第1章 实时处理模块
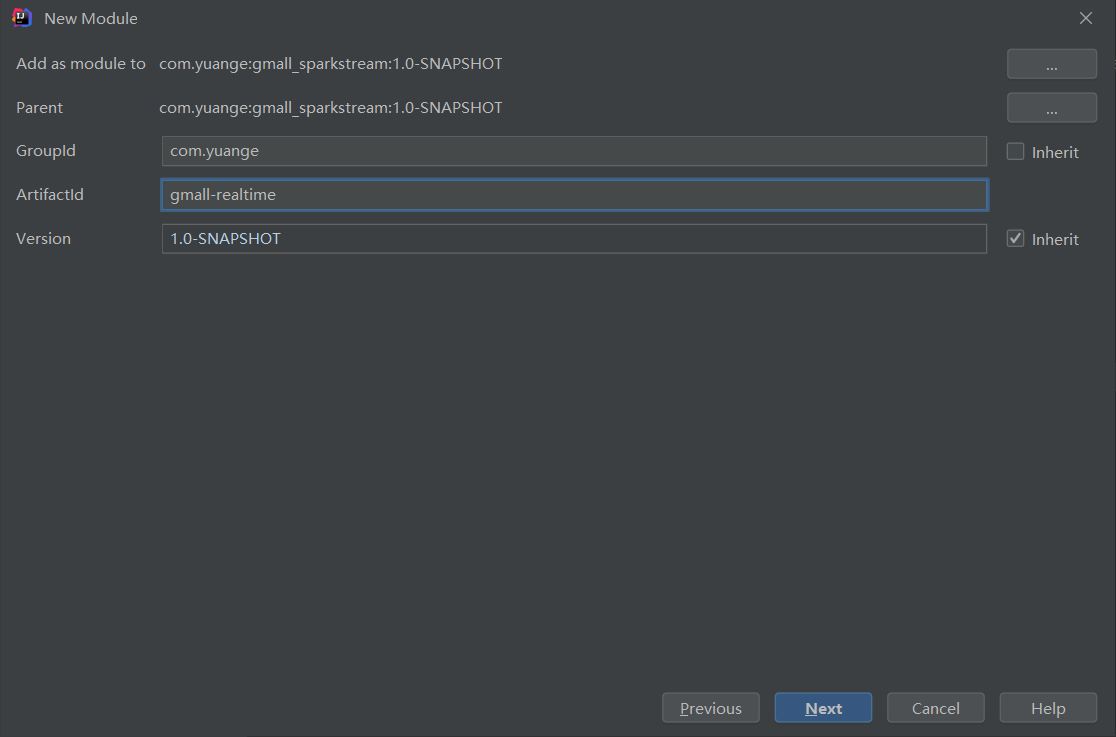
1.1 创建模块gmall_realtime


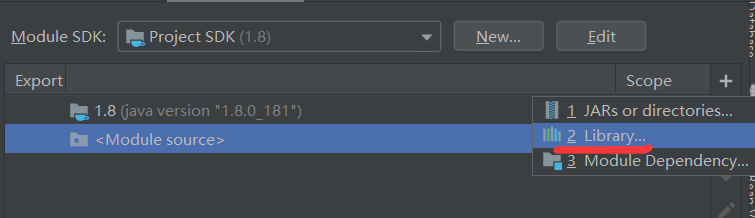
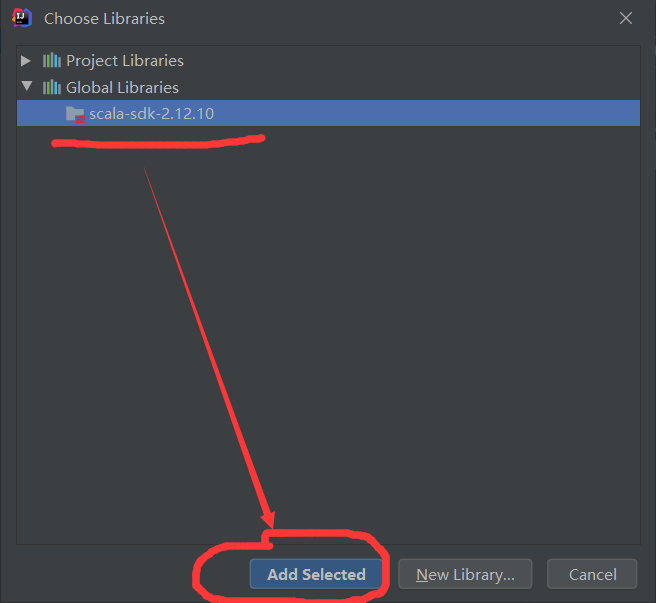
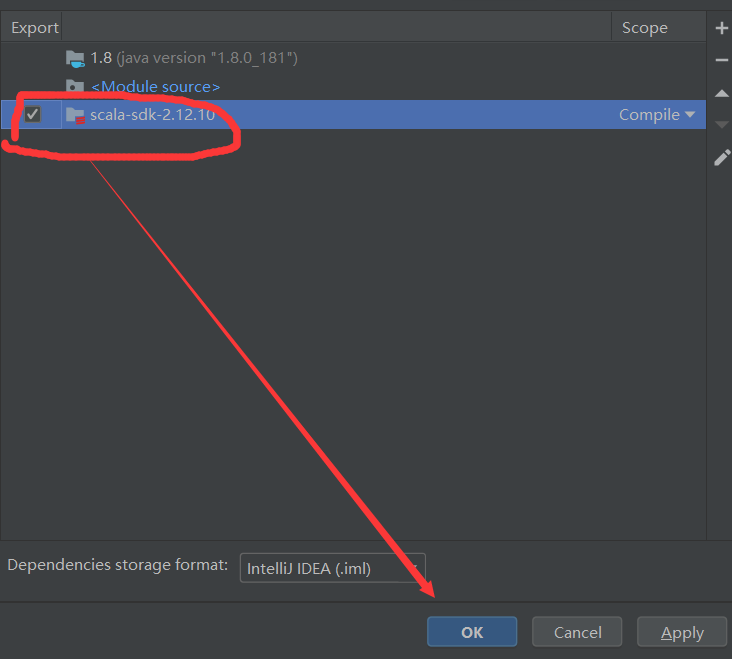
1.2 代码思路
1)消费Kafka中的数据;
2)利用Redis过滤当日已经计入的日活设备;
3)把每批次新增的当日日活信息保存到HBase中;
4)从HBase中查询出数据,发布成数据接口,通可视化工程调用。
1.3 代码开发1 ---消费Kafka
1.3.1 配置
1)config.properties
# Kafka配置
kafka.broker.list=hadoop102:9092,hadoop103:9092,hadoop104:9092
# Redis配置
redis.host=hadoop102
redis.port=6379
2)log4j.properties
# Set everything to be logged to the console
log4j.rootCategory=ERROR, console
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.err
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c{1}: %m%n
3)pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>gmall_sparkstream</artifactId>
<groupId>com.yuange</groupId>
<version>1.0-SNAPSHOT</version>
</parent>
<modelVersion>4.0.0</modelVersion>
<groupId>com.yuange</groupId>
<artifactId>gmall_realtime</artifactId>
<dependencies>
<dependency>
<groupId>com.yuange</groupId>
<artifactId>gmall_common</artifactId>
<version>1.0-SNAPSHOT</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.12</artifactId>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.4.1</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_2.12</artifactId>
</dependency>
<!-- 使用java连接redis -->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.9.0</version>
</dependency>
<!-- 使用Java操作ES的客户端api -->
<!--<dependency>
<groupId>io.searchbox</groupId>
<artifactId>jest</artifactId>
<version>5.3.3</version>
</dependency>
<dependency>
<groupId>net.java.dev.jna</groupId>
<artifactId>jna</artifactId>
<version>4.5.2</version>
</dependency>
<dependency>
<groupId>org.codehaus.janino</groupId>
<artifactId>commons-compiler</artifactId>
<version>2.7.8</version>
</dependency>-->
</dependencies>
<build>
<plugins>
<!-- 该插件用于将Scala代码编译成class文件 -->
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.2</version>
<executions>
<execution>
<!-- 声明绑定到maven的compile阶段 -->
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
1.3.2 工具类
1)PropertiesUtil
package com.yuange.realtime.utils
import java.io.InputStreamReader
import java.util.Properties
/**
* @作者:袁哥
* @时间:2021/7/5 19:54
*/
object PropertiesUtil {
def load(propertieName:String): Properties ={
val prop=new Properties()
prop.load(new InputStreamReader(Thread.currentThread().getContextClassLoader.getResourceAsStream(propertieName) , "UTF-8"))
prop
}
}
2)MykafkaUtil
package com.yuange.realtime.utils
import java.util.Properties
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.streaming.StreamingContext
import org.apache.spark.streaming.dstream.InputDStream
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
/**
* @作者:袁哥
* @时间:2021/7/6 17:30
*/
object MyKafkaUtil {
//1.创建配置信息对象
