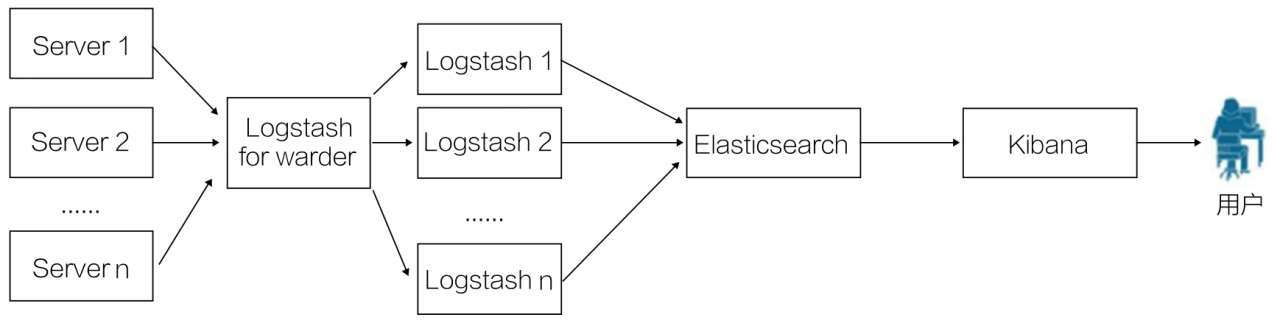
Logstash-forwarder 将日志数据搜集并统一后发送给主节点上的 Logstash,Logstash 在分析和过滤日志数据后,把日志数据发送至 Elasticsearch 进行存储,最后由 Kibana 将数据呈现给用户。
这种架构解决了 Logstash 在各计算机点上占用系统资源较多的问题。与 Logstash 相比,Logstash-forwarder 所占系统的 CPU 和内存几乎可以忽略不计。
而且,Logstash-forwarder 的数据安全性更好。Logstash-forwarder 和 Logstash 之间的通信是通过 SSL 加密传输的,因此安全有保障。
随着 Beats 组件引入 ELK Stack,第四种部署架构应运而生,如图 10-5 所示。
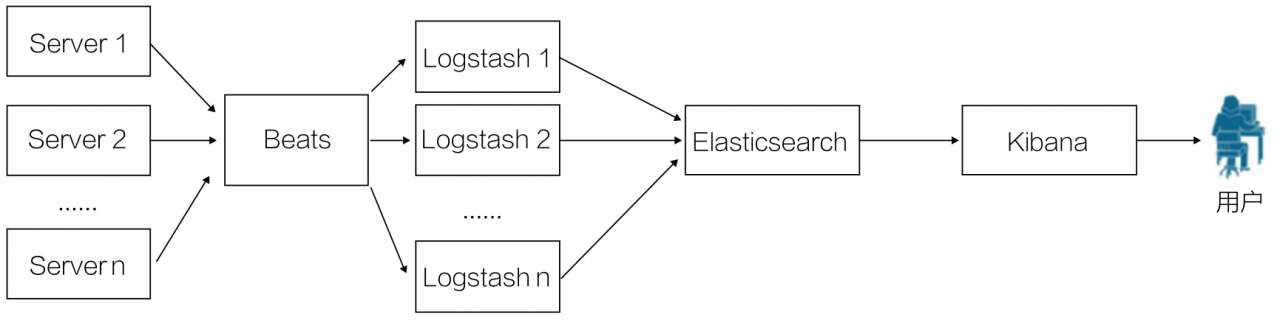
在实际使用中,Beats 平台在满负荷状态时所耗系统资源和 Logstash-forwarder 相当,但其扩展性和灵活性更好。Beats 平台目前包含 Packagebeat、Topbeat 和 Filebeat 三个产品,均为 Apache 2.0 License。同时用户可以根据需要进行二次开发。
与前面三个部署架构相比,显然第四种架构更灵活,可扩展性更强。
用户可以根据自己的需求搭建自己的 ELK。
10.2 Logstash
10.2.1 Logstash 简介
Logstash 由三部分组成,即输入模块(INPUTS)、过滤器模块(FILTERS)和输出模块(OUTPUTS),如图 10-6 所示。
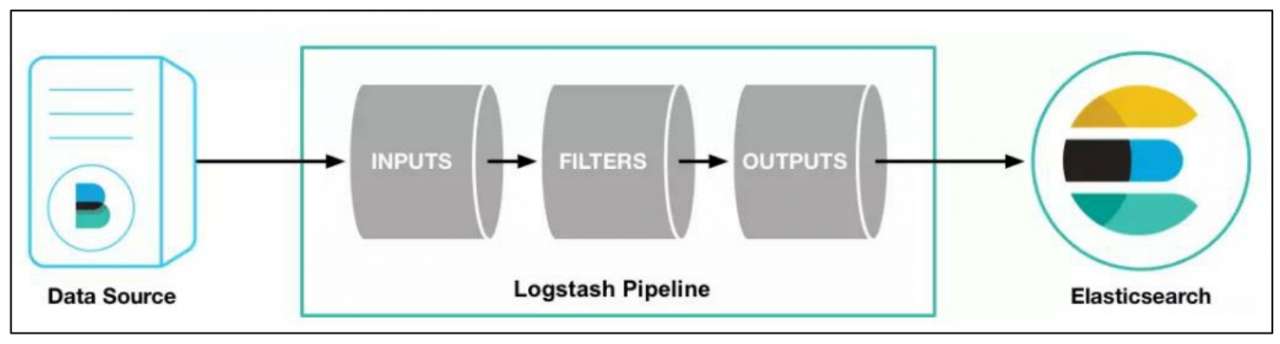
Logstash 能够动态地采集、转换和传输数据,不受格式或复杂度的影响。利用 Grok 从非结构化数据中派生出结构,从 IP 地址解码出地理坐标,匿名化或排除敏感字段,并简化整体处理过程。
从官网下载 Logstash 安装包。下载完成后,在本地解压缩。解压缩后的根目录内容如图 10-7 所示。
根目录下有 bin、config、data、lib、logstash core 和 tools 等内容。
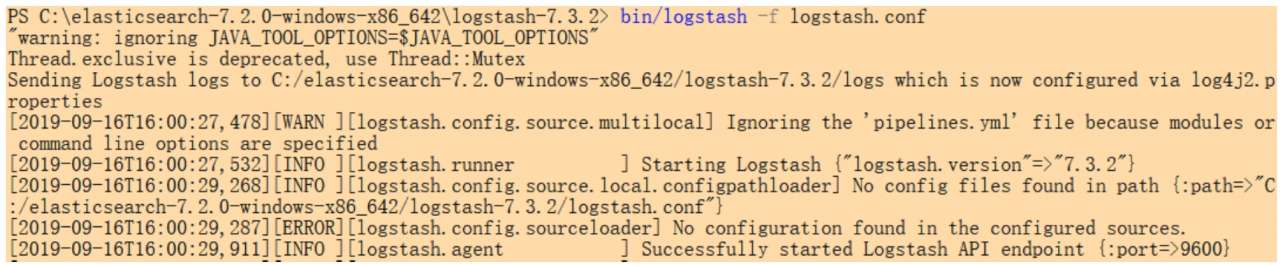
在 Logstash 启动后,会自动创建 logs 目录。随后配置 config 目录下的 logstash.conf 文件。首次配置时可参考同目录的 logstash-simple.conf 示例进行配置。配置后,执行 bin/logstash-f logstash.conf 即可启动 Logstash 服务,如下所示:
