(一)时间复杂度----依赖算法输入数据的规模
如果时间复杂度为O(1),说明无论算法输入的数据个数是多少,运行时间都相同。
O(n)代表算法的执行时间与输入的数据元素个数成正比。
O(n^2)代表程序时间复杂度与输入数据元素数目的平方成正比。
(二)二分搜索
二分搜索是基于已排序数据的技术。
https://www.cnblogs.com/kyoner/p/11080078.html

def binary_search(list, item):
# low and high 限定在列表中查找的范围.
low = 0
high = len(list) - 1
while low <= high:
mid = (low + high) // 2
guess = list[mid]
# 查找到指定项,返回下标.
if guess == item:
return mid
# 当前数值过大时,降低上限值.
if guess > item:
high = mid - 1
# 当前数值过小时,提高下限值.
else:
low = mid + 1
# 查找项不存在返回None
return None
my_list = [1, 3, 5, 7, 9]
print(binary_search(my_list, 3)) # => 1
# 查找项不存在返回None.
print(binary_search(my_list, -1)) # => None
原文链接:https://blog.csdn.net/xiaodianzichen/java/article/details/80400012
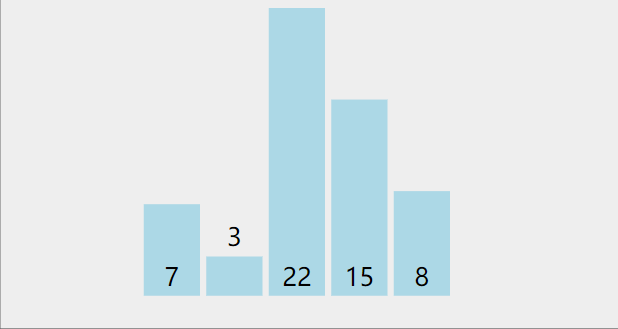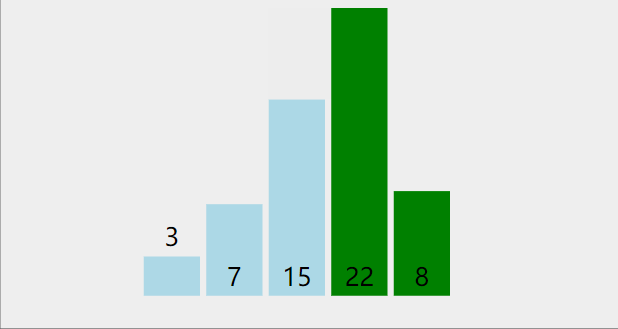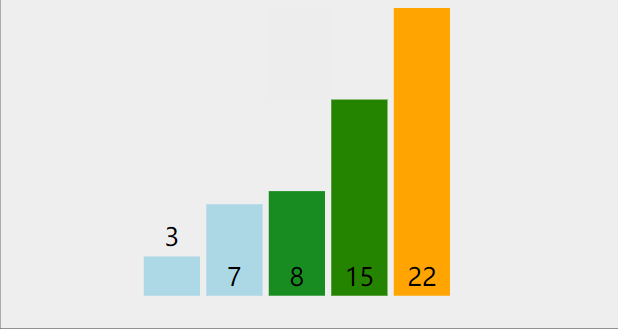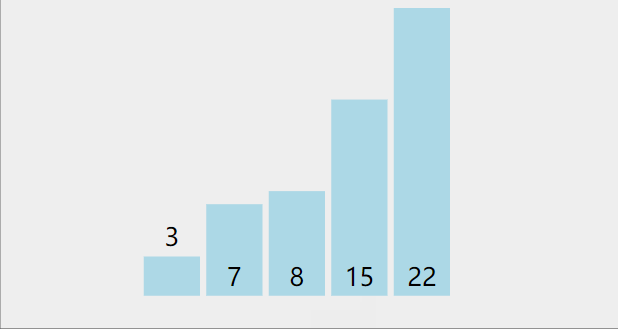
(三)冒泡排序
逐个比较相邻元素,如果后者比前者小,则交换位置。
一个大小为n的数组,需要n-1趟处理
每一趟的值从1增加到n-1
(四)快速排序
首先选择一个枢纽元素,然后重新排序当前元素,是的枢纽元素左边的元素都小于等于它,而其右边的元素大于等于它。
https://blog.csdn.net/weixin_42437295/article/details/90771962

https://blog.csdn.net/m0_37907797/article/details/102835456