论文链接: https://arxiv.org/pdf/2001.04346.pdf
非对称层次网络与专注的交互为基于可解释评论的推荐
摘要:
最近,通过利用用户提供的评论,推荐系统已经能够产生大幅度改进的推荐。
现有的方法通常将给定用户或项的所有评论合并到一个长文档中,然后以相同的方式处理用户全部评论和项目评论。
然而,在实践中,这两组评论是明显不同的:用户的评论反映了他们购买的各种商品,因此在他们的主题上是非常异质的,而一个商品的评论只适用于那个单一的商品,因此在主题上是同质的。
在这项工作中,我们开发了一个新的神经网络模型,该模型通过不对称的注意力模块恰当地解释了这一重要差异。用户模块学习只关注那些与目标项目相关的信号,而项目模块学习提取与项目的属性有关的最突出的内容。我们的多级范式解释了这样一个事实,即不是所有的评论都一样有用,也不是每个评论中的所有句子都一样相关。在各种真实数据集上的大量实验结果证明了我们的方法的有效性。
- 简介
从传统零售和服务到在线交易的快速转变,在电子商务、餐饮、旅游等许多领域带来了大量的评论数据。虽然消费者经常直接咨询这些评论,并影响他们的决策,但最近的研究表明,算法也可以利用这些评论。它们所隐含的详细语义线索不仅揭示了产品的不同方面(如质量、材料、颜色等),而且反映了用户对这些方面的情感。这种细粒度的信号对于推荐系统来说是非常有价值的,并且极大地补充了稀疏的评级和点击数据,许多传统的协同过滤方法(Koren, Bell, and Volinsky 2009)都是基于此发展起来的。因此,有一系列的研究试图利用评论的潜力来提高推荐质量。
这些研究表明,利用评论确实可以显著提高推荐的有效性。通常,它们将用户与他们编写的各自的评论集相关联,同时将每个条目与为其编写的所有评论集相关联。为了预测看不见的用户-物品对的评价,在第一步中,用户和物品的嵌入将通过神经网络从各自的评论集推断出来。然后,对两个嵌入进行匹配,预测它们之间的数值等级。例如,DeepCoNN (Zheng, Noroozi,和Yu 2017)依赖卷积神经网络来学习用户(项目)的嵌入,并依赖因子分解机器(Rendle 2010)来预测评分。D-ATT (Seo et al. 2017)使用基于双注意的网络来学习嵌入,并使用简单的点积来预测评级。
尽管取得了令人鼓舞的进展,但现有的方法都将用户的历史评论和对项目的评论为相同类型的文档,并调用相同的模型(甚至共享模型)并行地处理它们。然而,实际上,用户的评论集与项目的评论集是完全不同的。特别是,用户的评论对应于他们所评级的一组不同的项目,这导致了明显的异质文本内容,即不同的项目有不同的主题。相反,每个项目的评论都是关于它自己的,因此内容是同质的,主题被限制在一个狭窄的领域。例如,图1显示了来自亚马逊健康领域的一些评论。用户u的历史评论描述了三个项目,维生素C,抗炎药物,和空气清新剂,而所有关于项目v的评论都是关于它本身,即维生素D3。
这种深刻的差异需要不同形式的用户评论上要注意与项目评论,在决定是否向用户u推荐项目v。预测u对v的偏爱,重要的是要从你的评论中选取那些最适合v的方面,例如,提取用户u对与v类似的项目的评论 .
相比之下,对于v收获的评论,我们希望获得其他用户在v上就某些方面的看法。如果u特别关注与v相似的物品的某些方面,而其他用户对v的这些特定方面评价很高,那么v更有可能引起u的兴趣。例如,在图1中, u针对非处方药的评论1和2,提到"不来自转基因玉米","容易吞下","价格便宜","没有味"等方面,说明u考虑来源和价格,偏好易吞咽且无余味的产品。同时,非处方药v收获的评论1-3提到v是"没有味道"、"容易吞咽"、"无转基因"、"价格低",这是其他人表达的符合u偏好的意见。因此,v很可能是u感兴趣的,而u确实在购买后给v打了5.0分。
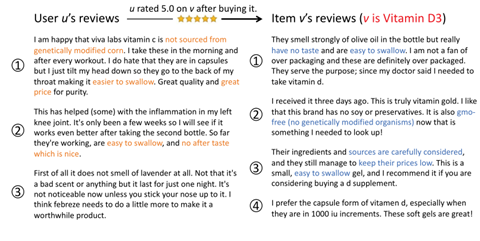
另一个重要的挑战是如何可靠地表示每个评论。重要的是,句子在每个评论中并不同等有用。例如,在图1中,在你的评论1中的第二句,"我在早上和每次锻炼后都做这些。"这句话几乎没有表达出你对维生素C的关注,因此与同一篇评论中的其他句子相比没有那么切题。因为包含不相关的句子会引入噪音,可能会损害最终的嵌入质量,所以只聚集有用的句子来代表每一篇评论是至关重要的。
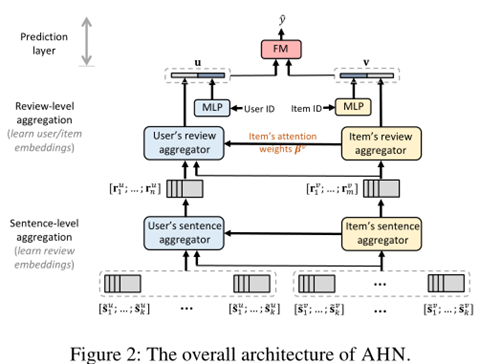
