1.输出某个英文文本文件中 26 字母出现的频率,由高到低排列,并显示字母出现的百分比,精确到小数点后面两位。
源代码:
import java.io.*; import java.text.DecimalFormat; import java.util.*; public class Test { public static void main(String[] args){ demo(new File("C:\Harry Potter and the Sorcerer's Stone.txt")); } public static void demo(File file){ BufferedReader bfr = null; try{ DecimalFormat df = new DecimalFormat("######0.00"); int sum = 0; int i = 0; double[] ss = new double[99]; char[] en = new char[99]; int[] num = new int[99]; bfr = new BufferedReader(new FileReader(file)); String value = null; String newValue = ""; while((value = bfr.readLine())!=null){ newValue = newValue+value; } char[] ch = newValue.toCharArray(); TreeMap<Character,Integer> tm = new TreeMap<Character,Integer>(Collections.reverseOrder()); for(int x = 0;(x<ch.length);x++){ char c = ch[x]; if(tm.containsKey(c)){ int conut = tm.get(c); tm.put(c,conut+1); } else{ tm.put(c, 1); } } Set<Map.Entry<Character, Integer>> set = tm.entrySet(); Iterator<Map.Entry<Character, Integer>> iter = set.iterator(); while(iter.hasNext()){ Map.Entry<Character, Integer> map = iter.next(); char k = map.getKey(); int v = map.getValue(); if(((k>='a')&&(k<='z'))||((k>='A')&&(k<='Z'))) { num[i] = v; en[i] = k; i++; } } for(int h=0;h<i;h++) { sum = sum + num[h]; } for(int j=0;j<i;j++) { ss[j] = (double) (((double)num[j]*100)/(double)sum); } for(int k=0;k<26;k++) { for(int m=0;m<26-1-k;m++) { if(ss[m+1]>ss[m]) { double t=ss[m]; char g = en[m]; en[m]=en[m+1]; en[m+1]=g; ss[m]=ss[m+1]; ss[m+1]=t; } } } for(int n=0;n<i;n++) { System.out.print(en[n]+" "); System.out.print(df.format(ss[n])); System.out.println("%"); } } catch(IOException e){ System.out.println("文件读取错误"); } finally{ try{ if(bfr!=null) bfr.close(); } catch(IOException e){ System.out.println("文件关闭错误"); } } } }
部分运行截图:
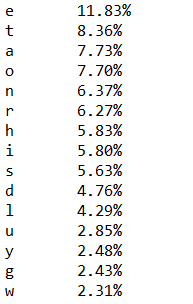
2. 输出单个文件中的前 N 个最常出现的英语单词。
源代码:
import java.io.BufferedReader; import java.io.File; import java.io.FileReader; import java.io.IOException; import java.util.*; public class Eng { class Word { String value; int num; Word next; public Word(String value,int num) { this.value=value; this.num=num; next=null; } public Word() { this.value=""; this.num=0; next=null; } } public void getFileList() throws IOException { BufferedReader br=new BufferedReader(new FileReader("C:\Harry Potter and the Sorcerer's Stone.txt")); TreeMap<Character,Integer> hm=new TreeMap<>(); int bb; while((bb=br.read())!=-1) { Word word=new Word(); Word linklist,nw; String str=""; char[] c=new char[1]; int b=0; boolean exist=false; while((b=br.read(c))!=-1) { if(String.valueOf(c).equals(" ")||String.valueOf(c).equals(" ")||String.valueOf(c).equals(" ")||String.valueOf(c).equals(",")||String.valueOf(c).equals(".")||String.valueOf(c).equals(""")||String.valueOf(c).equals("'")) { linklist=word; while(linklist!=null) { if(linklist.value.equalsIgnoreCase(str)) { linklist.num++;exist=true; break; } else { linklist=linklist.next; } } if(exist==false) { nw=new Word(str,1); nw.next=word.next; word.next=nw; str=""; } else { exist=false; str=""; } } else //单词 { str+=String.valueOf(c); } } System.out.print("请输入您想查询的前几个出现此处最多的单词:"); Scanner scan=new Scanner(System.in); int N=scan.nextInt(); for(int i=1;i<=N;i++) { nw=new Word("",0); linklist=word.next; while(linklist!=null) { if(linklist.num>nw.num) { nw=linklist; } linklist=linklist.next; } System.out.println("第"+i+"个 :"+nw.value+" 个数:"+nw.num); linklist=word; while(linklist.next!=null) { if(linklist.next.value.equalsIgnoreCase(nw.value)) { linklist.next=linklist.next.next; break; } linklist=linklist.next; } } } } public static void main(String[] args) throws IOException { Eng rf = new Eng(); rf.getFileList(); } }
运行截图:

