聚合操作是spark运算中特别常见的一种行为。比如分析用户一天的活着一次登陆的行为,就要把日志按用户id进行聚合,然后做排序、求和、求平均之类的运算……而spark中对于聚合操作的蒜子也比较丰富,本文主要结合作者个人的经验和网上资料,对这几个算子进行整理和比较。
这里,一般都是对Pair RDD 进行的聚合操作。首先,什么是pair RDD
Spark为包含键值对类型的RDD提供了一些专有的操作。这些RDD被称为Pair RDD【《spark 快速大数据分析》】。
关于Pair RDD 这篇博客 讲的挺详细的http://blog.csdn.net/gamer_gyt/article/details/51747783
Pair RDD又叫做键值对RDD 键值对RDD通常用来进行聚合运算的(书中原话)。spark 快速大数据分析书中有专门一章来介绍pair rdd 但是对几个聚合运算算子的比较几乎没有,以下结合网上的资料进行的整理。
1.reduceByKey和groupByKey的比较:
贴一段经典的代码:
val conf = new SparkConf().setAppName("GroupAndReduce").setMaster("local")
val sc = new SparkContext(conf)
val words = Array("one", "two", "two", "three", "three", "three")
val wordsRDD = sc.parallelize(words).map(word => (word, 1))
val wordsCountWithReduce = wordsRDD.
reduceByKey(_ + _).
collect().
foreach(println)
val wordsCountWithGroup = wordsRDD.
groupByKey().
map(w => (w._1, w._2.sum)).
collect().
foreach(println)
1.reduceByKey可以传入自定义函数,而groupByKey不可以,但是groupByKey省事啊(误)
官方文档(spark2.1.1):
| groupByKey([numTasks]) | When called on a dataset of (K, V) pairs, returns a dataset of (K, Iterable<V>) pairs. 当对(K,V)对的数据集进行调用时,返回(K,Iterable <V>)对的数据集。Note: If you are grouping in order to perform an aggregation (such as a sum or average) over each key, using reduceByKey or aggregateByKey will yield much better performance. 如果要分组以便在每个键上执行聚合(如总和或平均值),则使用reduceByKey或aggregateByKey将会产生更好的性能。 Note: By default, the level of parallelism in the output depends on the number of partitions of the parent RDD. You can pass an optional numTasks argument to set a different number of tasks.默认情况下,输出中的并行级别取决于父RDD的分区数。您可以传递一个可选的numTasks参数来设置不同数量的任务。 |
| reduceByKey(func, [numTasks]) | When called on a dataset of (K, V) pairs, returns a dataset of (K, V) pairs where the values for each key are aggregated using the given reduce function func, which must be of type (V,V) => V. Like in groupByKey, the number of reduce tasks is configurable through an optional second argument. 其中每个密钥的值使用给定的reduce函数func进行聚合,该函数必须是类型(V,V)=> V。与groupByKey类似,reduce任务的数量可以通过可选的第二个参数进行配置。 |