private val properties: Properties = PropertiesUtil.load("config.properties")
//2.用于初始化链接到集群的地址
val broker_list: String = properties.getProperty("kafka.broker.list")
//3.kafka消费者配置
val kafkaParam = Map(
"bootstrap.servers" -> broker_list,
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
//消费者组
"group.id" -> "yuange",
//如果没有初始化偏移量或者当前的偏移量不存在任何服务器上,可以使用这个配置属性
//可以使用这个配置,latest自动重置偏移量为最新的偏移量
"auto.offset.reset" -> "earliest",
//如果是true,则这个消费者的偏移量会在后台自动提交,但是kafka宕机容易丢失数据
//如果是false,会需要手动维护kafka偏移量
"enable.auto.commit" -> "true"
)
// 创建DStream,返回接收到的输入数据
// LocationStrategies:根据给定的主题和集群地址创建consumer
// LocationStrategies.PreferConsistent:持续的在所有Executor之间分配分区
// ConsumerStrategies:选择如何在Driver和Executor上创建和配置Kafka Consumer
// ConsumerStrategies.Subscribe:订阅一系列主题
def getKafkaStream(topic: String, ssc: StreamingContext): InputDStream[ConsumerRecord[String, String]] = {
val dStream: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream[String, String](
ssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String, String](Array(topic), kafkaParam))
dStream
}
}
3)RedisUtil
package com.yuange.realtime.utils
import java.util.Properties
import redis.clients.jedis.{Jedis, JedisPool, JedisPoolConfig}
/**
* @作者:袁哥
* @时间:2021/7/6 17:32
* 使用的是Jedis提供的连接池,会出现问题:
* 比如一个线程使用redis,发送一个命令,之后将连接放回池中,
* 第二个线程,从池中借走了这个连接,连接的socket的buffer不会清空,会由上一个线程发送的残留数据
*/
object RedisUtil {
val config: Properties = PropertiesUtil.load("config.properties")
val host: String = config.getProperty("redis.host")
val port: String = config.getProperty("redis.port")
//不使用连接池
def getJedisClient():Jedis={
new Jedis(host,port.toInt)
}
}
1.3.3 样例类
StartUpLog
package com.yuange.realtime.beans
/**
* @作者:袁哥
* @时间:2021/7/6 17:35
*/
case class StartUpLog(mid:String,
uid:String,
appid:String,
area:String,
os:String,
ch:String,
`type`:String,
vs:String,
var logDate:String,
var logHour:String,
var ts:Long)
1.3.4 业务类
公共部分:BaseApp
package com.yuange.realtime.app
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* @作者:袁哥
* @时间:2021/7/6 17:45
* 四个需求,都需要使用SparkStreaming从Kafka消费数据,因此四个需求的开发流程是一样的
* ①创建一个 StreamingContext
* ②从kafka获取DS
* ③对DS进行转换:四个需求需要对DS进行不同的转换 ---->业务----->将抽取为一段功能,将功能在不同的需求中作为参数进行传入(控制抽象)
* ④启动App
* ⑤阻塞当前线程
*/
abstract class BaseApp {
//声明appName
var appName:String
//声明 Duration(一批数据的采集周期)
var duration:Int
//不是一个抽象属性
var streamingContext:StreamingContext=null
//运行程序
def run(op: => Unit) {
try {
streamingContext = new StreamingContext("local[*]", appName, Seconds(duration))
//程序自定义的处理逻辑逻辑
op
//启动app
streamingContext.start()
//阻塞当前线程
streamingContext.awaitTermination()
} catch {
case ex: Exception =>
ex.printStackTrace()
streamingContext.stop(true)
}
}
}
消费Kafka中的数据:DAUApp
package com.yuange.realtime.app
import java.time.{Instant, LocalDateTime, ZoneId}
import java.time.format.DateTimeFormatter
import com.alibaba.fastjson.JSON
