第1章 Flink简介
1.1 初识Flink
Flink起源于Stratosphere项目,Stratosphere是在2010~2014年由3所地处柏林的大学和欧洲的一些其他的大学共同进行的研究项目,2014年4月Stratosphere的代码被复制并捐赠给了Apache软件基金会,参加这个孵化项目的初始成员是Stratosphere系统的核心开发人员,2014年12月,Flink一跃成为Apache软件基金会的顶级项目。
在德语中,Flink一词表示快速和灵巧,项目采用一只松鼠的彩色图案作为logo,这不仅是因为松鼠具有快速和灵巧的特点,还因为柏林的松鼠有一种迷人的红棕色,而Flink的松鼠logo拥有可爱的尾巴,尾巴的颜色与Apache软件基金会的logo颜色相呼应,也就是说,这是一只Apache风格的松鼠。

Flink项目的理念是:“Apache Flink是为分布式、高性能、随时可用以及准确的流处理应用程序打造的开源流处理框架”。
Apache Flink是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算。Flink被设计在所有常见的集群环境中运行,以内存执行速度和任意规模来执行计算。

1.2 Flink的重要特点
1.2.1 事件驱动型(Event-driven)
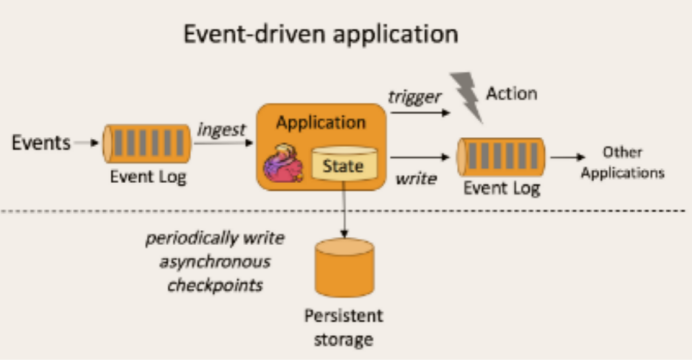
事件驱动型应用是一类具有状态的应用,它从一个或多个事件流提取数据,并根据到来的事件触发计算、状态更新或其他外部动作。比较典型的就是以kafka为代表的消息队列几乎都是事件驱动型应用。(Flink的计算也是事件驱动型)
与之不同的就是SparkStreaming微批次,如图:
 事件驱动型,如图:
事件驱动型,如图:
1.2.2 流(flink)与批(spark)的世界观
批处理的特点是有界、大量,非常适合需要访问全套记录才能完成的计算工作,一般用于离线统计。
流处理的特点是无界、实时, 无需针对整个数据集执行操作,而是对通过系统传输的每个数据项执行操作,一般用于实时统计。
在spark的世界观中,一切都是由批次组成的,离线数据是一个大批次,而实时数据是由一个一个无限的小批次组成的。而在flink的世界观中,一切都是由流组成的,离线数据是有界限的流,实时数据是一个没有界限的流,这就是所谓的有界流和无界流。
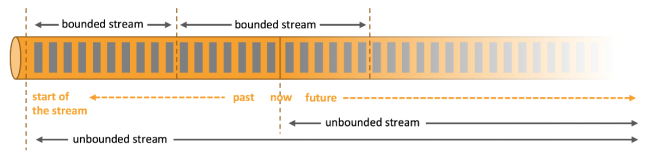
无界数据流:
无界数据流有一个开始但是没有结束,它们不会在生成时终止并提供数据,必须连续处理无界流,也就是说必须在获取后立即处理event。对于无界数据流我们无法等待所有数据都到达,因为输入是无界的,并且在任何时间点都不会完成。处理无界数据通常要求以特定顺序(例如事件发生的顺序)获取event,以便能够推断结果完整性。
有界数据流:
有界数据流有明确定义的开始和结束,可以在执行任何计算之前通过获取所有数据来处理有界流,处理有界流不需要有序获取,因为可以始终对有界数据集进行排序,有界流的处理也称为批处理。
1.2.3 分层API

最底层级的抽象仅仅提供了有状态流,它将通过过程函数(Process Function)被嵌入到DataStream API中。底层过程函数(Process Function) 与 DataStream API 相集成,使其可以对某些特定的操作进行底层的抽象,它允许用户可以自由地处理来自一个或多个数据流的事件,并使用一致的容错的状态。除此之外,用户可以注册事件时间并处理时间回调,从而使程序可以处理复杂的计算。
实际上,大多数应用并不需要上述的底层抽象,而是针对核心API(Core APIs) 进行编程,比如DataStream API(有界或无界流数据)以及DataSet API(有界数据集)。这些API为数据处理提供了通用的构建模块,比如由用户定义的多种形式的转换(transformations),连接(joins),聚合(aggregations),窗口操作(windows)等等。DataSet API 为有界数据集提供了额外的支持,例如循环与迭代。这些API处理的数据类型以类(classes)的形式由各自的编程语言所表示。
Table API 是以表为中心的声明式编程,其中表可能会动态变化(在表达流数据时)。Table API遵循(扩展的)关系模型:表有二维数据结构(schema)(类似于关系数据库中的表),同时API提供可比较的操作,例如select、project、join、group-by、aggregate等。Table API程序声明式地定义了什么逻辑操作应该执行,而不是准确地确定这些操作代码的看上去如何。
尽管Table API可以通过多种类型的用户自定义函数(UDF)进行扩展,其仍不如核心API更具表达能力,但是使用起来却更加简洁(代码量更少)。除此之外,Table API程序在执行之前会经过内置优化器进行优化。
你可以在表与 DataStream/DataSet 之间无缝切换,以允许程序将 Table API 与 DataStream 以及 DataSet 混合使用。
Flink提供的最高层级的抽象是 SQL 。这一层抽象在语法与表达能力上与 Table API 类似,但是是以SQL查询表达式的形式表现程序。SQL抽象与Table API交互密切,同时SQL查询可以直接在Table API定义的表上执行。
目前Flink作为批处理还不是主流,不如Spark成熟,所以DataSet使用的并不是很多。Flink Table API和Flink SQL也并不完善,大多都由各大厂商自己定制。所以我们主要学习DataStream API的使用。实际上Flink作为最接近Google DataFlow模型的实现,是流批统一的观点,所以基本上使用DataStream就可以了。
2020年12月8日发布的1.12.0版本, 已经完成实现了真正的流批一体. 写好的一套代码, 即可以处理流式数据, 也可以处理离线数据. 这个与前面版本的处理有界流的方式是不一样的, Flink专门对批处理数据做了优化处理.
目前最新版本是2021年5月28日发布最新稳定版本为:1.13.1
1.3 Spark or Flink
Spark 和 Flink 一开始都拥有着同一个梦想,他们都希望能够用同一个技术把流处理和批处理统一起来,但他们走了完全不一样的两条路前者是以批处理的技术为根本,并尝试在批处理之上支持流计算;后者则认为流计算技术是最基本的,在流计算的基础之上支持批处理。正因为这种架构上的不同,今后二者在能做的事情上会有一些细微的区别。比如在低延迟场景,Spark 基于微批处理的方式需要同步会有额外开销,因此无法在延迟上做到极致。在大数据处理的低延迟场景,Flink 已经有非常大的优势。
Spark和Flink的主要差别就在于计算模型不同。Spark采用了微批处理模型,而Flink采用了基于操作符的连续流模型。因此,对Apache Spark和Apache Flink的选择实际上变成了计算模型的选择,而这种选择需要在延迟、吞吐量和可靠性等多个方面进行权衡。
如果企业中非要技术选型从Spark和Flink这两个主流框架中选择一个来进行流数据处理,我们推荐使用Flink,主(显而)要(易见)的原因为:
1)Flink灵活的窗口
2)Exactly Once语义保证
3)事件时间(event-time)语义(处理乱序数据或者延迟数据)
1.4 Flink的应用
1.4.1 应用Flink的场景
事件驱动型应用
事件驱动型应用是一类具有状态的应用,它从一个或多个事件流提取数据,并根据到来的事件触发计算、状态更新或其他外部动作。事件驱动型应用是在计算存储分离的传统应用基础上进化而来。在传统架构中,应用需要读写远程事务型数据库。相反,事件驱动型应用是基于状态化流处理来完成。在该设计中,数据和计算不会分离,应用只需访问本地(内存或磁盘)即可获取数据。系统容错性的实现依赖于定期向远程持久化存储写入 checkpoint。下图描述了传统应用和事件驱动型应用架构的区别。

