一、摘要:
自注意力机制------从用户历史交互中推断出项目-项目关系。学习每个项目的相对权重【用来学习用户的暂时兴趣表示】
二、 模型:
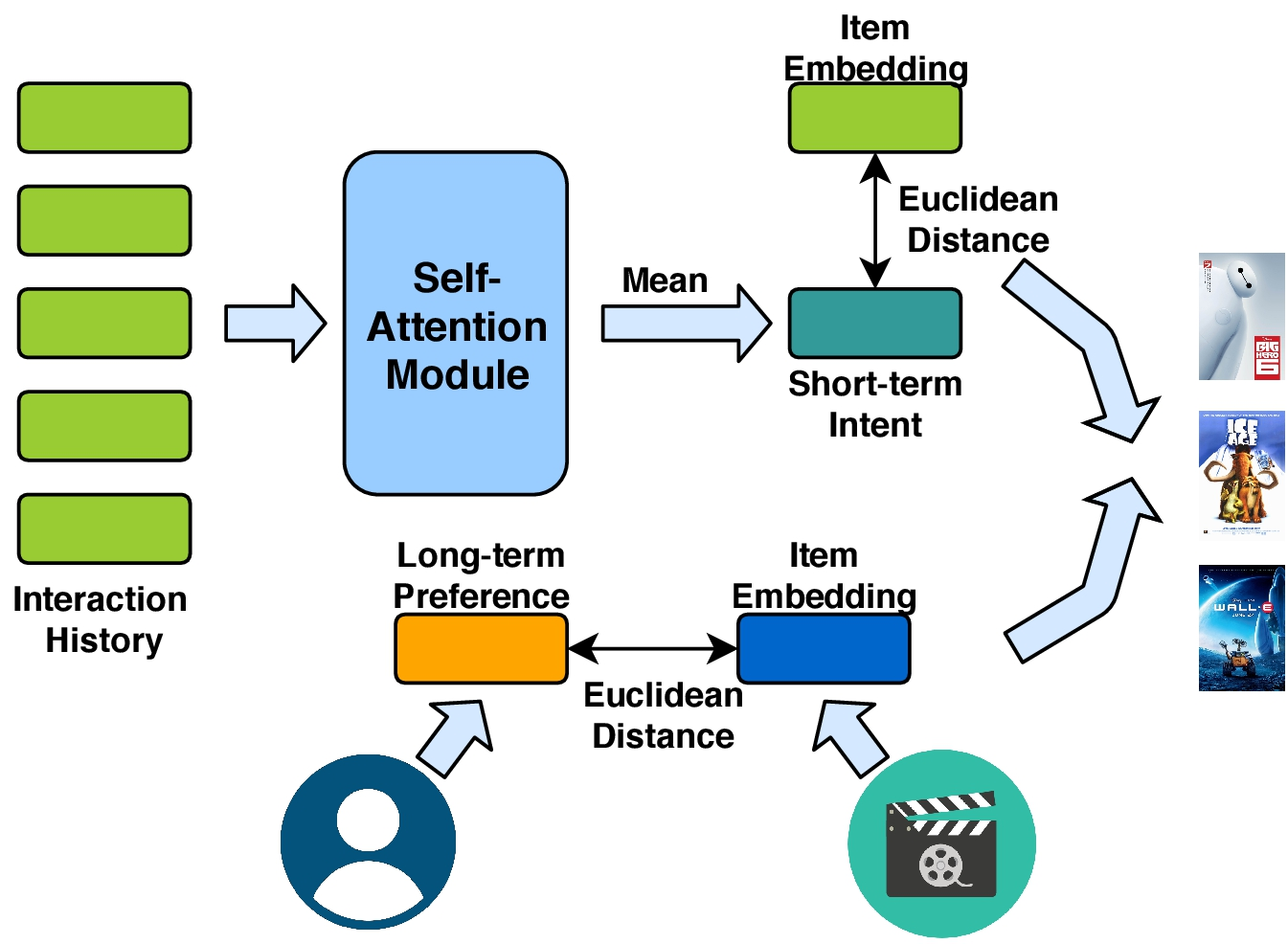
一部分是用于建模用户短期意图的自注意力机制,一部分是建模用户长期偏好的协作度量学习。
1、自注意力
自注意力可以保存上下文序列信息,并捕获序列中元素的关系。因此用自注意力来关注用户过去的行为。