import com.yuange.constants.Constants
import com.yuange.realtime.beans.StartUpLog
import com.yuange.realtime.utils.MyKafkaUtil
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.spark.streaming.dstream.{DStream, InputDStream}
/**
* @作者:袁哥
* @时间:2021/7/6 17:52
*/
object DAUApp extends BaseApp {
override var appName: String = "DAUApp"
override var duration: Int = 10
def main(args: Array[String]): Unit = {
run{
val ds: InputDStream[ConsumerRecord[String, String]] = MyKafkaUtil.getKafkaStream(Constants.GMALL_STARTUP_LOG, streamingContext)
// ①从kafka中消费数据,将ConsumerRecord的value中的数据封装为 需要的Bean
val ds1: DStream[StartUpLog] = ds.map(record => {
//调用JSON工具,将JSON str转为 JavaBean
val startUpLog: StartUpLog = JSON.parseObject(record.value(),classOf[StartUpLog])
//封装 logDate,logHour
val formatter: DateTimeFormatter = DateTimeFormatter.ofPattern("yyyy-MM-dd")
val localDateTime: LocalDateTime = LocalDateTime.ofInstant(Instant.ofEpochMilli(startUpLog.ts),ZoneId.of("Asia/Shanghai"))
startUpLog.logDate = localDateTime.format(formatter)
startUpLog.logHour = localDateTime.getHour.toString
startUpLog
})
ds1.count().print()
}
}
}
1.3.5 测试
1)启动日志服务器
startgmall.sh start
2)启动JsonMocker中的mian方法,生产数据(在此之前你必须启动ZK、Kafka、Nginx)
#启动nginx
sudo /opt/module/nginx/sbin/nginx

3)启动DAUApp,消费数据
4)查看结果
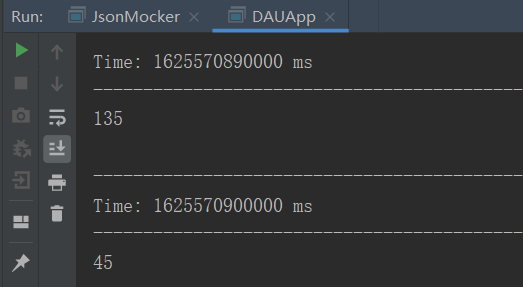
1.4 代码开发2 ---去重(启动程序之前必须启动Redis)
1.4.1 流程图
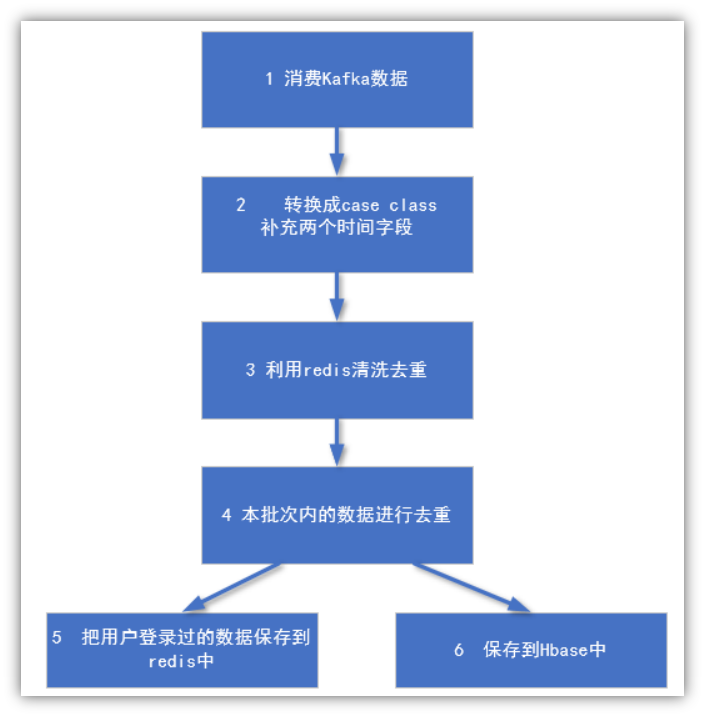
1.4.2 设计Redis的KV
|
key |
value |
|
dau:2020-03-22 |
设备id |
1.4.3 业务代码(修改DAUApp)
package com.yuange.realtime.app
import java.lang
import java.time.{Instant, LocalDateTime, ZoneId}
import java.time.format.DateTimeFormatter
import com.alibaba.fastjson.JSON
import com.yuange.constants.Constants
import com.yuange.realtime.beans.StartUpLog
import com.yuange.realtime.utils.{MyKafkaUtil, RedisUtil}
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.spark.streaming.dstream.{DStream, InputDStream}
import redis.clients.jedis.Jedis
/**
* @作者:袁哥
* @时间:2021/7/6 17:52
*/
object DAUApp extends BaseApp {
override var appName: String = "DAUApp"
override var duration: Int = 10
def main(args: Array[String]): Unit = {
run{
val ds: InputDStream[ConsumerRecord[String, String]] = MyKafkaUtil.getKafkaStream(Constants.GMALL_STARTUP_LOG, streamingContext)
// 从kafka中消费数据,将ConsumerRecord的value中的数据封装为 需要的Bean
val ds1: DStream[StartUpLog] = ds.map(record => {
//调用JSON工具,将JSON str转为 JavaBean
val startUpLog: StartUpLog = JSON.parseObject(record.value(),classOf[StartUpLog])
//封装 logDate,logHour
val formatter: DateTimeFormatter = DateTimeFormatter.ofPattern("yyyy-MM-dd")
val localDateTime: LocalDateTime = LocalDateTime.ofInstant(Instant.ofEpochMilli(startUpLog.ts),ZoneId.of("Asia/Shanghai"))
startUpLog.logDate = localDateTime.format(formatter)
startUpLog.logHour = localDateTime.getHour.toString