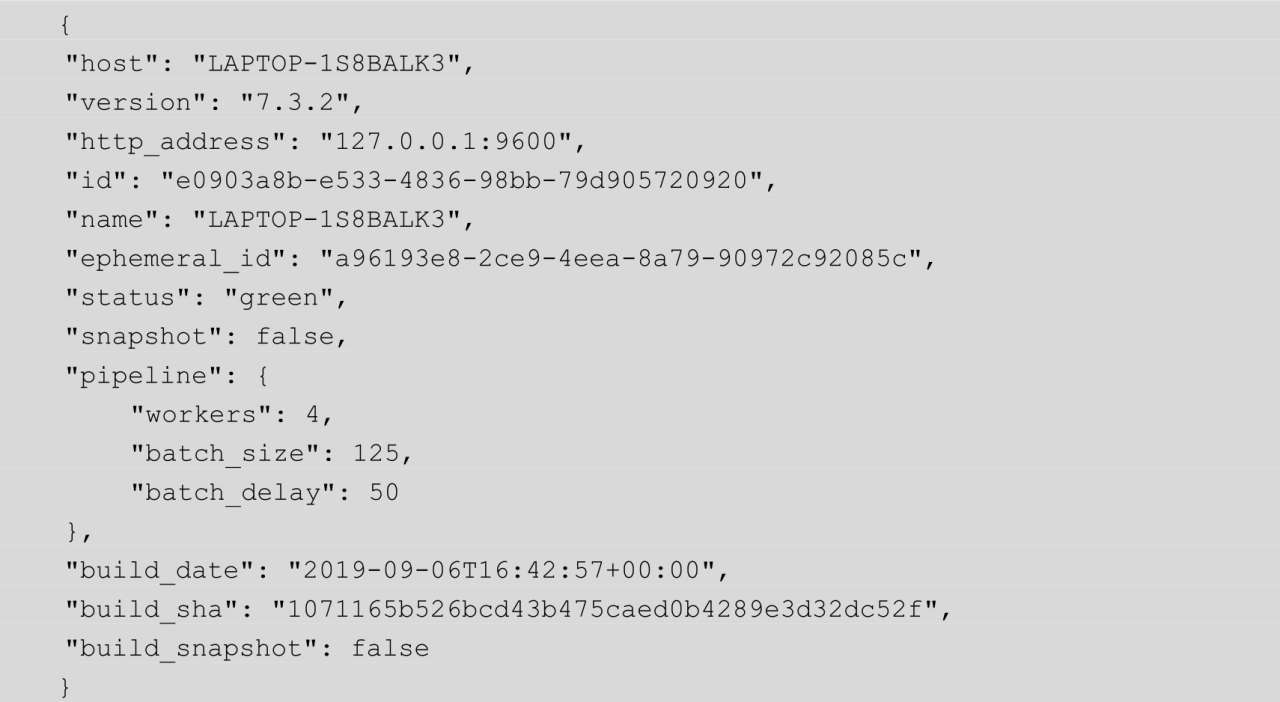
此时,在浏览器中输入http://localhost:9600/,浏览器的页面中即可输出如下内容:
需要指出的是,Logstash 文件夹存放的路径中不能有中文命名的文件夹,否则会给出错误提示。
10.2.2 Logstash 的输入模块
Logstash 的输入模块用于采集各种样式、大小和来源的数据。一般来说,数据往往以各种各样的形式,或分散或集中地存储于很多系统中。Logstash 支持各种输入选择,可以在同一时间从众多常用来源捕捉事件,能够以流式传输方式,轻松地从用户的日志、指标、Web 应用、数据存储及各种 AWS 服务中采集数据。
为了支持各种数据输入,Logstash 提供了很多输入插件,汇总如下。
(1)azure_event_hubs:该插件从微软 Azure 事件中心接收数据。读者可访问 GitHub 官网,搜索 logstash-input-azure_event_hubs 获取插件。
(2)beats:该插件从 Elastic Beats 框架接收数据。读者可访问 GitHub 官网,搜索 logstash-input-beats 获取插件。
(3)cloudwatch:该插件从 Amazon Web Services CloudWatch API 中提取数据。读者可访问 GitHub 官网,搜索 logstash-input-cloudwatch 获取插件。
(4)couchdb_changes:该插件从 CouchDB 更改 URI 的流式处理事件中获取数据。读者可访问 GitHub 官网,搜索 logstash-input-couchdb_changes 获取插件。
(5)dead_letter_queue:该插件从 logstash 的 dead letter 队列中读取数据。读者可访问 GitHub 官网,搜索 logstash-input-dead_letter_queue 获取插件。
(6)elasticsearch:该插件从 ElasticSearch 群集中读取查询结果。读者可访问 GitHub 官网,搜索 logstash-input-elasticsearch 获取插件。
(7)exec:该插件将 shell 命令的输出捕获为事件,并获取数据。读者可访问 GitHub 官网,搜索 logstash-input-exec 获取插件。
(8)file:该插件从文件流式处理中获取数据。读者可访问 GitHub 官网,搜索 logstash-input-file 获取插件。
