转载请注明:@小五义http://www.cnblogs.com/xiaowuyi
6.1 最简单的爬虫
网络爬虫是一个自动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成。python的urllib\urllib2等模块很容易实现这一功能,下面的例子实现的是对baidu首页的下载。具体代码如下:
import urllib2 page=urllib2.urlopen("http://www.baidu.com") print page.read()
6.2 提交表单数据
(1)用GET方法提交数据
提交表单的GET方法是把表单数据编码至URL。在给出请示的页面后,加上问号,接着是表单的元素。如在百度中搜索“马伊琍”得到url为http://www.baidu.com/s?wd=%E9%A9%AC%E4%BC%8A%E7%90%8D&pn=100&rn=20&ie=utf-8&usm=4&rsv_page=1。其中?后面为表单元素。wd=%E9%A9%AC%E4%BC%8A%E7%90%8D表示搜索的词是“马伊琍”,pn表示从第100条信息所在页开始显示(感觉是这样,我试了几次,当写100时,从其所在页显示,但如果写10,就是从第1页显示),rn=20表示每页显示20条,ie=utf-8表示编码格式,usm=4没明白是什么意思,换了1、2、3试了下,没发现什么变化,rsv_page=1表示第几页。如果要下载以上页面比较简单的方法是直接用上面的网址进行提取。如代码:
import urllib2 keyword=urllib.quote('马伊琍') page=urllib2.urlopen("http://www.baidu.com/s?wd="+keyword+"&pn=100&rn=20&ie=utf-8&usm=4&rsv_page=1") print page.read()
(2)用post方法提交
GET方法中,数据是被加到URL上,这种方法数据量要求不大,如果需要交换大量数据的时间,POST方法是一个很好的方法。这里以前段时间写的博客《python模拟163登陆获取邮件列表》为例,具体代码不在列出,详见地址:http://www.cnblogs.com/xiaowuyi/archive/2012/05/21/2511428.html。
6.3 urllib,urllib2,httplib,mechanize的介绍
6.3.1urllib模块(引自:http://my.oschina.net/duhaizhang/blog/68893)
urllib模块提供接口可以使我们像访问本地文件一样来读取www和ftp上的数据。模块中最重要的两个函数分别是:urlopen()和urlretrieve()。
urllib.urlopen(url[, data[, proxies]]) :
本函数创建一个表示远程url的类文件对象,然后像本地文件一样操作这个类文件对象来获取远程数据。参数url表示远程数据的路径,一般是网址;参数data表示以post方式提交到url的数据;参数proxies用于设置代理。urlopen返回 一个类文件对象,返回的类文件对象提供了如下方法:
read(), readline(), readlines(), fileno(), close():这些方法的使用方式与文件对象完全一样;
info():返回一个httplib.HTTPMessage对象,表示远程服务器返回的头信息;
getcode():返回Http状态码。如果是http请求,200表示请求成功完成;404表示网址未找到;
geturl():返回请求的url;

#! /usr/bin/env python #coding=utf-8 import urllib content=urllib.urlopen("http://www.baidu.com") print "http header:",content.info() print "http status:",content.getcode() print "url:",content.geturl() print "content:" for line in content.readlines(): print line
urllib.urlretrieve(url[, filename[, reporthook[, data]]]):
urlretrieve方法直接将远程数据下载到本地。参数filename指定了保存到本地的路径(如果未指定该参数,urllib会生成一个临时文件来保存数据);参数reporthook是一个 回调函数,当连接上服务器、以及相应的数据 块传输完毕的时候会触发该回调(即每下载一块就调用一次回调函数)。我们可以利用这个回调函 数来显示当前的下载进度,也可以用于限速,下面的例子会展示。参数data指post到服务器的数据。该方法返回一个包含两个元素的元组(filename, headers),filename表示保存到本地的路径, header表示服务器的响应头。
#! /usr/bin/env python # coding: utf-8 """下载文件,并显示下载进度""" import urllib def DownCall(count,size,total_filesize): """count为已下载数据块个数,size为数据块的大小,total_filesize为文件总大小""" per=100.0*count*size/total_filesize if per>100: per=100 print "Already download %d KB(%.2f" %(count*size/1024,per)+"%)" url="http://www.research.rutgers.edu/~rohanf/LP.pdf" localfilepath=r"C:\Users\Administrator\Desktop\download.pdf" urllib.urlretrieve(url,localfilepath,DownCall)