startUpLog
})
ds1.count().print()
//在本批次内进行去重,取时间戳最早的那条启动日志的明细信息
val ds3: DStream[StartUpLog] = removeDuplicateInBatch(ds1)
ds3.count().print()
//连接redis查询,看哪些 mid今日已经记录过了,对记录过的进行过滤
val ds4: DStream[StartUpLog] = removeDuplicateMidsFromRedis2(ds3)
ds4.cache()
ds4.count().print()
//将需要写入Hbase的 mid的信息,写入redis
ds4.foreachRDD(rdd => {
//以分区为单位写出
rdd.foreachPartition(partition =>{
//连接redis
val jedis: Jedis = RedisUtil.getJedisClient()
//写入到redis的 set集合中
partition.foreach(log => jedis.sadd("DAU:" + log.logDate , log.mid))
//关闭
jedis.close()
})
})
}
}
/**
* 在本批次内进行去重,取时间戳最早的那条启动日志的明细信息
* 逻辑: 先按照mid 和日期 分组,按照ts进行排序,之后最小的
* */
def removeDuplicateInBatch(ds1: DStream[StartUpLog]): DStream[StartUpLog] = {
//按照mid 和日期 分组 groupByKey
val ds2: DStream[((String, String), StartUpLog)] = ds1.map(log => ((log.mid,log.logDate),log))
val ds3: DStream[((String,String),Iterable[StartUpLog])] = ds2.groupByKey()
val result: DStream[StartUpLog] = ds3.flatMap{
case ((min,logDate),logs) => {
val firstStartLog: List[StartUpLog] = logs.toList.sortBy(_.ts).take(1)
firstStartLog
}
}
result
}
/**
* 查询Redis中,当天已经有哪些mid,已经写入到hbase,已经写入的过滤掉
* 在Spark中进行数据库读写,都一般是以分区为单位获取连接!
* DS中有1000条数据,2个分区,创建2个连接,发送1000次sismember请求,关闭2个连接。
* */
def removeDuplicateMidsFromRedis2(ds3: DStream[StartUpLog]): DStream[StartUpLog] = {
ds3.mapPartitions(partition => {
//连接redis
val jedis: Jedis = RedisUtil.getJedisClient()
//对分区数据的处理,在处理时,一个分区都共用一个连接
val filterdLogs: Iterator[StartUpLog] = partition.filter(log => {
//判断一个元素是否在set集合中
val ifExists: lang.Boolean = jedis.sismember("DAU:" + log.logDate, log.mid)
//filter算子,只留下为true的部分
!ifExists
})
//关闭
jedis.close()
filterdLogs
})
}
}
1.5 代码实现3 ---保存到HBase中(在此之前必须启动Hadoop和Hbase)
1.5.1 Phoenix ---HBase的SQL化插件
详情请看博客:https://www.cnblogs.com/LzMingYueShanPao/p/14771227.html
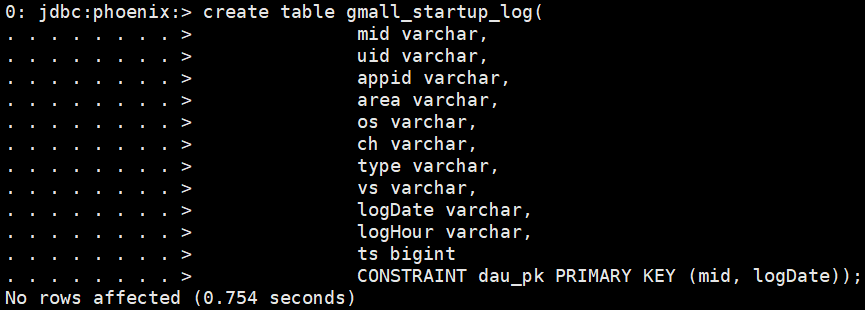
1.5.2 利用Phoenix建立数据表
1)连接Phoenix
sqlline.py
2)创建表
create table gmall_startup_log(
mid varchar,
uid varchar,
appid varchar,
area varchar,
os varchar,
ch varchar,
type varchar,
vs varchar,
logDate varchar,
logHour varchar,
ts bigint
CONSTRAINT dau_pk PRIMARY KEY (mid, logDate));
1.5.3 pom.xml 中增加依赖
<dependency>
<groupId>org.apache.phoenix</groupId>
<artifactId>phoenix-spark</artifactId>
<version>5.0.0-HBase-2.0</version>
<exclusions>
<exclusion>
<groupId>org.glassfish</groupId>
<artifactId>javax.el</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
</dependency>
1.5.4 业务保存代码(修改DAUApp)
package com.yuange.realtime.app
import java.lang
import java.time.{Instant, LocalDateTime, ZoneId}
import java.time.format.DateTimeFormatter
import com.alibaba.fastjson.JSON
import com.yuange.constants.Constants
import com.yuange.realtime.beans.StartUpLog
import com.yuange.realtime.utils.{MyKafkaUtil, RedisUtil}
import org.apache.hadoop.hbase.HBaseConfiguration