事件驱动型应用无须查询远程数据库,本地数据访问使得它具有更高的吞吐和更低的延迟。而由于定期向远程持久化存储的 checkpoint 工作可以异步、增量式完成,因此对于正常事件处理的影响甚微。事件驱动型应用的优势不仅限于本地数据访问。传统分层架构下,通常多个应用会共享同一个数据库,因而任何对数据库自身的更改(例如:由应用更新或服务扩容导致数据布局发生改变)都需要谨慎协调。反观事件驱动型应用,由于只需考虑自身数据,因此在更改数据表示或服务扩容时所需的协调工作将大大减少。
数据分析应用
Apache Flink 同时支持流式及批量分析应用。
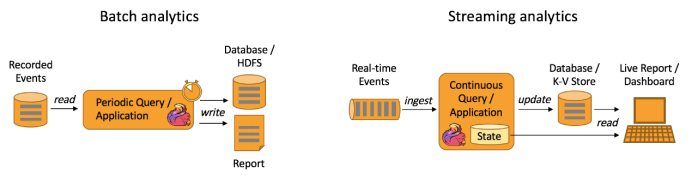
Flink 为持续流式分析和批量分析都提供了良好的支持。具体而言,它内置了一个符合 ANSI 标准的 SQL 接口,将批、流查询的语义统一起来。无论是在记录事件的静态数据集上还是实时事件流上,相同 SQL 查询都会得到一致的结果。同时 Flink 还支持丰富的用户自定义函数,允许在 SQL 中执行定制化代码。如果还需进一步定制逻辑,可以利用 Flink DataStream API 和 DataSet API 进行更低层次的控制。此外,Flink 的 Gelly 库为基于批量数据集的大规模高性能图分析提供了算法和构建模块支持。
数据管道应用
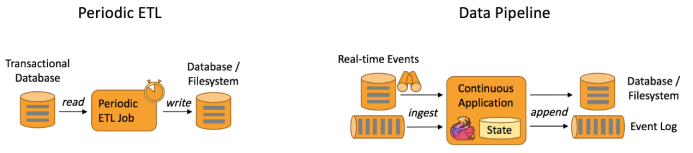
提取-转换-加载(ETL)是一种在存储系统之间进行数据转换和迁移的常用方法。ETL 作业通常会周期性地触发,将数据从事务型数据库拷贝到分析型数据库或数据仓库。数据管道和 ETL 作业的用途相似,都可以转换、丰富数据,并将其从某个存储系统移动到另一个。但数据管道是以持续流模式运行,而非周期性触发。因此它支持从一个不断生成数据的源头读取记录,并将它们以低延迟移动到终点。例如:数据管道可以用来监控文件系统目录中的新文件,并将其数据写入事件日志;另一个应用可能会将事件流物化到数据库或增量构建和优化查询索引。下图描述了周期性 ETL 作业和持续数据管道的差异:
1.4.2 应用Flink的行业
电商和市场营销
数据报表、广告投放
物联网(IOT)
传感器实时数据采集和显示、实时报警,交通运输业
物流配送和服务业
订单状态实时更新、通知信息推送、电信业基站流量调配
银行和金融业
实时结算和通知推送,实时检测异常行为
1.4.3 应用Flink的企业