(9)ganglia:该插件通过 UDP 数据包读取 ganglia 中的数据包来获取数据。读者可访问 GitHub 官网,搜索 logstash-input-ganglia 获取插件。
(10)gelf:该插件从 graylog2 中读取 gelf 格式的消息获取数据。读者可访问 GitHub 官网,搜索 logstash-input-gelf 获取插件。
(11)http:该插件通过 HTTP 或 HTTPS 接收事件获取数据。读者可访问 GitHub 官网,搜索 logstash-input-http 获取插件。
(12)jdbc:该插件通过 JDBC 接口从数据库中获取数据。读者可访问 GitHub 官网,搜索 logstash-input-jdbc 获取插件。
(13)kafka:该插件从 Kafka 主题中读取事件,从而获取数据。读者可访问 GitHub 官网,搜索 logstash-input-kafka 获取插件。
(14)log4j:该插件通过 TCP 套接字从 Log4J SocketAppender 对象中读取数据。读者可访问 GitHub 官网,搜索 logstash-input-log4j 获取插件。
(15)rabbitmq:该插件从 RabbitMQ 数据交换中提取数据。读者可访问 GitHub 官网,搜索 logstash-input-rabbitmq 获取插件。
https://github.com/logstash-plugins/logstash-input-rabbitmq
(16)redis:该插件从 redis 实例中读取数据。读者可访问 GitHub 官网,搜索 logstash-input-redis 获取插件。
10.2.3 Logstash 过滤器
Logstash 过滤器用于实时解析和转换数据。
在数据从源传输到存储库的过程中,Logstash 过滤器能够解析各个数据事件,识别已命名的字段,构建对应的数据结构,并将它们转换成通用格式,以便更轻松、更快速地进行分析,实现商业价值。
Logstash 过滤器有以下特点:
(1)利用 Grok 从非结构化数据中派生出结构。
(2)从 IP 地址破译出地理坐标。
(3)将 PII 数据匿名化,完全排除敏感字段。
(4)简化整体处理,不受数据源、格式或架构的影响。
为了处理各种各样的数据源,Logstash 提供了丰富多样的过滤器库,常用的过滤器插件汇总如下。
(1)aggregate:该插件用于从一个任务的多个事件中聚合信息。读者可访问 GitHub 官网,搜索 logstash-filter-aggregate 获取插件。
(2)alter:该插件对 mutate 过滤器不处理的字段执行常规处理。读者可访问 GitHub 官网,搜索 logstash-filter-alter 获取插件。