urllib中还提供了一些辅助方法,用于对url进行编码、解码。url中是不能出现一些特殊的符号的,有些符号有特殊的用途。我们知道以get方式提交数据的时候,会在url中添加key=value这样的字符串,所以在value中是不允许有'=',因此要对其进行编码;与此同时服务器接收到这些参数的时候,要进行解码,还原成原始的数据。这个时候,这些辅助方法会很有用:
urllib.quote(string[, safe]):对字符串进行编码。参数safe指定了不需要编码的字符;
urllib.unquote(string) :对字符串进行解码;
urllib.quote_plus(string[, safe]) :与urllib.quote类似,但这个方法用'+'来替换' ',而quote用'%20'来代替' '
urllib.unquote_plus(string) :对字符串进行解码;
urllib.urlencode(query[, doseq]):将dict或者包含两个元素的元组列表转换成url参数。例如 字典{'name': 'dark-bull', 'age': 200}将被转换为"name=dark-bull&age=200"
urllib.pathname2url(path):将本地路径转换成url路径;
urllib.url2pathname(path):将url路径转换成本地路径;
6.3.2 urllib2模块(引自:http://hankjin.blog.163.com/blog/static/3373193720105140583594/)
使用Python访问网页主要有三种方式: urllib, urllib2, httplib
urllib比较简单,功能相对也比较弱,httplib简单强大,但好像不支持session
(1)最简单的页面访问
res=urllib2.urlopen(url)
print res.read()
(2)加上要get或post的数据
data={"name":"hank", "passwd":"hjz"}
urllib2.urlopen(url, urllib.urlencode(data))
(3)加上http头
header={"User-Agent": "Mozilla-Firefox5.0"}
urllib2.urlopen(url, urllib.urlencode(data), header)
使用opener和handler
opener = urllib2.build_opener(handler)
urllib2.install_opener(opener)
(4)加上session
cj = cookielib.CookieJar()
cjhandler=urllib2.HTTPCookieProcessor(cj)
opener = urllib2.build_opener(cjhandler)
urllib2.install_opener(opener)
(5)加上Basic认证
password_mgr = urllib2.HTTPPasswordMgrWithDefaultRealm()
top_level_url = "http://www.163.com/"
password_mgr.add_password(None, top_level_url, username, password)
handler = urllib2.HTTPBasicAuthHandler(password_mgr)
opener = urllib2.build_opener(handler)
urllib2.install_opener(opener)
(6) 使用代理
proxy_support = urllib2.ProxyHandler({"http":"http://1.2.3.4:3128/"})
opener = urllib2.build_opener(proxy_support)
urllib2.install_opener(opener)
(7) 设置超时
socket.setdefaulttimeout(5)
6.3.3 httplib模块(引自:http://hi.baidu.com/avengert/item/be5daec8517b12ddee183b81)
httplib 是 python中http 协议的客户端实现,可以使用该模块来与 HTTP 服务器进行交互。httplib的内容不是很多,也比较简单。以下是一个非常简单的例子,使用httplib获取google首页的html:
#coding=gbk import httplib conn = httplib.HTTPConnection("www.google.cn") conn.request('get', '/') print conn.getresponse().read() conn.close()
下面详细介绍httplib提供的常用类型和方法。
httplib.HTTPConnection ( host [ , port [ , strict [ , timeout ]]] )
HTTPConnection类的构造函数,表示一次与服务器之间的交互,即请求/响应。参数host表示服务器主机,如:www.csdn.net;port为端口号,默认值为80; 参数strict的 默认值为false, 表示在无法解析服务器返回的状态行时( status line) (比较典型的状态行如: HTTP/1.0 200 OK ),是否抛BadStatusLine 异常;可选参数timeout 表示超时时间。
HTTPConnection提供的方法:
HTTPConnection.request ( method , url [ , body [ , headers ]] )