第2章 Flink快速上手
2.1 创建maven项目
1)资料下载:
2)POM文件中添加需要的依赖:
<properties> <flink.version>1.13.1</flink.version> <scala.binary.version>2.12</scala.binary.version> <slf4j.version>1.7.30</slf4j.version> </properties> <dependencies> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-java</artifactId> <version>${flink.version}</version> <scope>provided</scope> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-streaming-java_${scala.binary.version}</artifactId> <version>${flink.version}</version> <scope>provided</scope> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-clients_${scala.binary.version}</artifactId> <version>${flink.version}</version> <scope>provided</scope> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-runtime-web_${scala.binary.version}</artifactId> <version>${flink.version}</version> <scope>provided</scope> </dependency> <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-api</artifactId> <version>${slf4j.version}</version> <scope>provided</scope> </dependency> <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-log4j12</artifactId> <version>${slf4j.version}</version> <scope>provided</scope> </dependency> <dependency> <groupId>org.apache.logging.log4j</groupId> <artifactId>log4j-to-slf4j</artifactId> <version>2.14.0</version> <scope>provided</scope> </dependency> </dependencies> <build> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-shade-plugin</artifactId> <version>3.2.4</version> <executions> <execution> <phase>package</phase> <goals> <goal>shade</goal> </goals> <configuration> <artifactSet> <excludes> <exclude>com.google.code.findbugs:jsr305</exclude> <exclude>org.slf4j:*</exclude> <exclude>log4j:*</exclude> </excludes> </artifactSet> <filters> <filter> <!-- Do not copy the signatures in the META-INF folder. Otherwise, this might cause SecurityExceptions when using the JAR. --> <artifact>*:*</artifact> <excludes> <exclude>META-INF/*.SF</exclude> <exclude>META-INF/*.DSA</exclude> <exclude>META-INF/*.RSA</exclude> </excludes> </filter> </filters> <transformers combine.children="append"> <transformer implementation="org.apache.maven.plugins.shade.resource.ServicesResourceTransformer"> </transformer> </transformers> </configuration> </execution> </executions> </plugin> </plugins> </build>
3)src/main/resources添加文件:log4j.properties
log4j.rootLogger=error, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%-4r [%t] %-5p %c %x - %m%n
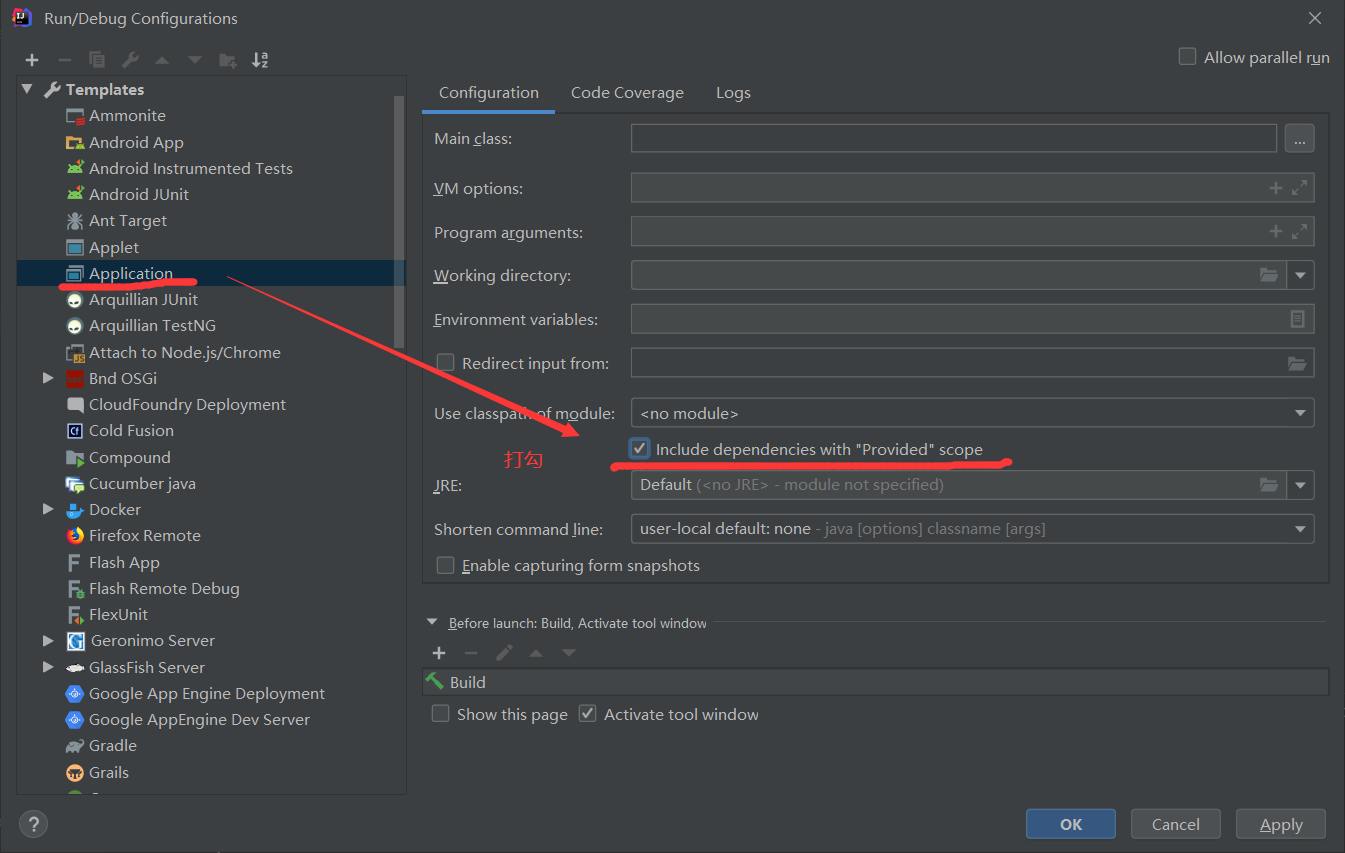
4)配置idea, 运行的时候包括provided scope
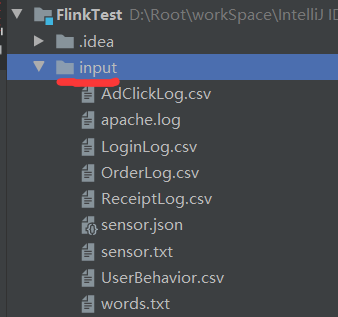
5)在项目根目录下创建input文件夹,将数据上传到该文件夹中
2.2 批处理WordCount
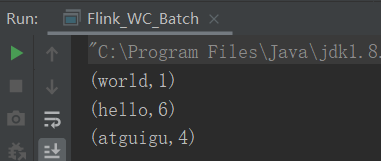
package com.yuange.flink.day01; import org.apache.flink.api.common.functions.FlatMapFunction; import org.apache.flink.api.common.functions.MapFunction; import org.apache.flink.api.java.ExecutionEnvironment; import org.apache.flink.api.java.operators.*; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.util.Collector; /** * @作者:袁哥 * @时间:2021/7/14 11:14 */ public class Flink_WC_Batch { public static void main(String[] args) throws Exception { //创建执行环境 ExecutionEnvironment executionEnvironment = ExecutionEnvironment.getExecutionEnvironment(); //从source读取数据得到DataSet DataSource<String> stringDataSource = executionEnvironment.readTextFile("input/words.txt"); //对数据集做各种操作 FlatMapOperator<String, String> wordsSet = stringDataSource.flatMap(new FlatMapFunction<String, String>() { @Override public void flatMap(String line, Collector<String> collector) throws Exception { String[] s = line.split(" "); for (String word : s) { collector.collect(word); } } }); MapOperator<String, Tuple2<String, Long>> wordAndOneSet = wordsSet.map(new MapFunction<String, Tuple2<String, Long>>() { @Override public Tuple2<String, Long> map(String word) throws Exception { return Tuple2.of(word, 1L); } }); UnsortedGrouping<Tuple2<String, Long>> groupSet = wordAndOneSet.groupBy(0); AggregateOperator<Tuple2<String, Long>> sum = groupSet.sum(1); sum.print(); } }
2.3 流处理WordCount
2.3.1 有界流
package com.yuange.flink.day01; import org.apache.flink.api.common.functions.FlatMapFunction; import org.apache.flink.api.common.functions.MapFunction; import org.apache.flink.api.java.functions.KeySelector; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.util.Collector; /** * @作者:袁哥 * @时间:2021/7/14 19:08 */ public class Flink_WC_Bounded { public static void main(String[] args) throws Exception { //获取流的执行环境 StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment(); //设置并行度 environment.setParallelism(1); //从数据源获取一个流并对流做各种转换 SingleOutputStreamOperator<Tuple2<String, Long>> sum = environment .readTextFile("input/words.txt") .flatMap(new FlatMapFunction<String, String>() { @Override public void flatMap(String line, Collector<String> collector) throws Exception { for (String word : line.split(" ")) { collector.collect(word); } } }) .map(new MapFunction<String, Tuple2<String, Long>>() { @Override public Tuple2<String, Long> map(String s) throws Exception { return Tuple2.of(s, 1L); } }) .keyBy(new KeySelector<Tuple2<String, Long>, String>() { @Override public String getKey(Tuple2<String, Long> stringLongTuple2) throws Exception { return stringLongTuple2.f0; } }) .sum(1); //打印 sum.print(); //启动执行环境 environment.execute(); } }
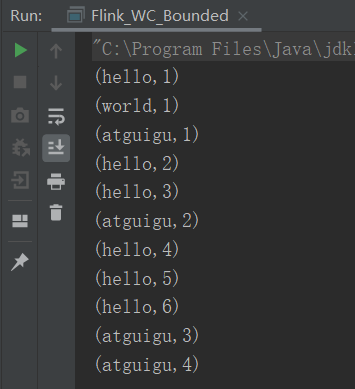
2.3.2 无界流
package com.yuange.flink.day01; import org.apache.flink.api.common.functions.FlatMapFunction; import org.apache.flink.api.common.functions.MapFunction; import org.apache.flink.api.java.functions.KeySelector; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.util.Collector; /** * @作者:袁哥 * @时间:2021/7/14 19:20 */ public class Flink_WC_UnBounded { public static void main(String[] args) throws Exception { //获取流的执行环境 StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment(); environment.setParallelism(1); // 从数据源获取一个流并对流做各种转换 SingleOutputStreamOperator<Tuple2<String, Long>> sum = environment.socketTextStream("hadoop164", 8888) .flatMap(new FlatMapFunction<String, String>() { @Override public void flatMap(String line, Collector<String> collector) throws Exception { for (String word : line.split(" ")) { collector.collect(word); } } }) .map(new MapFunction<String, Tuple2<String, Long>>() { @Override public Tuple2<String, Long> map(String s) throws Exception { return Tuple2.of(s, 1L); } }) .keyBy(new KeySelector<Tuple2<String, Long>, String>() { @Override public String getKey(Tuple2<String, Long> stringLongTuple2) throws Exception { return stringLongTuple2.f0; } }) .sum(1); //打印 sum.print(); //启动执行程序 environment.execute(); } }

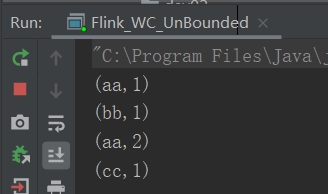
2.3.3 无界流(lambda表达式)
package com.yuange.flink.day01; import org.apache.flink.api.common.typeinfo.Types; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.util.Collector; /** * @作者:袁哥 * @时间:2021/7/14 19:32 */ public class Flink_WC_UnBounded_Lambda { public static void main(String[] args) throws Exception { //获取流的执行环境 StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment(); environment.setParallelism(1); //从数据源获取一个流并对流做各种转换 SingleOutputStreamOperator<Tuple2<String, Long>> sum = environment.socketTextStream("hadoop164", 8888) .flatMap((String line, Collector<String> collects) -> { for (String word : line.split(" ")) { collects.collect(word); } }) .returns(Types.STRING) .map(word -> Tuple2.of(word, 1L)) .returns(Types.TUPLE(Types.STRING, Types.LONG)) .keyBy(t -> t.f0) .sum(1); //打印 sum.print(); //启动执行环境 environment.execute(); } }

第3章 Flink部署
3.1 开发模式
在idea中运行Flink程序的方式就是开发模式
3.2 local-cluster模式
Flink中的Local-cluster(本地集群)模式,主要用于测试, 学习
3.2.1 local-cluster模式配置
local-cluster模式基本属于零配置:
1)上传Flink的安装包flink-1.13.1-bin-scala_2.12.tgz到hadoop164 的 /opt/software

2)解压文件至/opt/module 目录下
tar -zxvf /opt/software/flink-1.13.1-bin-scala_2.12.tgz -C /opt/module/
3)进入目录/opt/module, 复制flink-local
cd /opt/module
cp -r flink-1.13.1 flink-local
3.2.2 在local-cluster模式下运行无界的WordCount
1)打包idea中的应用
2)把不带依赖的jar包上传到目录/opt/module/flink-local下
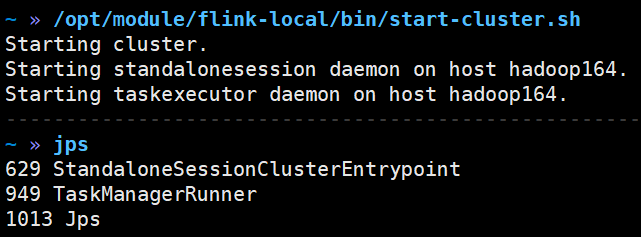
3)启动本地集群
/opt/module/flink-local/bin/start-cluster.sh
4)在hadoop164中启动netcat(如果没有安装netcat需要先安装: sudo yum install -y nc)
nc -lk 8888
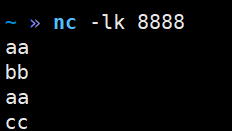
5)命令行提交Flink应用
/opt/module/flink-local/bin/flink run -m hadoop164:8081 -c com.yuange.flink.day01.Flink_WC_UnBounded_Lambda /opt/module/flink-local/FlinkTest-1.0-SNAPSHOT.jar
6)在浏览器中查看应用执行情况:http://hadoop164:8081

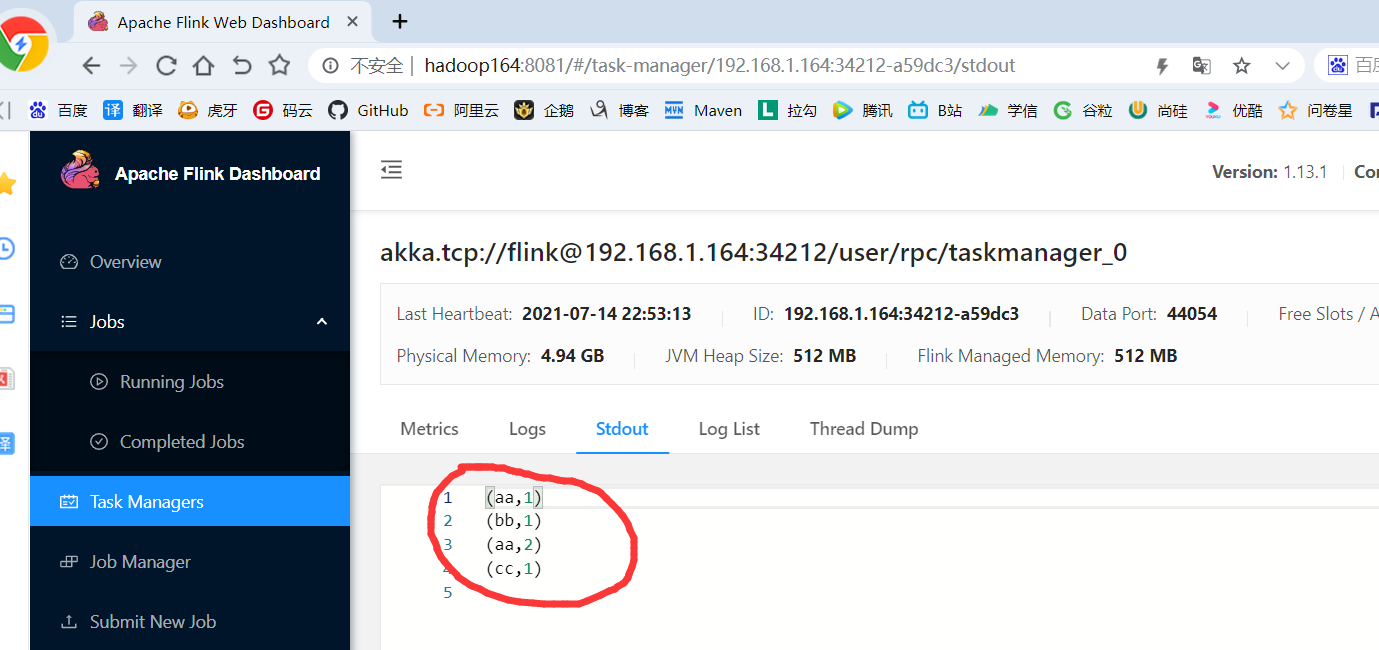
7)也可以在log日志查看执行结果
cat flink-atguigu-taskexecutor-0-hadoop164.out
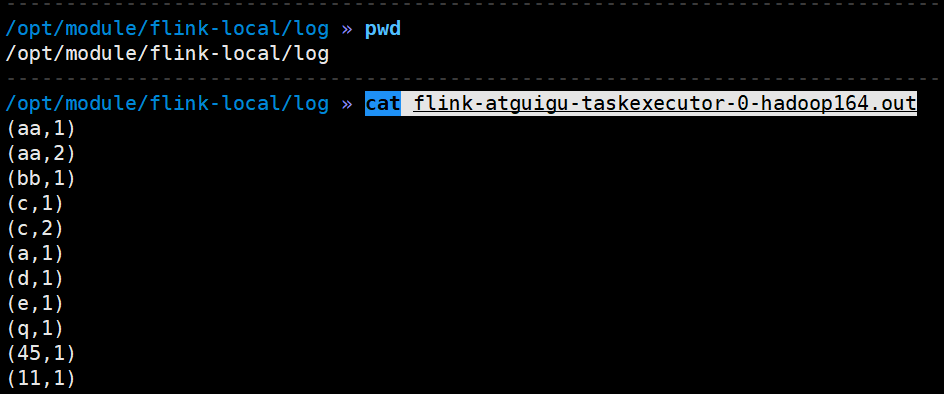
8)也可以在WEB UI提交应用
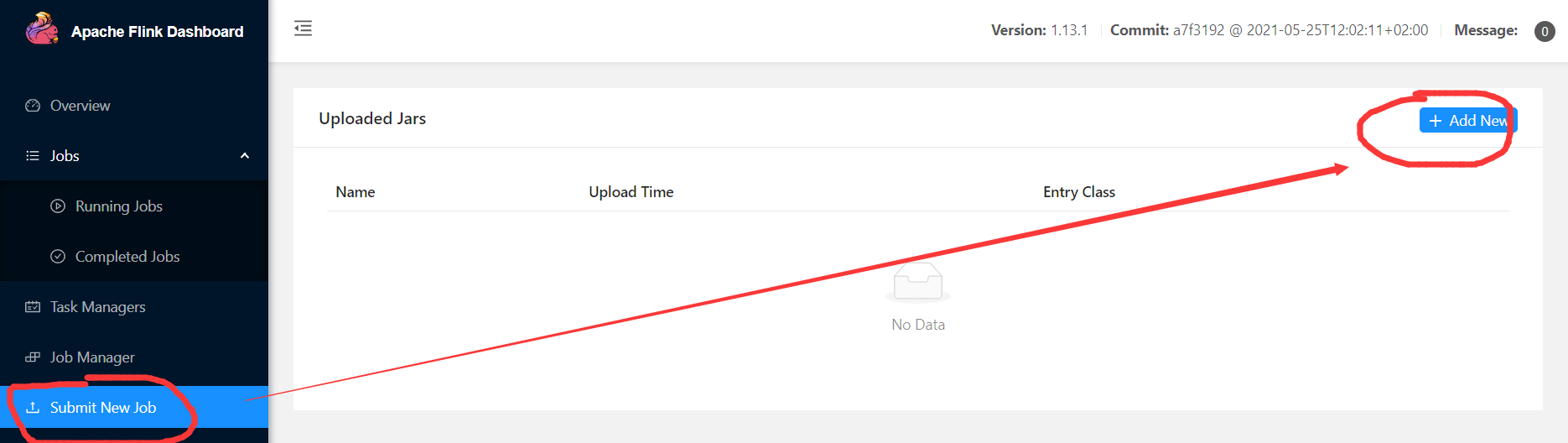