(3)bytes:该插件将以计算机存储单位表示的字符串形式,如「123MB」或「5.6GB」,解析为以字节为单位的数值。读者可访问 GitHub 官网,搜索 logstash-filter-bytes 获取插件。
(4)cidr:该插件根据网络块列表检查 IP 地址。读者可访问 GitHub 官网,搜索 logstash-filter-cidr 获取插件。
(5)cipher:该插件用于对事件应用增加或移除密钥。读者可访问 GitHub 官网,搜索 logstash-filter-cipher 获取插件。
(6)clone:该插件用于复制事件。读者可访问 GitHub 官网,搜索 logstash-filter-clone 获取插件。
(7)csv:该插件用于将逗号分隔的值数据解析为单个字段。读者可访问 GitHub 官网,搜索 logstash-filter-csv 获取插件。
(8)date:该插件用于分析字段中的日期,多用于事件日志中存储的时间戳。读者可访问 GitHub 官网,搜索 logstash-filter-date 获取插件。
(9)dns:该插件用于执行正向或反向 DNS 查找。读者可访问 GitHub 官网,搜索 logstash-filter-dns 获取插件。
(10)elasticsearch:该插件用于将 Elasticsearch 日志事件中的字段复制到当前事件中。读者可访问 GitHub 官网,搜索 logstash-filter-elasticsearch 获取插件。
(11)geoip 该插件用于添加有关 IP 地址的地理信息。读者可访问 GitHub 官网,搜索 logstash-filter-geoip 获取插件。
(12)json:该插件用于解析 JSON 事件。读者可访问 GitHub 官网,搜索 logstash-filter-json 获取插件。
(13)kv:该插件用于分析键值对。读者可访问 GitHub 官网,搜索 logstash-filter-kv 获取插件。
(14)memcached:该插件用于提供与 memcached 中数据的集成。读者可访问 GitHub 官网,搜索 logstash-filter-memcached 获取插件。
(15)split:该插件用于将多行消息拆分为不同的事件。读者可访问 GitHub 官网,搜索 logstash-filter-split 获取插件。
10.2.4 Logstash 的输出模块
Logstash 的输出模块用于将目标数据导出到用户选择的存储库。
在 Logstash 中,尽管 Elasticsearch 是 Logstash 官方首选的,但它并非唯一选择。