为了解决上述问题,本文提出了一种具有注意交互的非对称层次网络。AHN逐步聚合突出的句子以生成评论表示,并聚合相关的评论以生成用户和项目的表示。AHN的特点是它的非对称注意模块,可以灵活地区分用户嵌入和项目嵌入的学习。对于项目,调用几个注意层来突出显示包含丰富方面和情感信息的句子和评论。对于用户,我们设计了一个基于交互的协同注意力机制来动态选择与当前目标项相关的同构内容子集。通过这种方式,AHN分层引入了用户-项目对的嵌入,反映了个性化推荐最有用的知识。
总之,我们的贡献是
- 我们识别了不对称注意问题,并提出基于评论的建议,这是重要的,但被现有的方法所忽视。
- 我们提出了AHN,一种新的深度学习架构,它不仅捕获了评论数据的不对称和层次特征,同时还支持结果的可解释性。
- 我们在10个真实数据集上进行了实验。结果表明,AHN在提供对预测的良好解释的同时,始终在很大程度上超过了最先进的方法。
- 相关工作
在最近的建议工作中,利用评论已证明相当有用。许多方法主要是基于复习文本的主题建模。例如,HFT (McAuley和Leskovec 2013)使用LDA从评论中发现用户和项目的潜在方面。RMR (Ling, Lyu, and King 2014)从评论中提取主题,通过分解评级矩阵来增强用户和项目嵌入。TopicMF (Bao, Fang, and Zhang 2014)联合对点评的评级矩阵和包词表示进行分解,以推断用户和条目的嵌入情况。尽管已有改进,但这些方法在综述中只关注主题线索,而忽略了丰富的语义内容。此外,它们通常以词包的形式表示评论,因此忽略了评论中单词和句子的顺序和上下文,而这些对于用户和物品的特征建模是至关重要的(Zheng, Noroozi, and Y u 2017)。
受到最近深度NLP技术在各种应用领域惊人进展的启发(Santos等,2016;Wang et al. 2018;彼得斯等人,2018年;Dong和De Melo 2018;Devlin等,2018;Y ang et al. 2019),人们对深度学习模型的研究越来越感兴趣。DeepCoNN (Zheng, Noroozi, and Y u 2017)使用CNNs作为自动特征提取器,通过评估相关的历史评论集,将每个用户和物品编码为低维向量。TransNet (Catherine和Cohen 2017)对DeepCoNN进行了扩展,使用多任务学习方案增强了CNN架构,以规范用户和项目嵌入到目标审查中。然而,这些方法在其结果中缺乏可解释性(Xian et al. 2019)。
为了更好地理解这些预测,一些基于注意力的方法被开发出来。D-A TT (Seo et al. 2017)在评论词上整合了两种注意机制,以发现有信息性的词。NARRE(陈et al . 2018年)调用review-level关注权重总审查嵌入形成用户(项目)embeddings.HUITA (Wuetal.2019) isequippedwithasymmetric层次结构,每一层(例如,字级别),定期关注机制被用来推断表示后续的水平(例如,句子级别)。MPCN (Tay, Luu, and Hui 2018)通过Gumbel-Softmax技巧学到的基于共同注意力的指针,模拟用户评论和物品评论之间的互动(Jang, Gu, and Poole 2016)。然而,所有这些方法都只是并行地学习用户嵌入和条目嵌入,而没有考虑到两者之间的重要区别。如前所述,这会导致次优预测。
与前面提到的方法不同,我们的方法学习了几个层次聚合器来推断用户(项目)的嵌入。聚合器是不对称的,灵活地对用户(项目)的评论给予不同程度的关注,从而提高预测的准确性和模型的可解释性。
- 模型
在本节中,我们将以自底向上的方式介绍我们的AHN模型。图2说明了AHN的体系结构。
3.1 句子编码
Word2vec的表述:
句子编码层(图2中省略)的目的是将每个句子(在每篇评论中)从一个离散的单词标记序列转换为一个连续的嵌入向量。
我们使用一个词嵌入模型来奠定这一层的基础。假设句子s有l个单词。利用单词嵌入矩阵E∈Rd×|V|, s可以表示为一个序列[e1,…,el],其中ei是嵌入s中的第i个单词,d是嵌入单词的维数,V是单词的整个词汇表。矩阵E可以使用word embedding进行初始化,如word2vec (Mikolov et al. 2013)和GloV E (Pennington, Socher, and Manning 2014),它们在NLP中被广泛使用。为了细化单词embeddings, E在模型训练期间进行了微调。
为了学习s的嵌入,我们在其组成词的嵌入上使用了双向LSTM (Peters et al. 2018),并在隐藏状态上应用max-pooling来保存信息最为充分的信息。