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.spark.streaming.dstream.{DStream, InputDStream}
import redis.clients.jedis.Jedis
import org.apache.phoenix.spark._
/**
* @作者:袁哥
* @时间:2021/7/6 17:52
*/
object DAUApp extends BaseApp {
override var appName: String = "DAUApp"
override var duration: Int = 10
def main(args: Array[String]): Unit = {
run{
val ds: InputDStream[ConsumerRecord[String, String]] = MyKafkaUtil.getKafkaStream(Constants.GMALL_STARTUP_LOG, streamingContext)
// 从kafka中消费数据,将ConsumerRecord的value中的数据封装为 需要的Bean
val ds1: DStream[StartUpLog] = ds.map(record => {
//调用JSON工具,将JSON str转为 JavaBean
val startUpLog: StartUpLog = JSON.parseObject(record.value(),classOf[StartUpLog])
//封装 logDate,logHour
val formatter: DateTimeFormatter = DateTimeFormatter.ofPattern("yyyy-MM-dd")
val localDateTime: LocalDateTime = LocalDateTime.ofInstant(Instant.ofEpochMilli(startUpLog.ts),ZoneId.of("Asia/Shanghai"))
startUpLog.logDate = localDateTime.format(formatter)
startUpLog.logHour = localDateTime.getHour.toString
startUpLog
})
ds1.count().print()
//在本批次内进行去重,取时间戳最早的那条启动日志的明细信息
val ds3: DStream[StartUpLog] = removeDuplicateInBatch(ds1)
ds3.count().print()
//连接redis查询,看哪些 mid今日已经记录过了,对记录过的进行过滤
val ds4: DStream[StartUpLog] = removeDuplicateMidsFromRedis2(ds3)
ds4.cache()
ds4.count().print()
//将需要写入Hbase的 mid的信息,写入redis
ds4.foreachRDD(rdd => {
//以分区为单位写出
rdd.foreachPartition(partition =>{
//连接redis
val jedis: Jedis = RedisUtil.getJedisClient()
//写入到redis的 set集合中
partition.foreach(log => jedis.sadd("DAU:" + log.logDate , log.mid))
//关闭
jedis.close()
})
})
/**
* 将明细信息写入hbase
* def saveToPhoenix(
* tableName: String, //表名
* cols: Seq[String] //RDD中的数据要写到表的哪些列,
* conf: Configuration = new Configuration //hadoop包下的Configuration,不能new ,必须使用HBase提供的API创建
* //HBaseConfiguration.create(),会 new Configuration(),再添加Hbase配置文件的信息
* zkUrl: Option[String] = None //和命令行的客户端的zkUrl一致
* tenantId: Option[String] = None
* )
* */
ds4.foreachRDD(foreachFunc = rdd => {
// RDD 隐式转换为 ProductRDDFunctions,再调用saveToPhoenix
rdd saveToPhoenix(
"GMALL_STARTUP_LOG",
Seq("MID", "UID", "APPID", "AREA", "OS", "CH", "TYPE", "VS", "LOGDATE", "LOGHOUR", "TS"),
HBaseConfiguration.create(),
Some("hadoop103:2181")
)
})
}
}
/**
* 在本批次内进行去重,取时间戳最早的那条启动日志的明细信息
* 逻辑: 先按照mid 和日期 分组,按照ts进行排序,之后最小的
* */
def removeDuplicateInBatch(ds1: DStream[StartUpLog]): DStream[StartUpLog] = {
//按照mid 和日期 分组 groupByKey
val ds2: DStream[((String, String), StartUpLog)] = ds1.map(log => ((log.mid,log.logDate),log))
val ds3: DStream[((String,String),Iterable[StartUpLog])] = ds2.groupByKey()
val result: DStream[StartUpLog] = ds3.flatMap{
case ((min,logDate),logs) => {
val firstStartLog: List[StartUpLog] = logs.toList.sortBy(_.ts).take(1)
firstStartLog
}
}
result
}
/**
* 查询Redis中,当天已经有哪些mid,已经写入到hbase,已经写入的过滤掉
* 在Spark中进行数据库读写,都一般是以分区为单位获取连接!