Logstash 提供众多输出选择,用户可以将数据发送到指定的地方,并且能够灵活地解锁众多下游用例。
(1)csv:该插件以 CVS 格式将结果数据写入磁盘。读者可访问 GitHub 官网,搜索 logstash-output-csv 获取插件。
(2)mongodb:该插件将结果数据写入 MongoDB。读者可访问 GitHub 官网,搜索 logstash-output-mongodb 获取插件。
(3)elasticsearch:该插件将结果数据写入 Elasticsearch。读者可访问 GitHub 官网,搜索 logstash-output-elasticsearch 获取插件。
(4)email:该插件将结果数据发送到指定的电子邮件。读者可访问 GitHub 官网,搜索 logstash-output-email 获取插件。
(5)kafka:该插件将结果数据写入 Kafka 的 Topic 主题。读者可访问 GitHub 官网,搜索 logstash-output-kafka 获取插件。
(6)file:该插件将结果数据写入磁盘上的文件。读者可访问 GitHub 官网,搜索 logstash-output-file 获取插件。
(7)redis:该插件使用 redis 中的 rpush 命令将结果数据发送到 redis 队列。读者可访问 GitHub 官网,搜索 logstash-output-redis 获取插件。
10.3 Kibana
Kibana 是一个基于 Web 的图形界面,可以让用户在 Elasticsearch 中使用图形和图表对数据进行可视化。
在实际使用过程中,Kibana 一般用于搜索、分析和可视化存储在 Elasticsearch 指标中的日志数据。Kibana 利用 Elasticsearch 的 REST 接口检索数据,不仅允许用户创建自己的数据定制仪表板视图,还允许他们以特殊的方式查询和过滤数据。可以说从跟踪、查询、负载到理解请求如何流经整个应用,Kibana 都能轻松完成。
10.3.1 Kibana 简介
Kibana 提供了基本内容服务、位置分析服务、时间序列服务、机器学习服务,以及图表和网络服务。
(1)基本内容服务:指的是 Kibana 核心产品中搭载的一批经典功能,如基于筛选数据绘制柱形图、折线图、饼图、旭日图等。
(2)位置分析服务:主要借助 Elastic Maps 探索位置数据。另外,还可以获得创意,对定制图层和矢量形状进行可视化。
(3)时间序列服务:借助 Kibana 团队精选的时序数据 UI,对用户所用 Elasticsearch 中的数据执行高级时间序列分析。因而,用户可以利用功能强大、简单易学的表达式来描述查询、转换和可视化。