| aggregateByKey(zeroValue)(seqOp, combOp, [numTasks]) | When called on a dataset of (K, V) pairs, returns a dataset of (K, U) pairs where the values for each key are aggregated using the given combine functions and a neutral "zero" value. Allows an aggregated value type that is different than the input value type, while avoiding unnecessary allocations. Like in groupByKey, the number of reduce tasks is configurable through an optional second argument. 其中每个键的值使用给定的组合函数和中性“零”值进行聚合。允许不同于输入值类型的聚合值类型,同时避免不必要的分配。像groupByKey一样,reduce任务的数量可以通过可选的第二个参数进行配置。 |
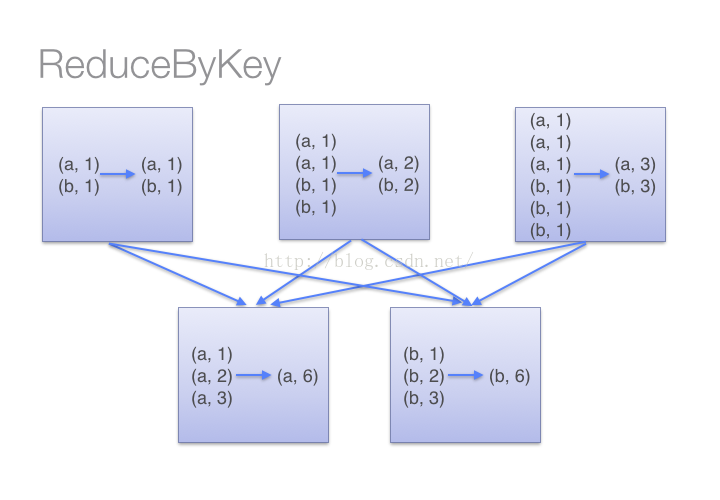
1)当采用reduceByKeyt时,Spark可以在每个分区移动数据之前将待输出数据与一个共用的key结合。借助下图可以理解在reduceByKey里究竟发生了什么。 注意在数据对被搬移前同一机器上同样的key是怎样被组合的(reduceByKey中的lamdba函数)。然后lamdba函数在每个区上被再次调用来将所有值reduce成一个最终结果。整个过程如下:
(2)当采用groupByKey时,由于它不接收函数,spark只能先将所有的键值对(key-value pair)都移动,这样的后果是集群节点之间的开销很大,导致传输延时。整个过程如下:
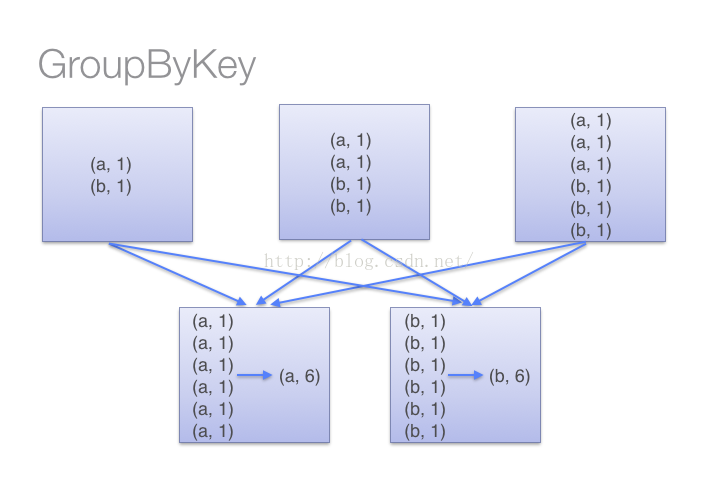
2.在对大数据进行复杂计算时,reduceByKey优于groupByKey,reduceByKey在数据量比较大的时候会远远快于groupByKey。
另外,如果仅仅是group处理,那么以下函数应该优先于 groupByKey :
(1)、combineByKey 组合数据,但是组合之后的数据类型与输入时值的类型不一样。
(2)、foldByKey合并每一个 key 的所有值,在级联函数和“零值”中使用。
2.reduceByKey 的使用
1.简单的例子:
该函数必须是类型(V,V)=> V
val counts = pairs.reduceByKey((a, b) => a + b)
2.reduceByKey的作用域是key-value类型的键值对,并且是只对每个key的value进行处理,如果含有多个key的话,那么就对多个values进行处理。这里的函数是我们自己传入的,也就是说是可人为控制的
简单来讲,这个V实际上就是value,你要写一个函数,对同一个key 对两个value有什么操作?最简单的,相加!你就写(a, b) => a + b 或者(pre, after) => pre + after 都可以
3.combineByKey 的使用
combineByKey函数主要接受了三个函数作为参数,分别为createCombiner、mergeValue、mergeCombiners。这三个函数足以说明它究竟做了什么。理解了这三个函数,就可以很好地理解combineByKey。
要理解combineByKey(),要先理解它在处理数据时是如何处理每个元素的。由于combineByKey()会遍历分区中的所有元素,因此每个元素的键要么还没有遇到过,要么就和之前的键相同。combineByKey()的处理流程如下:
-
如果是一个新的元素,此时使用createCombiner()来创建那个键对应的累加器的初始值。(!注意:这个过程会在每个分区第一次出现各个键时发生,而不是在整个RDD中第一次出现一个键时发生。)
-
如果这是一个在处理当前分区中之前已经遇到键,此时combineByKey()使用mergeValue()将该键的累加器对应的当前值与这个新值进行合并。
3.由于每个分区都是独立处理的,因此对于同一个键可以有多个累加器。如果有两个或者更多的分区都有对应同一个键的累加器,就需要使用用户提供的mergeCombiners()将各个分区的结果进行合并。