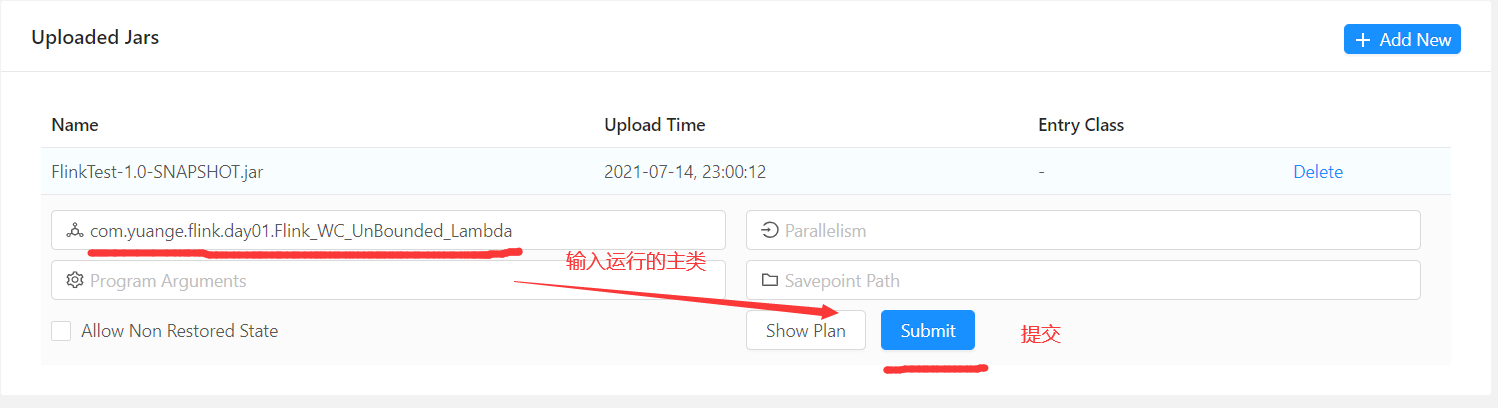
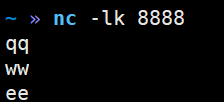
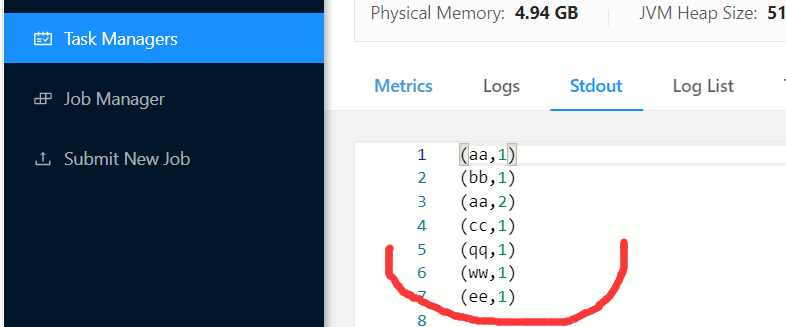
3.3 Standalone模式
Standalone模式又叫独立集群模式.
3.3.1 Standalone模式配置
1)复制flink-standalone
cp -r /opt/module/flink-1.13.1 /opt/module/flink-standalone
2)修改配置文件:flink-conf.yaml
vim /opt/module/flink-standalone/conf/flink-conf.yaml
jobmanager.rpc.address: hadoop164
3)修改配置文件:workers
vim /opt/module/flink-standalone/conf/workers
hadoop162
hadoop164
4)分发flink-standalone到其他节点(再次之前需要将hadoop162中的/home/atguigu/bin目录分发,里面存放的是各种脚本)
xsync /opt/module/flink-standalone
5)启动standalone集群
/opt/module/flink-standalone/bin/start-cluster.sh