调用request 方法会向服务器发送一次请求,method 表示请求的方法,常用有方法有get 和post ;url 表示请求的资源的url ;body 表示提交到服务器的数据,必须是字符串(如果method 是"post" ,则可以把body 理解为html 表单中的数据);headers 表示请求的http 头。
HTTPConnection.getresponse ()
获取Http 响应。返回的对象是HTTPResponse 的实例,关于HTTPResponse 在下面 会讲解。
HTTPConnection.connect ()
连接到Http 服务器。
HTTPConnection.close ()
关闭与服务器的连接。
HTTPConnection.set_debuglevel ( level )
设置高度的级别。参数level 的默认值为0 ,表示不输出任何调试信息。
httplib.HTTPResponse
HTTPResponse表示服务器对客户端请求的响应。往往通过调用HTTPConnection.getresponse()来创建,它有如下方法和属性:
HTTPResponse.read([amt])
获取响应的消息体。如果请求的是一个普通的网页,那么该方法返回的是页面的html。可选参数amt表示从响应流中读取指定字节的数据。
HTTPResponse.getheader(name[, default])
获取响应头。Name表示头域(header field)名,可选参数default在头域名不存在的情况下作为默认值返回。
HTTPResponse.getheaders()
以列表的形式返回所有的头信息。
HTTPResponse.msg
获取所有的响应头信息。
HTTPResponse.version
获取服务器所使用的http协议版本。11表示http/1.1;10表示http/1.0。
HTTPResponse.status
获取响应的状态码。如:200表示请求成功。
HTTPResponse.reason
返回服务器处理请求的结果说明。一般为”OK”
下面通过一个例子来熟悉HTTPResponse中的方法:
#coding=gbk import httplib conn = httplib.HTTPConnection("www.g.cn", 80, False) conn.request('get', '/', headers = {"Host": "www.google.cn", "User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9.1) Gecko/20090624 Firefox/3.5", "Accept": "text/plain"}) res = conn.getresponse() print 'version:', res.version print 'reason:', res.reason print 'status:', res.status print 'msg:', res.msg print 'headers:', res.getheaders() #html #print '\n' + '-' * 50 + '\n' #print res.read() conn.close()
Httplib模块中还定义了许多常量,如:
Httplib. HTTP_PORT 的值为80,表示默认的端口号为80;
Httplib.OK 的值为200,表示请求成功返回;
Httplib. NOT_FOUND 的值为40表示请求的资源不存在;
可以通过httplib.responses 查询相关变量的含义,如:
Print httplib.responses[httplib.NOT_FOUND]
6.3.4 mechanize
mechanize没有找到比较完整的介绍,自己写了一个简单的例子如下。
# -*- coding: cp936 -*- import time,string import mechanize,urllib from mechanize import Browser urlname=urllib.quote('马伊琍') br=Browser() br.set_handle_robots(False) ##ignore the robots.txt urlhttp=r'http://www.baidu.com/s?'+urlname+"&pn=10&rn=20&ie=utf-8&usm=4&rsv_page=1" response=br.open(urlhttp) filename='temp.html' f=open(filename,'w') f.write(response.read()) f.close()
3. Descriptor介绍
3.1 Descriptor代码示例
"""创建一个Descriptor类,用来打印出访问它的操作信息
"""
def __init__(self, initval=None, name='var'):
self.val = initval
self.name = name
def __get__(self, obj, objtype):
print 'Retrieving', self.name
return self.val
def __set__(self, obj, val):
print 'Updating' , self.name
self.val = val
#使用Descriptor
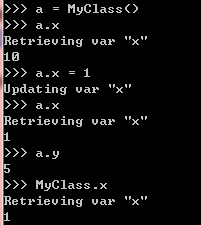
class MyClass(object):
#生成一个Descriptor实例,赋值给类MyClass的x属性
x = RevealAccess(10, 'var "x"')
y = 5 #普通类属性
3.2 定义
3.3 Descriptor Protocol(协议)
3.4 Descriptor调用方法