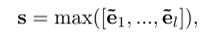
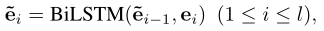
˜e0是初始化的零向量。
假设评论有k个句子。然后我们可以用序列[s1,…,如Eq.(1)所示,其中sionly是将第i个句子嵌入到复习中。然而,使用Eq.(1),每个sionly编码自己的语义意义,但在同一复习中仍然忽略周围句子的上下文线索。为了进一步细化句子嵌入,我们引入了一个上下文编码层,在前一层之上使用另一个双向LSTM来建模句子之间的时间交互,即:
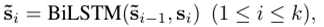
˜s0是初始化的零向量。
3.2 语句级聚合Sentence-Level Aggregation
接下来,我们开发句子级聚合器,将每个评论从其组成的句子嵌入到一个紧凑的向量中。如前所述,一个理想的方法应该以非对称风格学习评论嵌入。因此,我们设计了AHN来分别为用户和项目学习不同的注意力聚合器,如图2所示。
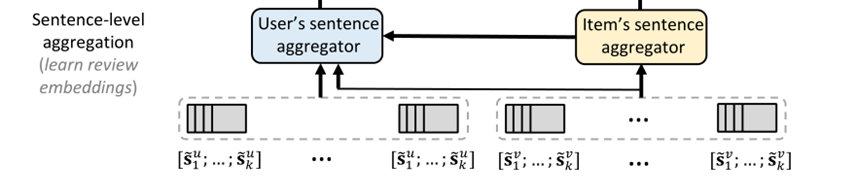
项目角度
对于一个项目,我们感兴趣的句子包含了其他用户对该项目不同方面的看法,这是决定其总体评价的关键因素。
建立一个对每个评审信息嵌入在这些句子,我们使用一个句子级别的关注网络聚合句子嵌入[˜sv1,……˜svk],如下所示,上标v是用来区分一个项目从用户的符号表示法。

α的和是1,为attention权重。
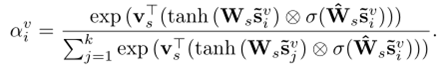
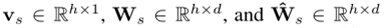
在[−1,1]中tanh(·)的近似线性会限制模型的表达性,可以通过引入非线性门控机制来缓解这一问题:即
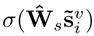
用户角度attention
接下来,我们为用户开发了一个基于交互的句子聚合器。给定一个user - item对,我们的目标是从每个用户的评论中选择一个同构的句子子集,以便所选的句子与要推荐的项目相关,即目标项目。下面我们介绍一个共同注意力网络,它利用目标项的句子来引导用户的句子搜索。
句子编码层后,我们可以通过一个矩阵表示每个评论R =[˜s1,……,˜sk] ∈Rd×k, [·;·]为连接操作。
针对某个项目的m篇评论,我们获得项目的表示如下,其组成的句子都与目标项相关,从而可以引导用户从评论中搜索相似的句子。
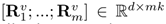
然后,针对一个用户的n篇评论,分别生成和项目的相关性矩阵:
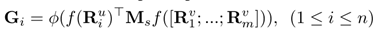
Ms是参数矩阵;最外层是激活函数层relu;f( )是多层感知机等映射函数。第i个相关性矩阵Gi的(p,q)代表用户u的第i篇评论的第p个句子和项目v的所有评论的第q个句子。
为了衡量用户评论Rui的第p个句子与目标项目的相关性,我们使用Gi第p行中的最大值。
直觉是,如果用户的句子(即Gi的一行)与目标项目有很大关联,则至少与目标项目的一个句子关联度很高(例如,一列Gi)
然而,并不是所有目标项目的句子都对从用户那里搜索相关句子有用。例如,在图1中,项目的评论2的第一句话,"I received it three days ago.",传达的目标项目的信息很少,不能帮助用户识别相关的句子,而且可能会在关联矩阵中引入噪声。为了解决这个问题,回想一下Eq.(5)的αvi表示一个项目的句子的信息量的大小。因此,我们将目标项目的所有句子的次序列v i串联起来,形成了次序列v∈R1×mk。随后,我们计算每一行之间的以聪明元素产品Giand向量αv,即,Gi⊗行αv。通过这种方式,(p, q) th条目,(Gi⊗行αv) pq,高只有用户的对句类似于q-th句子的目标项目和目标项目的q-th句子是不平凡的。
然后与用户u的第i篇评论的相关度矩阵Gi的每一行点乘:
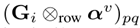
上式代表用户的第p个评论与项目的第q个评论的相关度,经过下一步处理即可获得attention
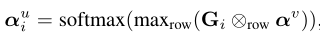
上式代表:用户u的第i篇的attention权重。maxrow代表行方向上的最大池化,获得用户的某个句子与项目描述的最大关联。