* DS中有1000条数据,2个分区,创建2个连接,发送1000次sismember请求,关闭2个连接。
* */
def removeDuplicateMidsFromRedis2(ds3: DStream[StartUpLog]): DStream[StartUpLog] = {
ds3.mapPartitions(partition => {
//连接redis
val jedis: Jedis = RedisUtil.getJedisClient()
//对分区数据的处理,在处理时,一个分区都共用一个连接
val filterdLogs: Iterator[StartUpLog] = partition.filter(log => {
//判断一个元素是否在set集合中
val ifExists: lang.Boolean = jedis.sismember("DAU:" + log.logDate, log.mid)
//filter算子,只留下为true的部分
!ifExists
})
//关闭
jedis.close()
filterdLogs
})
}
}
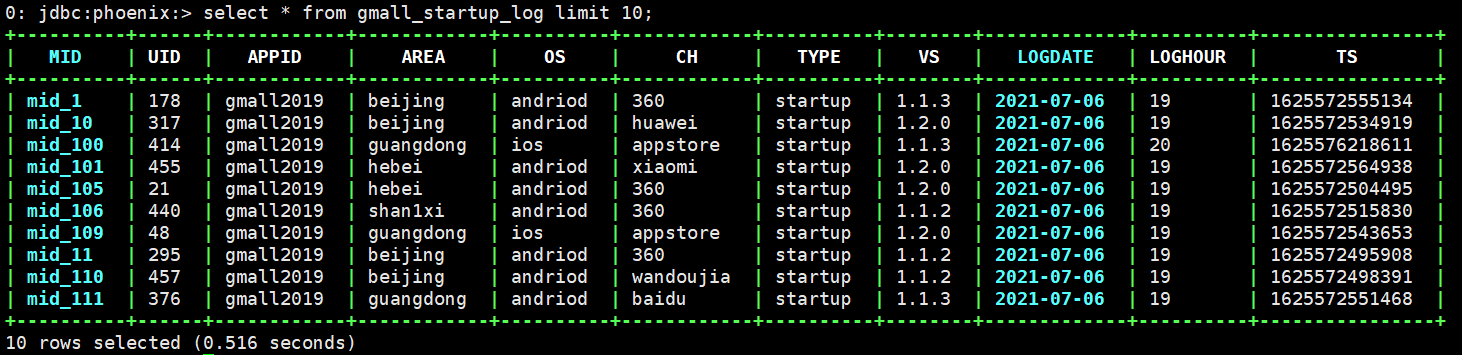
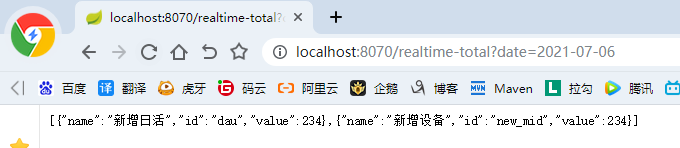
第2章 日活数据查询接口

2.1 访问路径
|
总数 |
http://localhost:8070/realtime-total?date=2020-08-15 |
|
分时统计 |
http://localhost:8070/realtime-hours?id=dau&date=2020-08-15 |
2.2 要求数据格式
|
总数 |
[{"id":"dau","name":"新增日活","value":1200}, {"id":"new_mid","name":"新增设备","value":233}] |
|
分时统计 |
{"yesterday":{"11":383,"12":123,"17":88,"19":200 }, "today":{"12":38,"13":1233,"17":123,"19":688 }} |
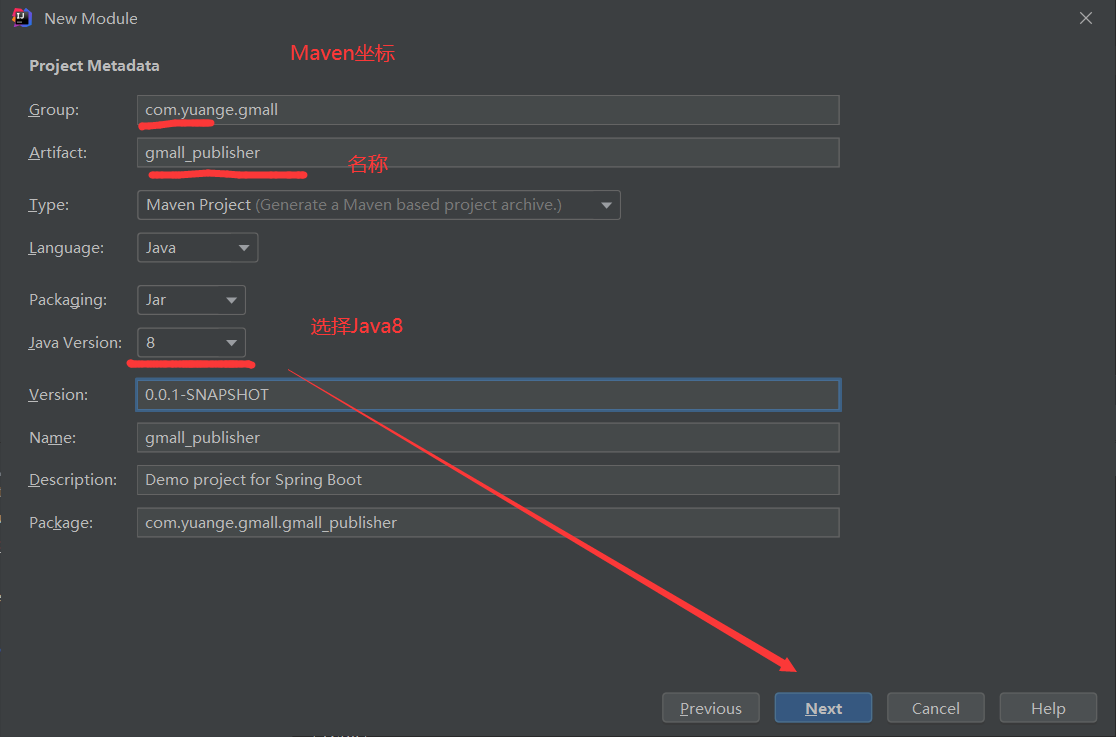
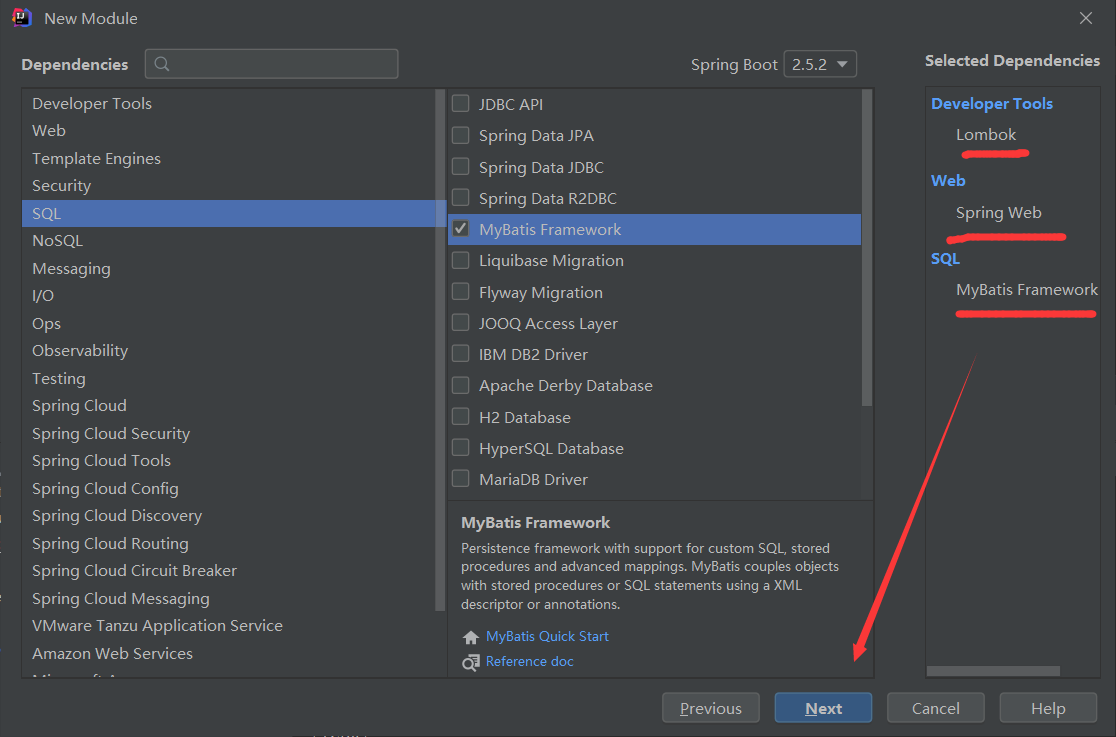
2.3 搭建发布工程

2.4 配置文件
2.4.1 pom.xml
1)添加如下依赖
<dependency>
<groupId>com.yuange</groupId>
<artifactId>gmall_common</artifactId>
<version>1.0-SNAPSHOT</version>
</dependency>
<dependency>
<groupId>org.apache.phoenix</groupId>
<artifactId>phoenix-core</artifactId>
<version>5.0.0-HBase-2.0</version>
<exclusions>
<exclusion>
<groupId>org.glassfish</groupId>
<artifactId>javax.el</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>20.0</version>
</dependency>
2)给它换爸爸,完整的Pom文件如下
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<artifactId>gmall_sparkstream</artifactId>
<groupId>com.yuange</groupId>
<version>1.0-SNAPSHOT</version>
</parent>
<artifactId>gmall_publisher</artifactId>
<properties>
<java.version>1.8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>com.yuange</groupId>
<artifactId>gmall_common</artifactId>
<version>1.0-SNAPSHOT</version>
</dependency>
<dependency>
<groupId>org.apache.phoenix</groupId>
<artifactId>phoenix-core</artifactId>
<version>5.0.0-HBase-2.0</version>
<exclusions>
<exclusion>
<groupId>org.glassfish</groupId>
<artifactId>javax.el</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>20.0</version>
</dependency>
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>2.2.0</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<exclusions>
<exclusion>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-logging</artifactId>
</exclusion>
</exclusions>
</dependency>
<!--nested exception is java.lang.NoSuchMethodError:
org.apache.hadoop.security.authentication.util.KerberosUtil.hasKerberosKeyTab(-->
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-common -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.1.1</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<excludes>
<exclude>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</exclude>
</excludes>
</configuration>
</plugin>
</plugins>
</build>
</project>
3)修改父工程中的Pom文件(给它添加一个儿子)
<module>gmall_publisher</module>
2.4.2 application.properties
#没指定项目名,项目会部署在端口号下的根路径 localhost:8070/
server.port=8070
logging.level.root=error
#mybatis访问数据源的参数
spring.datasource.driver-class-name=org.apache.phoenix.jdbc.PhoenixDriver
