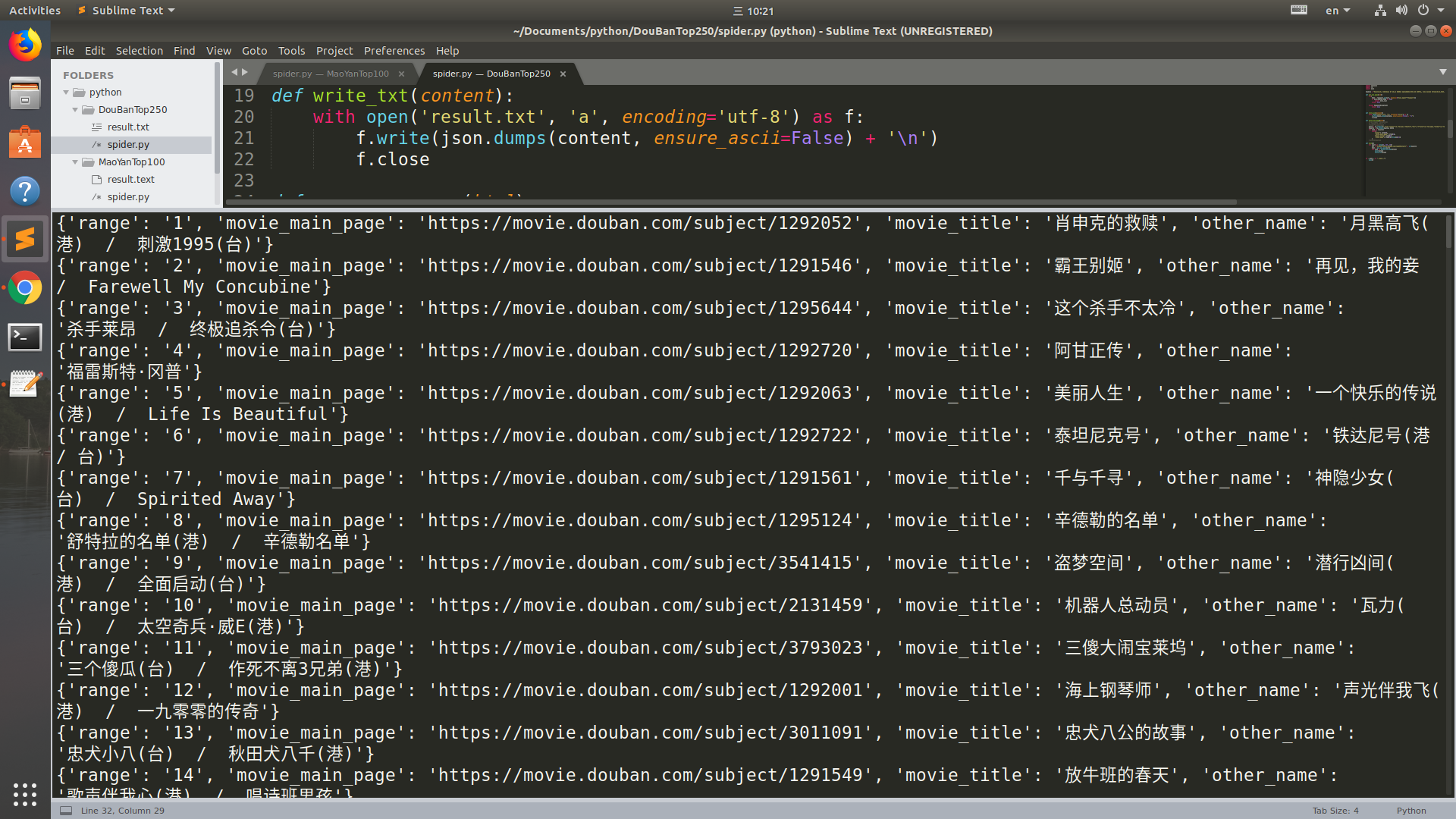
一样的套路,就是多线程还没弄
1 import requests 2 import re 3 import json 4 5 headers = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36' 6 7 def get_one_page(url): 8 try: 9 html = requests.get(url, headers={'User-Agent':'headers'}) 10 if html.status_code == 200: 11 return html.text 12 return None 13 14 except RequestsException: 15 return None 16 17 18 19 def write_txt(content): 20 with open('result.txt', 'a', encoding='utf-8') as f: 21 f.write(json.dumps(content, ensure_ascii=False) + ' ') 22 f.close 23 24 def parse_one_page(html): 25 # <em class="">(d+)</em> 26 # .*?href="(.*?)/">.*? 27 # other">(w+)</span 28 match = re.compile('.*?<em class="">(.*?)</em>.*?href="(.*?)/">.*?"title">(.*?)</span.*?other">(.*?)</span', re.S) 29 results = re.findall(match, html) 30 for item in results: 31 yield{ 32 'range': item[0], 33 'movie_main_page': item[1], 34 'movie_title': item[2], 35 'other_name': item[3].strip()[13:] 36 } 37 # print(results) 38 39 def main(): 40 for start in range(0, 250, 25): 41 url = 'https://movie.douban.com/top250?start=' + str(start) 42 html = get_one_page(url) 43 for item in parse_one_page(html): 44 print(item) 45 write_txt(item) 46 47 48 49 if __name__ == '__main__': 50 main()
运行结果