在学习Python爬虫的时候,突然报错:urllib.error.HTTPError: HTTP Error 403: Forbidden
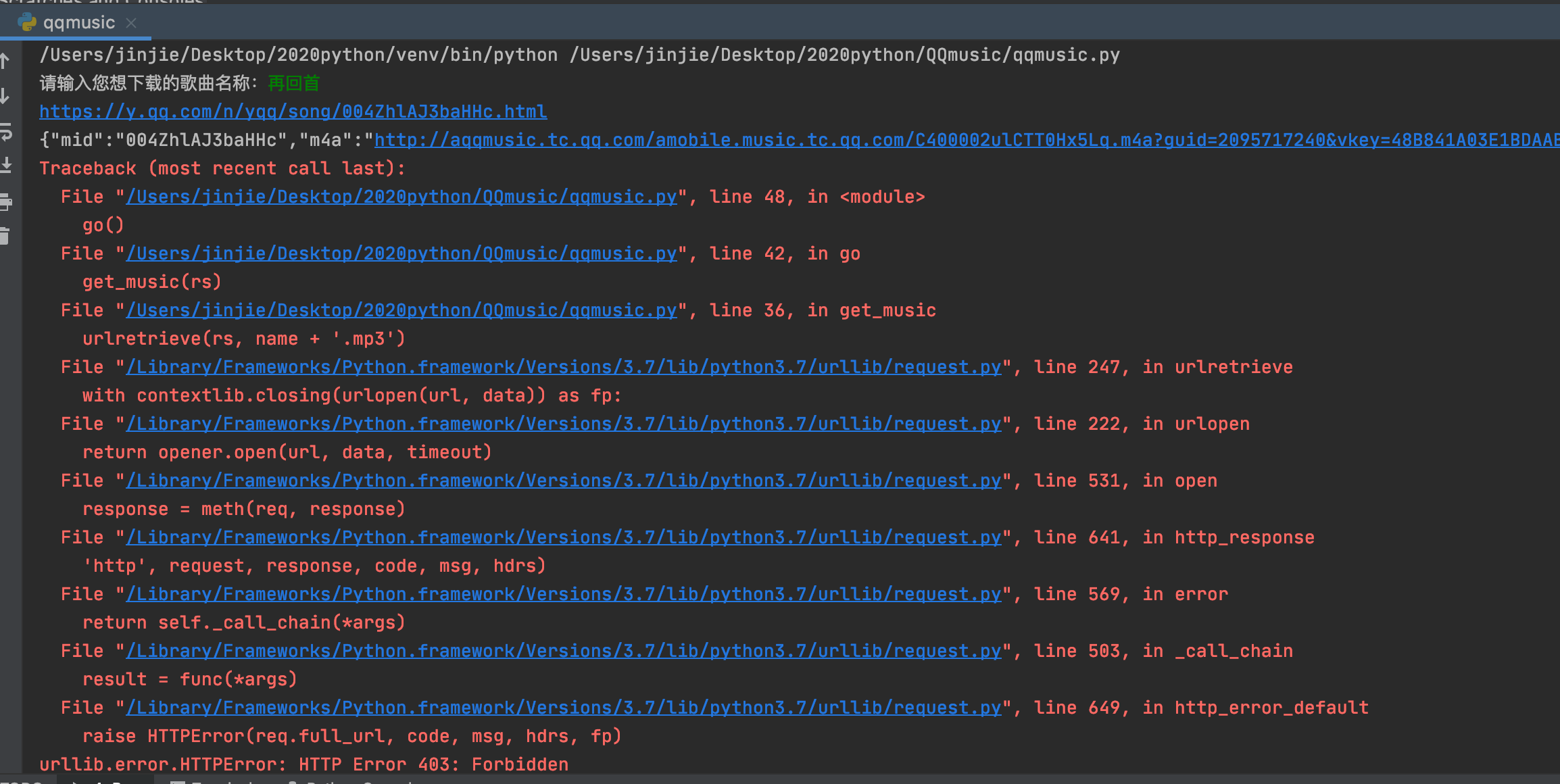
问题原因:出现该错误的原因是服务器开启了反爬虫,一般情况下只需要设置header模拟浏览器即可,但是urlretrieve并未提供header参数。
解决方案一:使用urlopen直接下载文件:(亲测好用)
header = { #伪造浏览器头部,不然获取不到网易云音乐的页面源代码
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:76.0) Gecko/20100101 Firefox/76.0' #根据浏览器不同进行替换,实例为火狐
}
def get_music(rs):
response = requests.get(rs, headers=header).content # 必须要加headers信息,不然获取不到
f = open(name + ".mp3", 'wb') # 以二进制的形式写入文件中
f.write(response)
f.close()解决方案二:使用urlretrieve进行下载:(亲测,不是太好用)
opener=urllib.request.build_opener() opener.addheaders=[('User-Agent','Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/36.0.1941.0 Safari/537.36')] urllib.request.install_opener(opener) urllib.request.urlretrieve(url, Path)