spring.datasource.url=jdbc:phoenix:hadoop102,hadoop103,hadoop104:2181
spring.datasource.data-username=
spring.datasource.data-password=
# mybatis sql文件所在的路径
mybatis.mapperLocations=classpath:mappers/*.xml
#开启 A_Column 到 aColumn的映射
mybatis.configuration.map-underscore-to-camel-case=true
2.5 代码实现
|
控制层 |
PublisherController |
实现接口的web发布 |
|
服务层 |
PublisherService |
数据业务查询interface |
|
PublisherServiceImpl |
业务查询的实现类 |
|
|
数据层 |
DauMapper |
数据层查询的interface |
|
DauMapper.xml |
数据层查询的实现配置 |
|
|
主程序 |
GmallPublisherApplication |
增加扫描包 |
2.5.1 GmallPublisherApplication增加扫描包
package com.yuange.gmall.gmall_publisher;
import org.mybatis.spring.annotation.MapperScan;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
@MapperScan("com.yuange.gmall.gmall_publisher.mapper")
public class GmallPublisherApplication {
public static void main(String[] args) {
SpringApplication.run(GmallPublisherApplication.class, args);
}
}
2.5.2 beans层,DAUData.java
package com.yuange.gmall.gmall_publisher.beans;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
/**
* @作者:袁哥
* @时间:2021/7/6 23:16
*/
@AllArgsConstructor
@NoArgsConstructor
@Data
public class DAUData {
private String hour;
private Integer num;
}
2.5.3 mapper层,PublisherMapper接口
package com.yuange.gmall.gmall_publisher.mapper;
import com.yuange.gmall.gmall_publisher.beans.DAUData;
import org.springframework.stereotype.Repository;
import java.util.List;
/**
* @作者:袁哥
* @时间:2021/7/6 23:16
*/
@Repository
public interface PublisherMapper {
//新增(当日)日活","value":1200
Integer getDAUByDate(String date);
//"新增设备(日活)","value":233
Integer getNewMidCountByDate(String date);
//"yesterday":{"11":383,"12":123,"17":88,"19":200 "11":383 封装为Bean
List<DAUData> getDAUDatasByDate(String date);
}
2.5.4 service层
1)PublisherService接口
package com.yuange.gmall.gmall_publisher.service;
import com.yuange.gmall.gmall_publisher.beans.DAUData;
import java.util.List;
/**
* @作者:袁哥
* @时间:2021/7/6 23:14
*/
public interface PublisherService {
//新增(当日)日活","value":1200
Integer getDAUByDate(String date);
//"新增设备(日活)","value":233
Integer getNewMidCountByDate(String date);
//"yesterday":{"11":383,"12":123,"17":88,"19":200 "11":383 封装为Bean
List<DAUData> getDAUDatasByDate(String date);
}
2)PublisherService接口的实现类PublisherServiceImpl
package com.yuange.gmall.gmall_publisher.service;
import com.yuange.gmall.gmall_publisher.beans.DAUData;
import com.yuange.gmall.gmall_publisher.mapper.PublisherMapper;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.util.List;
/**
* @作者:袁哥
* @时间:2021/7/6 23:15
*/
@Service
public class PublisherServiceImpl implements PublisherService{
@Autowired
private PublisherMapper publisherMapper;
@Override
public Integer getDAUByDate(String date) {
return publisherMapper.getDAUByDate(date);
}
@Override
public Integer getNewMidCountByDate(String date) {
return publisherMapper.getNewMidCountByDate(date);
}
@Override
public List<DAUData> getDAUDatasByDate(String date) {
return publisherMapper.getDAUDatasByDate(date);
}
}
2.5.5 controller层,GmallPublisherController.java
package com.yuange.gmall.gmall_publisher.controller;
import com.alibaba.fastjson.JSONObject;