(4)机器学习服务:主要是借助非监督型机器学习功能检测隐藏在用户所用 Elasticsearch 数据中的异常情况,并探索那些对用户有显著影响的属性。
(5)图表和网络服务:凭借搜索引擎的相关性功能,结合 Graph 关联分析,揭示用户所用 Elasticsearch 数据中极其常见的关系。
此外,Kibana 还支持用户把 Kibana 可视化内容分享给他人,如团队成员、老板、客户、合规经理或承包商等,进而让每个人都感受到 Kibana 的便利。
除分享链接外,Kibana 还有其他内容输出形式,如嵌入仪表板,导出为 PDF、PNG 或 CSV 等格式文件,以便把这些文件作为附件发送给他人。
我们可从官网下载 Kibana,下载完成后,即可在本地进行解压缩。解压缩后的 Kibana 的根目录如图 10-8 所示。

10.3.2 连接 Elasticsearch
由于 Kibana 服务需要连接到 Elasticsearch,因此在启动 Kibana 前,需要先启动 Elasticsearch,否则,Kibana 在启动过程中会显示如下所示错误:

在启动 Elasticsearch 后,需要对 config/kibana.yml 文件进行配置。主要是配置 elasticsearch.hosts 属性,该属性在无配置的情况下默认连接到http://localhost:9200。
在配置好 elasticsearch.hosts 属性后,即可通过如下命令启动 Kibana:
bin/kibana
如果是在 Windows 环境下启动,则使用如下命令启动 Kibana:
binkibana.bat
当 Kibana 启动成功后,输出内容如下所示:
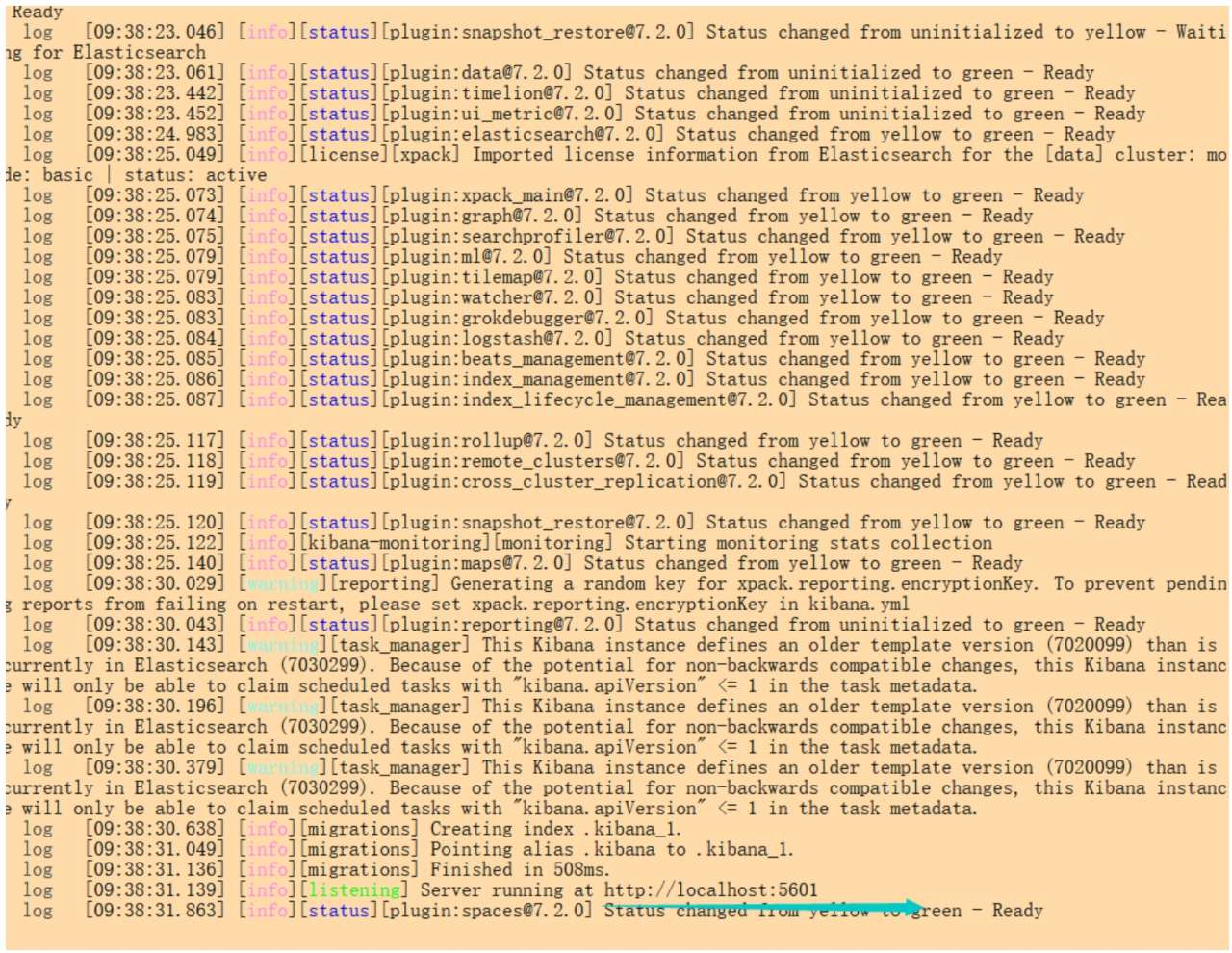
我们可以在浏览器的地址栏中输入http://localhost:5601,打开 Kibana 页面。此时,打开的页面是一个欢迎页面。
我们既可以单击「Try our sample data」按钮体验 Kibana 的功能,也可以单击「Explore on my own」按钮使用自己的数据体验 Kibana 的功能。
下面以单击「Try our sample data」按钮为例,体验 Kibana 的功能。
单击「Try our sample data」按钮,进入如图 10-9 所示页面。
我们选择第一种展现类型作为示例,单击「Add Data」按钮后,Kibana 开始对数据进行加载,这个过程会持续数十秒。当数据加载后,「Add Data」按钮会变成如图 10-10 所示的「View Data」按钮。

单击「View Data」按钮,进入如图 10-11 所示页面。