3.3.2 Standalone模式运行无界流WorkCount
1)上传Idea中的Jar包至/opt/module/flink-standalone
2)开启8888端口
nc -lk 8888
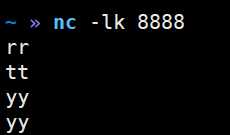
2)命令行提交Flink应用
/opt/module/flink-standalone/bin/flink run -m hadoop164:8081 -c com.yuange.flink.day01.Flink_WC_UnBounded_Lambda /opt/module/flink-standalone/FlinkTest-1.0-SNAPSHOT.jar
3)查看执行情况
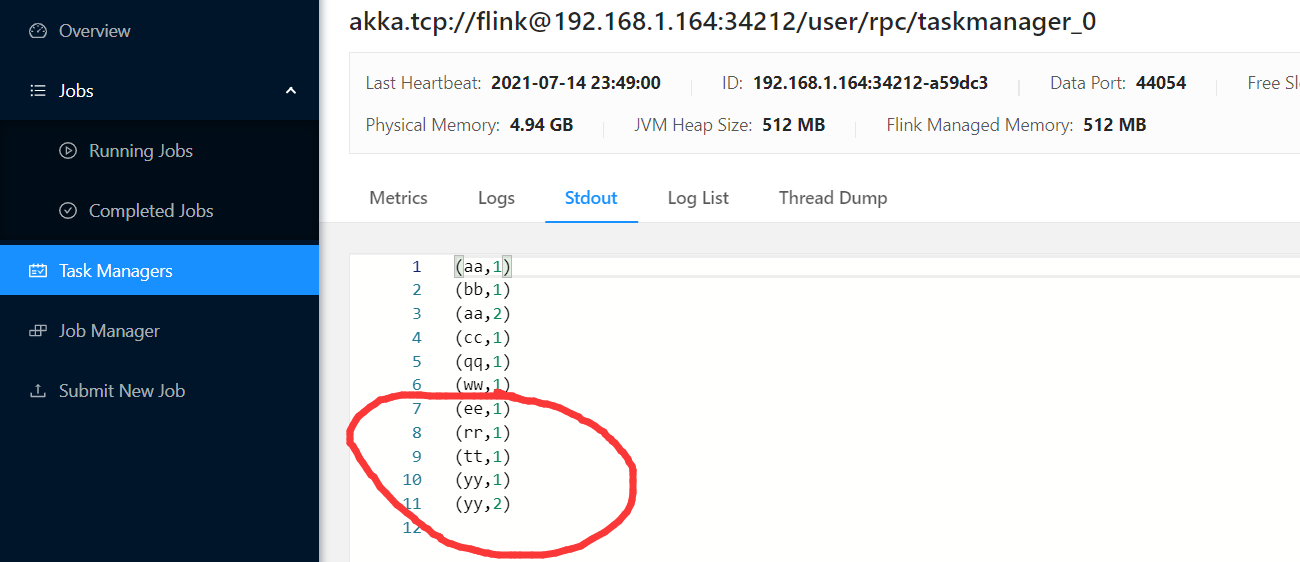
4)也支持Web UI界面提交Flink应用
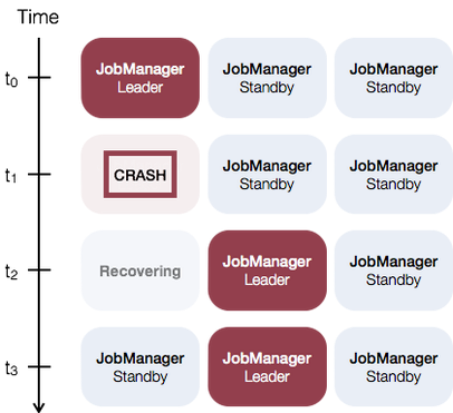
3.3.3 Standalone高可用(HA)
任何时候都有一个 主 JobManager 和多个备用 JobManagers,以便在主节点失败时有备用 JobManagers 来接管集群。这保证了没有单点故障,一旦备 JobManager 接管集群,作业就可以正常运行。主备 JobManager 实例之间没有明显的区别。每个 JobManager 都可以充当主备节点。
1)修改配置文件: flink-conf.yaml
vim /opt/module/flink-standalone/conf/flink-conf.yaml
high-availability: zookeeper high-availability.storageDir: hdfs://hadoop162:8020/flink/standalone/ha high-availability.zookeeper.quorum: hadoop162:2181,hadoop163:2181,hadoop164:2181 high-availability.zookeeper.path.root: /flink-standalone high-availability.cluster-id: /cluster_yuange
2)修改配置文件: masters
vim /opt/module/flink-standalone/conf/masters
hadoop163:8081 hadoop164:8081
3)分发修改的后配置文件到其他节点
xsync /opt/module/flink-standalone/conf/
4)在/etc/profile.d/my.sh中配置环境变量
sudo vim /etc/profile.d/my.sh
export HADOOP_CLASSPATH=`hadoop classpath`
#分发
sudo /home/atguigu/bin/xsync /etc/profile.d/my.sh
#刷新环境变量,每台节点都执行
source /etc/profile.d/my.sh
5)首先启动dfs集群和zookeeper集群
hadoop.sh start
zk start
6)启动standalone HA集群
/opt/module/flink-standalone/bin/start-cluster.sh
7)可以分别访问:http://hadoop163:8081、http://hadoop164:8081

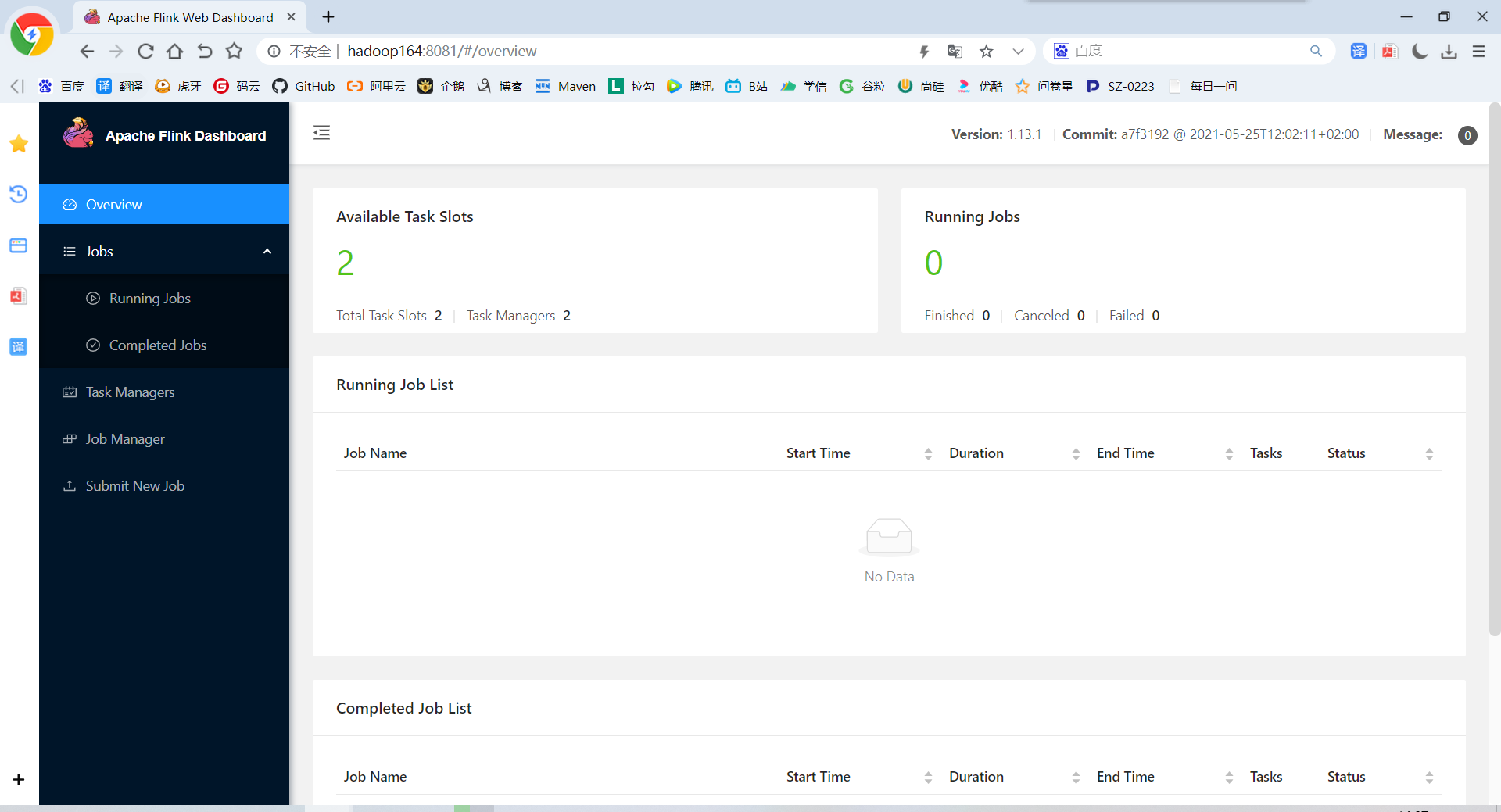
8)在zkCli.sh中查看谁是leader
zkCli.sh -server hadoop162:2181,hadoop163:2181,hadoop164:2181
get /flink-standalone/cluster_yuange/leader/rest_server_loc