"模拟type.__getattribute__()实现"
#通过默认方式查找到目标
v = object.__getattribute__(self, key)
#如果目标属性含有__get__方法,则表示它是一个descriptor
if hasattr(v, '__get__'):
#优先使用descriptor中定义的方法返回值
return v.__get__(None, self)
#如果不是descriptor,就按默认的方式返回
return v
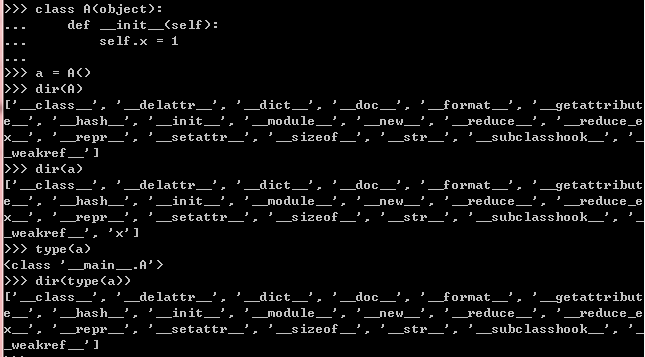
- descriptor是被__getattribute__方法调用的。
- 重写__getattribute__方法,会阻止自动的descriptor调用,必要时需要你自己加上去。
- __getattribute__方法只在新式类和新式实例中有用。
- object.__getattribute__和class.__getattribute__会用不一样的方式调用__get__
- data descriptors总是覆盖instance dictionary
- non-data descriptors有可能被instance dictionary覆盖
4. 基于Descriptor实现的功能
- Property
- 绑定和非绑定方法
- 静态方法
- 类方法
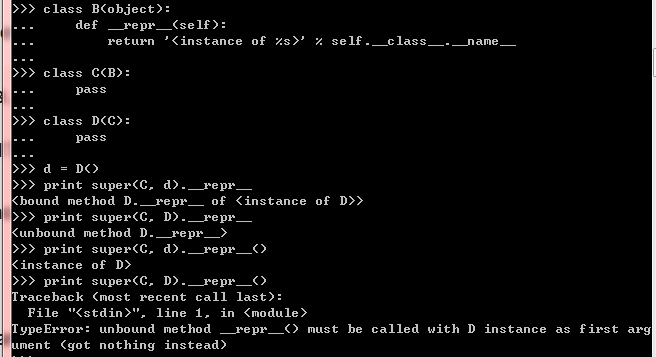
- super
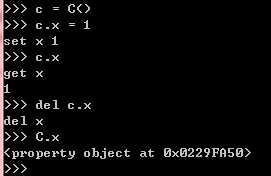
4.1 property
def getX(self):
print 'get x'
return self.__x
def setX(self, value):
print 'set x', value
self.__x = value
def delX(self):
print 'del x'
del self.__x
x = property(getX, setX, delX, "This is 'x' property.")
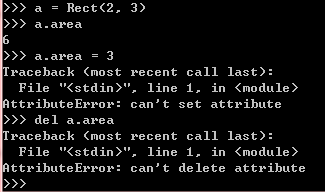
def __init__(self, width, heigth):
self.width = width
self.heigth = heigth
def getArea(self):
return self.width * self.heigth
area = property(getArea, doc='area of the rectangle')
"模拟在Objects/descrobject.c文件中的PyProperty_Type()函数"
def __init__(self, fget=None, fset=None, fdel=None, doc=None):
self.fget = fget
self.fset = fset
self.fdel = fdel
self.__doc__ = doc
def __get__(self, obj, objtype=None):
if obj is None:
return self
if self.fget is None:
raise AttributeError, "unreadable attribute"
return self.fget(obj)
def __set__(self, obj, value):
if self.fset is None:
raise AttributeError, "can't set attribute"
self.fset(obj, value)
def __delete__(self, obj):
if self.fdel is None:
raise AttributeError, "can't delete attribute"
self.fdel(obj)
4.2 函数和方法,绑定与非绑定
. . .
def __get__(self, obj, objtype=None):
"模拟Objects/funcobject.c文件中的func_descr_get()"
return types.MethodType(self, obj, objtype)
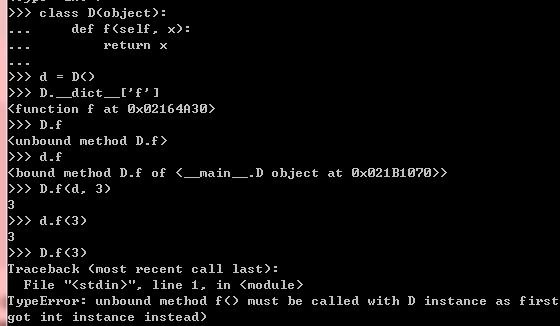
4.3 super
def __init__(self, type, obj=None):
self.__type__ = type
self.__obj__ = obj
def __get__(self, obj, type=None):
if self.__obj__ is None and obj is not None:
return Super(self.__type__, obj)
else:
return self
def __getattr__(self, attr):
if isinstance(self.__obj__, self.__type__):
starttype = self.__obj__.__class__
else:
starttype = self.__obj__
mro = iter(starttype.__mro__)
for cls in mro:
if cls is self.__type__:
break
# Note: mro is an iterator, so the second loop
# picks up where the first one left off!
for cls in mro:
if attr in cls.__dict__:
x = cls.__dict__[attr]
if hasattr(x, "__get__"):
x = x.__get__(self.__obj__)
return x
raise AttributeError, attr