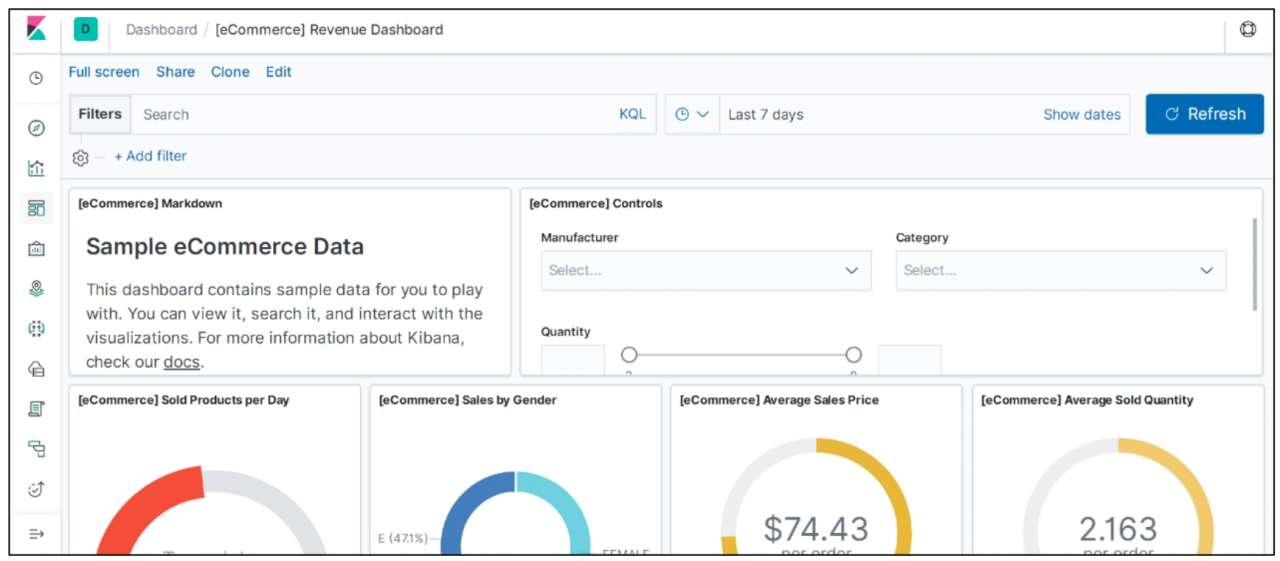
在图 10-13 所示页面中,可以通过筛选数据,查看细粒度的呈现。主要有关键词和时间两个筛选维度。单击「Discover」按钮,切换到如图 10-12 所示页面,查看数据的时间轴信息和数据详情信息。
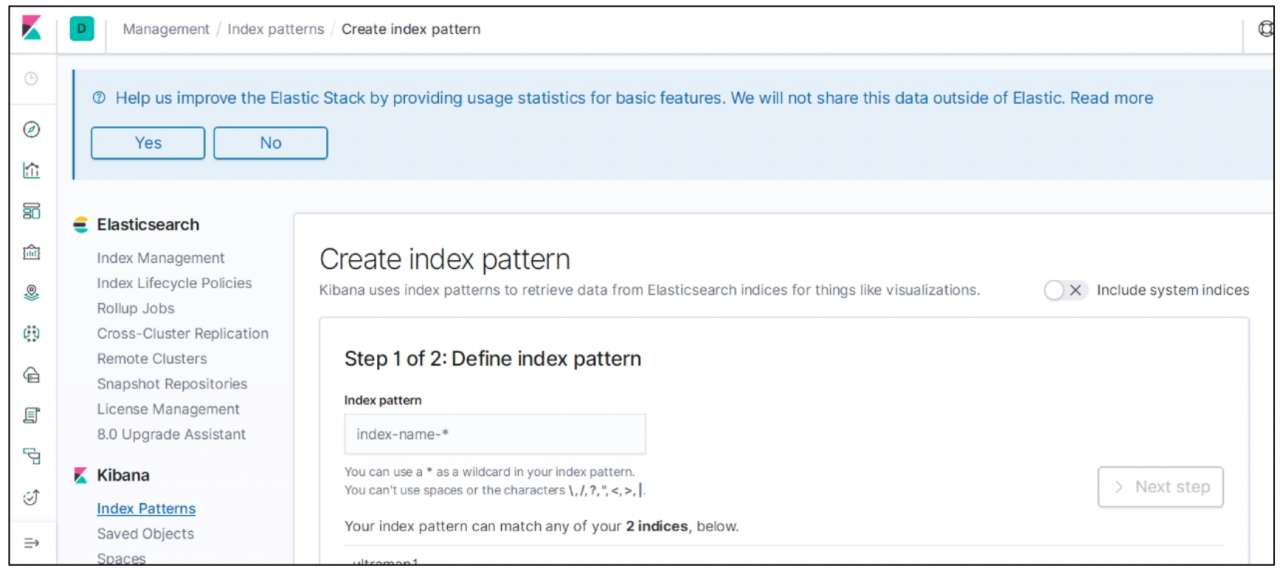
在实际使用中,需要配置必要的 Elasticsearch 索引信息,以便与 Kibana 进行数据联通。配置索引的页面如图 10-13 所示。
10.4 Beats
Logstash 在数据收集上并不出色,而作为代理,其性能也并不达标。于是,Elastic 官方发布了 Beats 系列轻量级采集组件。至此,Elastic 形成了一个完整的生态链和技术栈,成为大数据市场的佼佼者。
Beats 平台集合了多种单一用途的数据采集器。它们从成百上千台机器和系统向 Logstash 或 Elasticsearch 发送数据。
10.4.1 Beats 简介
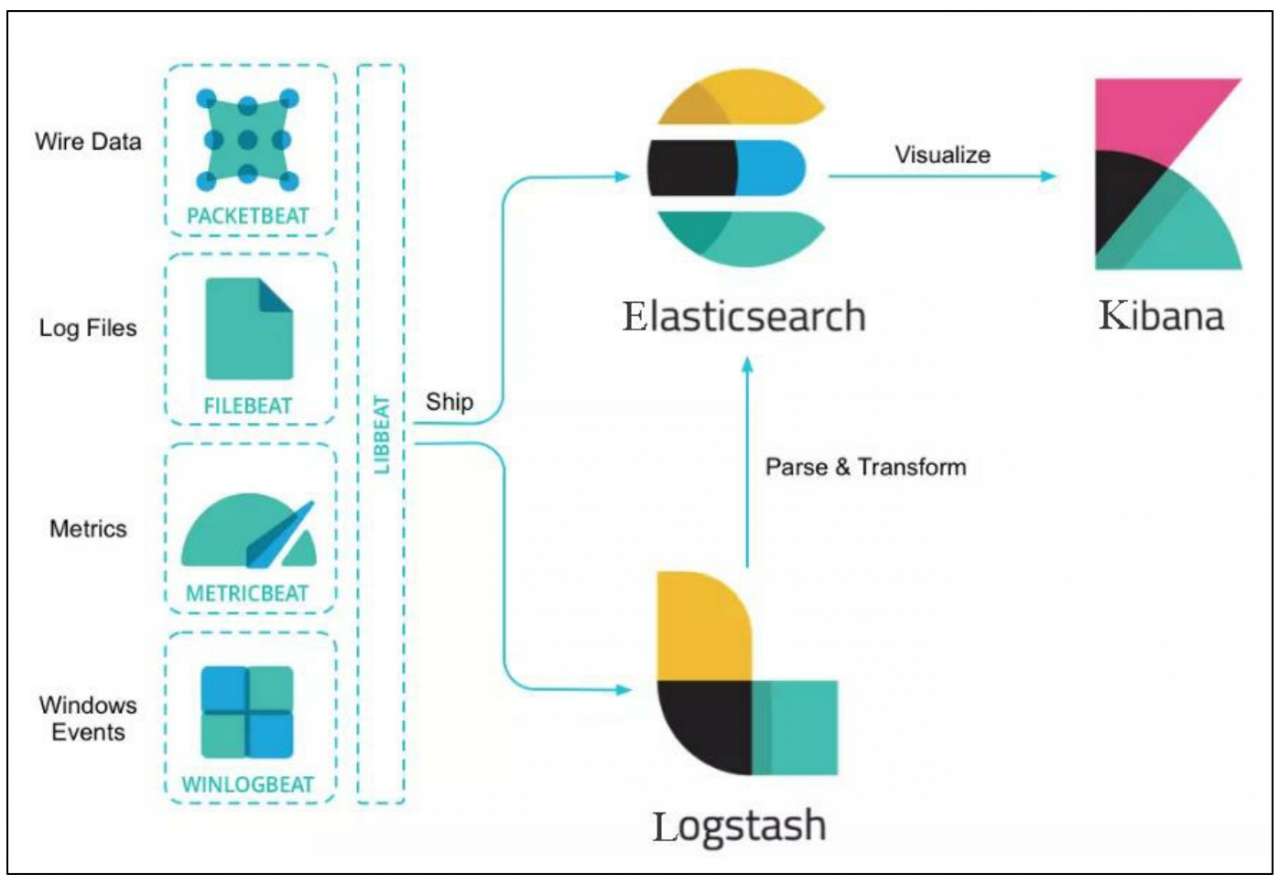
Beats 是一组轻量级采集程序的统称,如图 10-14 所示。

Beats 中包括但不限于以下组件:
(1)Filebeat:该组件会进行文件和目录的采集,主要用于收集日志数据。
(2)Metricbeat:该组件会进行指标采集。这里说的指标可以是系统的,也可以是众多中间件产品的。主要用于监控系统和软件的性能。
(3)Packetbeat:该组件通过网络抓包和协议分析,对一些请求响应式的系统通信进行监控和数据收集,可以收集到很多常规方式无法收集到的信息。
(4)Winlogbeat:该组件专门针对 Windows 的 event log 进行数据采集。
(5)Audibeat:该组件用于审计数据场景,收集审计日志。
(6)Heartbeat:该组件用于系统间连通性检测,如 ICMP、TCP、HTTP 等的连通性监控。
(7)Functionbeat:该组件用于无须服务器的采集器。
以上是 Elastic 官方支持的 7 种组件,事实上,借助于开源的力量,互联网上早已创造出大大小小几十甚至上百种组件,只有我们没想到的,没有 Beats 做不到的。官方不负责维护的 Beats,社区统一称之为 Community Beats。
官方支持的 7 种组件与 ELK 的数据流转关系如图 10-15 所示。
更多组件可以从 Elasticsearch 官网下载。
10.4.2 Beats 轻量级设计的实现
前面提过,Beats 是一组轻量级采集程序的统称,那么 Beats 是如何做到轻量级的呢?
(1)数据处理简单。在数据收集层面,Beats 并不进行过于复杂的数据处理,只是将数据简单的组织并上报给上游系统。