9)杀死hadoop163上的Jobmanager, 再看leader

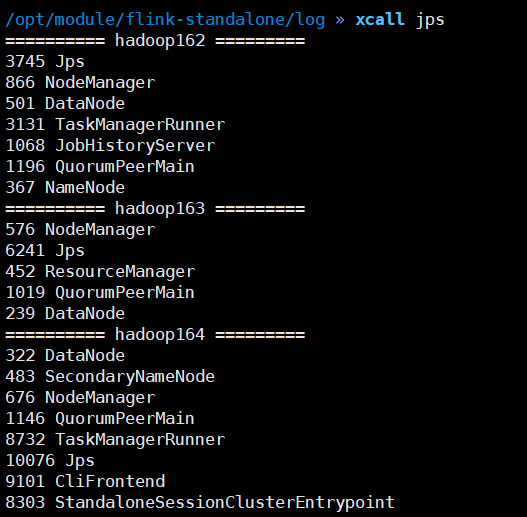

注意: 不管是不是leader从WEB UI上看不到区别, 并且都可以与之提交应用.
3.4 Yarn模式
独立部署(Standalone)模式由Flink自身提供计算资源,无需其他框架提供资源,这种方式降低了和其他第三方资源框架的耦合性,独立性非常强。但是你也要记住,Flink主要是计算框架,而不是资源调度框架,所以本身提供的资源调度并不是它的强项,所以还是和其他专业的资源调度框架集成更靠谱,所以接下来我们来学习在强大的Yarn环境中Flink是如何使用的。(其实是因为在国内工作中,Yarn使用的非常多)
把Flink应用提交给Yarn的ResourceManager, Yarn的ResourceManager会申请容器从Yarn的NodeManager上面. Flink会创建JobManager和TaskManager在这些容器上.Flink会根据运行在JobManger上的job的需要的slot的数量动态的分配TaskManager资源
3.4.1 Yarn模式配置
1)复制flink-yarn
cp -r /opt/module/flink-1.13.1 /opt/module/flink-yarn
2)将案例Jar包拷贝至/opt/module/flink-yarn
cp /opt/module/flink-standalone/FlinkTest-1.0-SNAPSHOT.jar /opt/module/flink-yarn
3)配置环境变量HADOOP_CLASSPATH,在/etc/profile.d/my.sh中配置(如果前面已经配置可以忽略)
sudo vim /etc/profile.d/my.sh
export HADOOP_CLASSPATH=`hadoop classpath`
#分发
sudo /home/atguigu/bin/xsync /etc/profile.d/my.sh
#刷新环境变量,每台节点都执行
source /etc/profile.d/my.sh
3.4.2 Yarn运行无界流WordCount
1)启动hadoop集群(hdfs, yarn)
hadoop.sh start
2)监控hadoop164的8888端口并输入一些单词
3)运行无界流
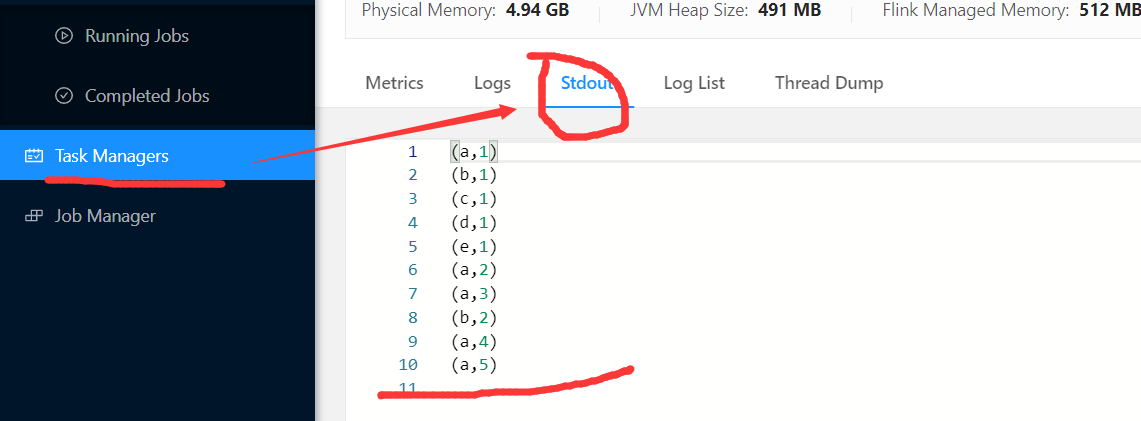
/opt/module/flink-yarn/bin/flink run -t yarn-per-job -c com.yuange.flink.day01.Flink_WC_UnBounded_Lambda /opt/module/flink-yarn/FlinkTest-1.0-SNAPSHOT.jar
4)在yarn的ResourceManager界面查看执行情况:http://hadoop163:8088


3.4.3 Flink on Yarn的3种部署模式
Flink提供了yarn上运行的3模式,分别为Application Mode, Session-Cluster和Per-Job-Cluster模式
1)Session-Cluster
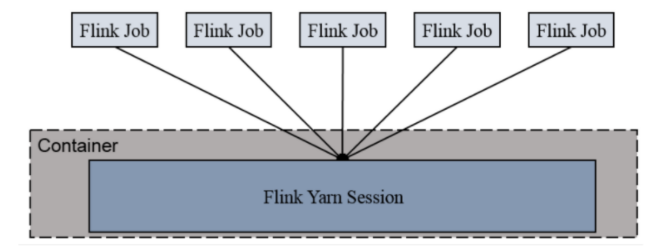
Session-Cluster模式需要先启动Flink集群,向Yarn申请资源。以后提交任务都向这里提交。这个Flink集群会常驻在yarn集群中,除非手工停止。在向Flink集群提交Job的时候,如果资源被用完了,则新的Job不能正常提交。如果提交的作业中有长时间执行的大作业, 占用了该Flink集群的所有资源, 则后续无法提交新的job。所以, Session-Cluster适合那些需要频繁提交的多个小Job,并且执行时间都不长的Job。
2)Per-Job-Cluster
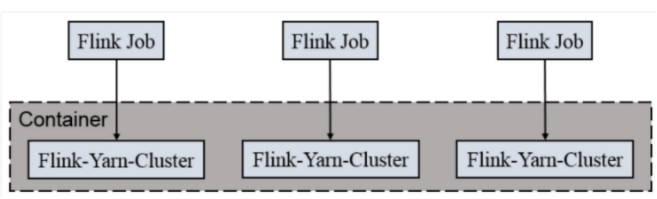
一个Job会对应一个Flink集群,每提交一个作业会根据自身的情况,都会单独向yarn申请资源,直到作业执行完成,一个作业的失败与否并不会影响下一个作业的正常提交和运行。独享Dispatcher和ResourceManager,按需接受资源申请;适合规模大长时间运行的作业。
每次提交都会创建一个新的flink集群,任务之间互相独立,互不影响,方便管理。任务执行完成之后创建的集群也会消失。
3)Application Mode
Application Mode会在Yarn上启动集群, 应用jar包的main函数(用户类的main函数)将会在JobManager上执行. 只要应用程序执行结束, Flink集群会马上被关闭. 也可以手动停止集群.
与Per-Job-Cluster的区别: 就是Application Mode下, 用户的main函数是在集群中(job manager)执行的
官方建议:出于生产的需求, 我们建议使用Per-job or Application Mode,因为他们给应用提供了更好的隔离!
3.4.4 Per-Job-Cluster模式执行无界流WordCount
/opt/module/flink-yarn/bin/flink run -t yarn-per-job -c com.yuange.flink.day01.Flink_WC_UnBounded_Lambda /opt/module/flink-yarn/FlinkTest-1.0-SNAPSHOT.jar
3.4.5 Session-Cluster模式执行无界流WordCount
1)启动一个Flink-Session
/opt/module/flink-yarn/bin/yarn-session.sh -d
2)在Session上运行Job
/opt/module/flink-yarn/bin/flink run -c com.yuange.flink.day01.Flink_WC_UnBounded_Lambda /opt/module/flink-yarn/FlinkTest-1.0-SNAPSHOT.jar
注意:程序会自动找到你的yarn-session启动的Flink集群,也可以手动指定你的yarn-session集群,application_XXXX_YY指的是在yarn上启动的yarn应用