import com.yuange.gmall.gmall_publisher.beans.DAUData;
import com.yuange.gmall.gmall_publisher.service.PublisherService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.time.LocalDate;
import java.util.ArrayList;
import java.util.List;
/**
* @作者:袁哥
* @时间:2021/7/6 23:10
*/
@RestController
public class GmallPublisherController {
@Autowired
private PublisherService publisherService;
@RequestMapping(value = "/realtime-total")
public Object handle1(String date){
ArrayList<JSONObject> result = new ArrayList<>();
Integer dau = publisherService.getDAUByDate(date);
Integer newMidCounts = publisherService.getNewMidCountByDate(date);
JSONObject jsonObject1 = new JSONObject();
jsonObject1.put("id","dau");
jsonObject1.put("name","新增日活");
jsonObject1.put("value",dau);
JSONObject jsonObject2 = new JSONObject();
jsonObject2.put("id","new_mid");
jsonObject2.put("name","新增设备");
jsonObject2.put("value",newMidCounts);
result.add(jsonObject1);
result.add(jsonObject2);
return result;
}
@RequestMapping(value = "/realtime-hours")
public Object handle2(String id,String date){
//根据今天求昨天的日期
LocalDate toDay = LocalDate.parse(date);
String yestodayDate = toDay.minusDays(1).toString();
List<DAUData> todayDatas = publisherService.getDAUDatasByDate(date);
List<DAUData> yestodayDatas = publisherService.getDAUDatasByDate(yestodayDate);
JSONObject jsonObject1 = parseData(todayDatas);
JSONObject jsonObject2 = parseData(yestodayDatas);
JSONObject result = new JSONObject();
result.put("yesterday",jsonObject2);
result.put("today",jsonObject1);
return result;
}
//负责把 List<DAUData> 封装为一个JSONObject
public JSONObject parseData(List<DAUData> datas){
JSONObject jsonObject = new JSONObject();
for (DAUData data : datas) {
jsonObject.put(data.getHour(),data.getNum());
}
return jsonObject;
}
}
2.5.6 数据层 实现配置,PublisherMapper.xml

<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<!--
接口式编程有要求:
namespace: 代表当前mapper文件的id,必须和接口的全类名一致
-->
<mapper namespace="com.yuange.gmall.gmall_publisher.mapper.PublisherMapper">
<!-- 常见的基本数据类型及包装类,在Mybatis中,可以简写-->
<select id="getDAUByDate" resultType="int">
select
count(*)
from GMALL_STARTUP_LOG
where LOGDATE = #{date}
</select>
<!--
求当天新设备的活跃数
正常情况下,应该有一张 new_mid表,表中记录每一天新注册的设备信息
GMALL2020_DAU:记录了每一天,活跃的设备信息
今天活跃的所有设备 差集 今日之前活跃的所有设备
差集 : A left join B on A.id=B.id where B.id is null
< 在 xml中,误认为是便签的开始符号,需要转义为<
-->
<select id="getNewMidCountByDate" resultType="int">
select
count(*)
from
( select
mid
from GMALL_STARTUP_LOG
where LOGDATE = #{date} ) t1
left join
(
select
mid
from GMALL_STARTUP_LOG
where LOGDATE < #{date}
group by mid
) t2
on t1.mid=t2.mid
where t2.mid is null
</select>
<!-- 查询的列名要和封装的Bean的属性名一致,才能封装上 -->
<select id="getDAUDatasByDate" resultType="com.yuange.gmall.gmall_publisher.beans.DAUData" >
select
LOGHOUR hour,count(*) num
from GMALL_STARTUP_LOG
where LOGDATE = #{date}
group by LOGHOUR
</select>
</mapper>
2.5.7 首页,index.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<a href="/realtime-total?date=2021-07-05">统计每日日活和新增设备</a>
<br/>
<a href="/realtime-hours?id=dau&date=2021-07-05">统计昨天和今天的分时DAU数据</a>
</body>
</html>
2.6 根据查询条件增加索引
create local index idx_logdate_loghour on GMALL_STARTUP_LOG(logdate,loghour);

2.7 测试