(2)并发性好、便于部署。Beats 采用 Go 语言开发而成。众所周知,Go 语言是一种系统编程语言,能够在不依赖虚拟机的情况下运行,包通常比较小。在跨平台方面,Beats 与 Go 语言保持一致,支持多种操作系统,如 Linux、Windows、FreeBSD 和 macOS。
因此,Beats 的性能显著好于 Logstash。
10.4.3 Beats 的架构
Beats 之所以有上乘的性能及良好的可扩展性,能获得如此强大的开源支持,其根本原因在于它有一套设计良好的代码框架。
Beats 的架构设计如图 10-16 所示。

libbeat 是 Beats 的核心包。
在 Beats 架构中,有输出模块(Publisher)、数据收集模块(Logging)、配置文件模块(Configuration)、日志处理模块和守护进程模块(Daemon/service)。
其中,输出模块负责将收集到的数据发送给 Logstash 或者 Elasticsearch。
因为 Go 语言天然就有 channel,所以收集数据的逻辑代码与输出模块都是通过 channel 通信的。也就是说,两个模块的耦合度最低。因此,当开发一个收集器时,完全不需要知道输出模块的存在,当程序运行时,自然就「神奇」地把数据发往服务端了。
除此之外,配置文件模块、日志处理模块、守护进程模块等功能为开发者扩展 Beats 的功能提供了极大的空间。
10.5 知识点关联
本章主要介绍了 Elasticsearch 的生态圈,不难看出其生态圈十分繁荣。不仅官方在维护 Elasticsearch 的生态,社区技术人员也在积极地贡献自己的力量,正所谓「众人拾柴火焰高」!
而这背后正是生态思维。
在技术圈中,Java 技术栈中的 Spring 生态发展得也是花团锦簇。从 Spring Boot 到 Eureka、Hystrix、Zuul、Archaius、Consul、Sleuth、Spring Cloud ZooKeeper、Feign、Ribbon……终于,以 Spring Boot 为核心的 Spring Cloud 微服务生态建立起来,并持续发展。
安卓系统、微信等也都在积极建立属于自己的生态体系。安卓系统生态中数以万计的开发者贡献了众多的 App。微信在拓展和完善功能的同时,通过小程序的生态打造,连接了众多的线下场景,孕育了无限想象空间。
技术如此,商业如此,同理,技术人员的发展也是如此。
求职之路漫漫,因此在求职或者跳槽时不能光盯着眼前的利益,更要看重未来的个人「生态」:找到适合自己的公司,找到有能力、有意愿、有方法培养自己的领导,找到一群「技术派」的同事,找到一个技术氛围好的团队,等等。