/opt/module/flink-yarn/bin/flink run -t yarn-session -Dyarn.application.id=application_XXXX_YY -c com.yuange.flink.day01.Flink_WC_UnBounded_Lambda /opt/module/flink-yarn/FlinkTest-1.0-SNAPSHOT.jar
3)监控hadoop104的8888端口
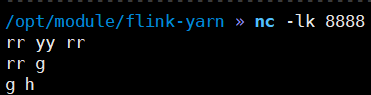
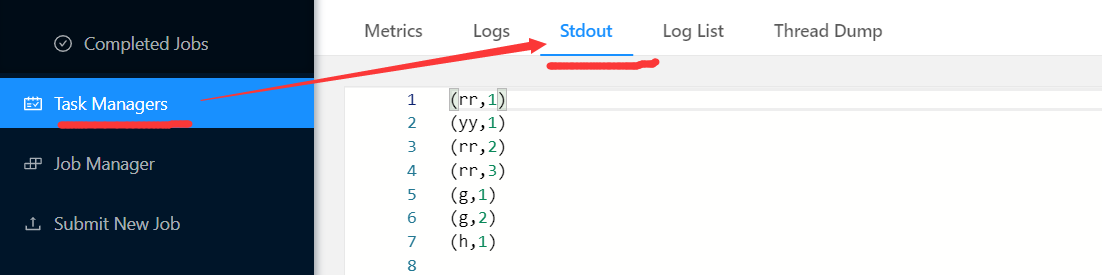
4)查看结果:http://hadoop163:8088

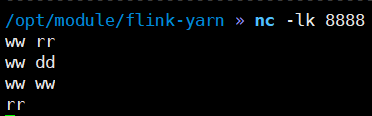
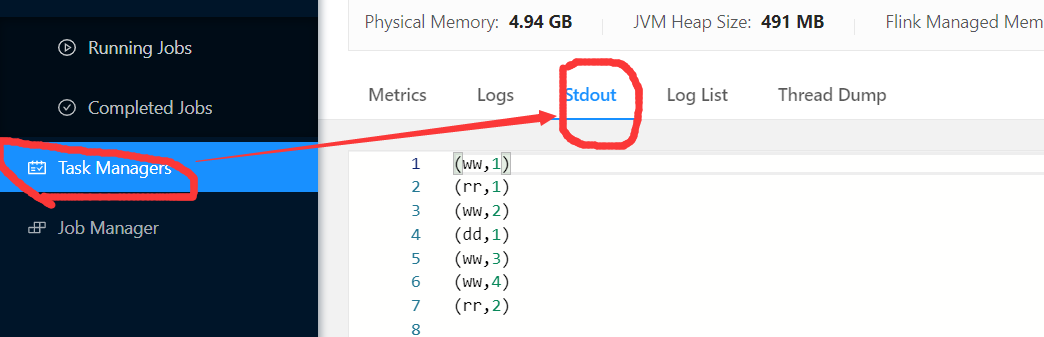
3.4.6 Application Mode模式执行无界流WordCount
/opt/module/flink-yarn/bin/flink run-application -t yarn-application -c com.yuange.flink.day01.Flink_WC_UnBounded_Lambda /opt/module/flink-yarn/FlinkTest-1.0-SNAPSHOT.jar

3.4.7 Yarn模式高可用
Yarn模式的高可用和Standalone模式的高可用原理不一样,Standalone模式中, 同时启动多个Jobmanager, 一个为leader其他为standby, 当leader挂了, 其他的才会有一个成为leader。yarn的高可用是同时只启动一个Jobmanager, 当这个Jobmanager挂了之后, yarn会再次启动一个, 其实是利用的yarn的重试次数来实现的高可用
1)在yarn-site.xml中配置
vim /opt/module/hadoop-3.1.3/etc/hadoop/yarn-site.xml
<property> <name>yarn.resourcemanager.am.max-attempts</name> <value>4</value> <description> The maximum number of application master execution attempts. </description> </property>
2)分发
xsync /opt/module/hadoop-3.1.3/etc/hadoop/yarn-site.xml
3)重启Yarn
hadoop.sh stop
hadoop.sh start
4)启动Zookeeper
zk start
5)在flink-conf.yaml中配置以下内容
vim /opt/module/flink-yarn/conf/flink-conf.yaml
yarn.application-attempts: 3 high-availability: zookeeper high-availability.storageDir: hdfs://hadoop162:8020/flink/yarn/ha high-availability.zookeeper.quorum: hadoop162:2181,hadoop163:2181,hadoop164:2181 high-availability.zookeeper.path.root: /flink-yarn
6)启动yarn-session
/opt/module/flink-yarn/bin/yarn-session.sh -d
7)杀死Jobmanager, 查看他的复活情况

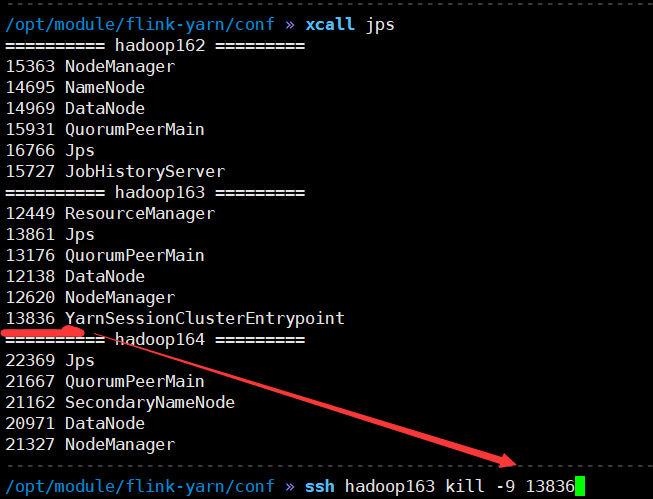
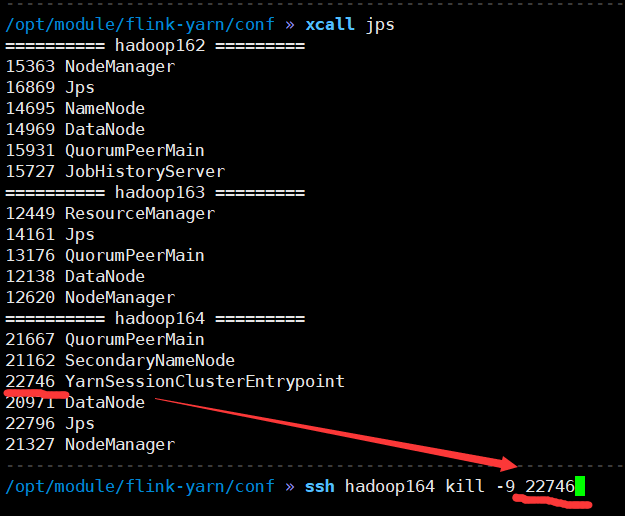

注意: yarn-site.xml中是它活的次数的上限, flink-conf.xml中的次数应该小于这个值
3.6 K8S & Mesos模式
Mesos是Apache下的开源分布式资源管理框架,它被称为是分布式系统的内核,在Twitter得到广泛使用,管理着Twitter超过30,0000台服务器上的应用部署,但是在国内,依然使用着传统的Hadoop大数据框架,所以国内使用mesos框架的并不多,这里我们就不做过多讲解了。
容器化部署时目前业界很流行的一项技术,基于Docker镜像运行能够让用户更加方便地对应用进行管理和运维。容器管理工具中最为流行的就是Kubernetes(k8s),而Flink也在最近的版本中支持了k8s部署模式。这里我们也不做过多的讲解