Ganin Y. and Lempitsky V. Unsupervised Domain Adaptation by Backpropagation. ICML 2015.
概
监督学习非常依赖标签数据, 但是获得大量的标签数据在现实中是代价昂贵的一件事情, 这也是为何半监督和无监督重要的原因.
本文提出一种利用GRL来进行domain adaptation的方法, 感觉本文的创新点还是更加偏重于结构一点.
主要内容
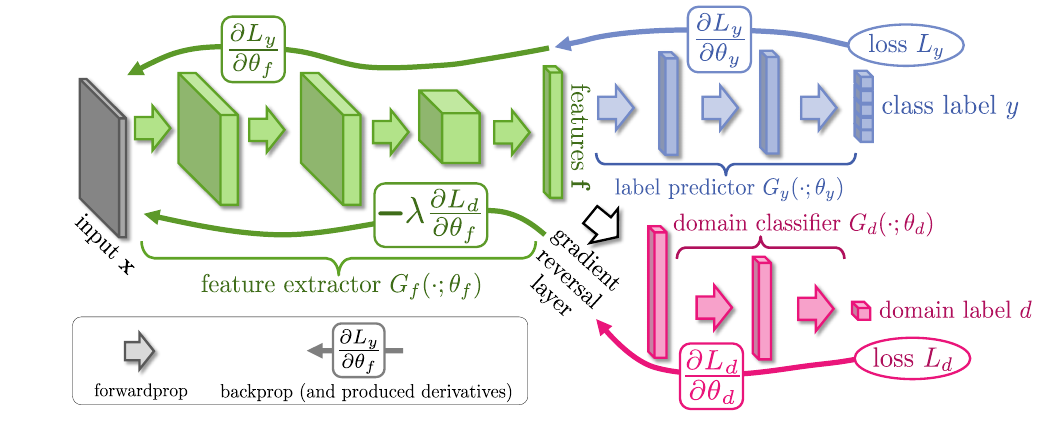
接下来的叙述的方式可能和原文的有一点点的出入.
首先整个网络的框架包括一个用于提取特征的(G_f), 可见其是共享的, 提取的到的特征会分别进入上下两个(G_c, G_d).
其中, (G_c) 是普通的分类器, 当然这要求最开始的输入我们是有对应的标签的, (G_f + G_c)也就是我们最后所需要的整个网络.
而(G_d)的最后是一个二分类器, 用于区别输入的样本是来自有标签的数据集还是目标数据集.
我们来看一下损失
[sum_{i=1cdots N, d_i=0} mathcal{L}_y^i ( heta_f, heta_c) + lambda cdot sum_{i=1cdots N} mathcal{L}_{d}^i ( heta_f, heta_d)
]
首先关于(G_f, G_c)最小化(mathcal{L}_y), 关于(G_d)则是最小化(mathcal{L}_d), 同时关于(G_f)最大化(mathcal{L}_d).
直观上讲就是, 我们要求(G_f)提取的特征使得分类器能够区分出输入的类别, 而下半部分则是一种对抗的思想, (G_f)提取的特征希望(G_d)不能够区别出输入来自有标签的域还是目标域, 对应的(G_d)是努力去区别开来.
为了实现这一点, 本文利用了一种GRL的技术, 即梯度从(G_d)回传到(G_f)的时候会变换梯度的方向.
代码
import torch
from torch.autograd import Function
class RevGrad(Function):
@staticmethod
def forward(ctx, inputs):
return inputs
@staticmethod
def backward(ctx, grad_outputs):
return grad_outputs.neg()