输入:
query、key、value三值相等,并且都是又用户最近的历史记录L组成。其中每一项都可以由d维的嵌入向量表示。X ∈ RN×d表明全体item的嵌入表示。最新的L项(比如从t-L+1到t)按顺序放在在如下矩阵中:

输入嵌入的时间信号:以上的输入没有包括时间信号,没有序列信号。输入低级的词袋不能归保留序列模式。我们提议通过位置嵌入提供带有时间信息的query和key。我们使用一个时间尺度的几何序列来向输入端添加不同频率的正弦波。时间嵌入(TE)由以下两个正弦信号组成:
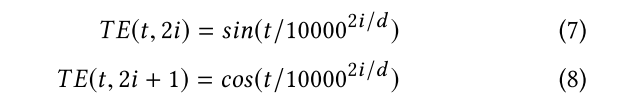
其中t是时间步长,i是维度。在非线性变换之前,TE加到query和key里。
模型:
将query和key通过共享参数的非线性变化整合到一个空间中。
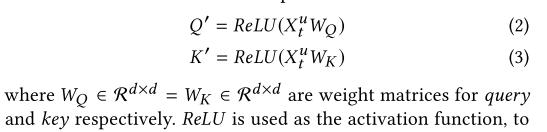
关联矩阵的计算如下:
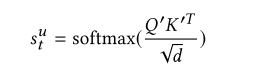
输出:
权重:
输出是L*L的关联矩阵(或注意力map),表明L项之间的相似度。
(归一化)注意根号d被用于收缩点积注意。在我们这个例子中,d通过设得比较大(比如100)。这样的话,缩放因子可以减小非常小的梯度效应。在softmax之前应用屏蔽操作(屏蔽关联矩阵的对角线),以避免相同的query向量和key之间的高匹配分数。(不是很理解)
关联矩阵和value相乘构成最后的自注意力机制的权重输出:(aut就表示用户短期意图的表示。)
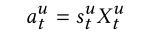
为了学习单个注意力表示,我们L自注意表示的均值嵌入作为用户瞬时意图。注意,其他的方式也可以(比如累加啊、求最大啊、最小啊),后面的实验将会比较效果。

2、用户长期喜好建模
在对短期效果进行建模之后,将用户的一般品味或长期偏好结合起来是有益的。和潜在因素方法相同,我们为每个用户和每个item分配一个潜在因素。让U属于RMd(Md为上标),V属于RNd(Nd为上标)表明users和item的潜在因素。然而,最新你的研究表明,点积操作违背了度量函数参数不等下的性质,并且将会导致次优解。为了避免这个问题,我们采用欧式距离去测量item i和user u的距离。
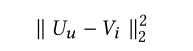
三、模型训练
目标函数:给定时间步t的短期意图,和长期偏好。我们的目标是预测用户u在时间t+1下的item(我们用Hu t+1表示,u为上标,t+1为下标)为了保证一致性,我们使用欧式距离,去建模短期和长期的影响。使用其和作为最后的推荐分数。
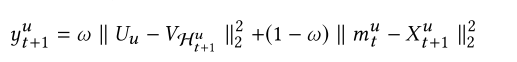
第一项是长期推荐的分数,第二项是短期推荐的分数。![]() 都是下一项item的嵌入向量,但是V和U是不一样的参数。最后的分数是由w控制的加权和。
都是下一项item的嵌入向量,但是V和U是不一样的参数。最后的分数是由w控制的加权和。
采用自适应梯度算法自动调整步长。