什么是不均衡数据

不均衡数据的形式很简单. 这里有苹果和梨, 当你发现你手中的数据对你说, 几乎全世界的人都只吃梨,
如果随便抓一个路人甲, 让你猜他吃苹果还是梨, 正常人都会猜测梨.
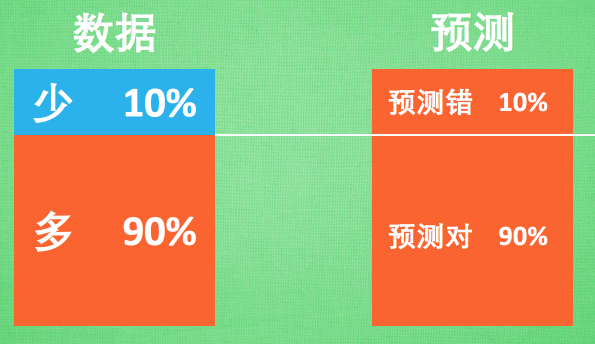
不均衡的数据预测起来很简单. 永远都猜多的那一方面准没错. 特别是红色多的那一方占了90%. 只需要每一次
预测的时候都猜红色, 预测准确率就已经达到了相当高的90%了. 没错, 机器也懂这个小伎俩. 所以机器学到最后,
学乖了, 每次都预测多数派. 解决的方法有几种, 我们来谈谈.
获取更多数据

首先, 我们要想想, 自己还能不能获取到更多的数据. 有时候只是因为前段时期的数据多半呈现的是一种趋势,
等到后半时期趋势又不一样了. 如果没有获取后半时期的数据, 整体的预测可能就没有那么准确了.
更换评判方式

通常, 我们会用到 准确率 accuracy, 或者误差 cost来判断机器学习的成果. 可是这些评判方法在不均衡数据面前,
高的准确率和低的误差变得没那么重要. 所以我们得换一种方式评判. 通过 confusion matrix 来计算 precision 和 recall,
然后通过 precision 和 recall 再计算f1 分数.这种方式能成功地区分不均衡数据, 给出更好的评判分数。
重组数据

第三种方法是最简单粗暴的方法之一. 重新组合不均衡数据, 使之均衡.
方式一: 复制或者合成少数部分的样本,使之和多数部分差不多数量.
方式二: 砍掉一些多数部分, 使两者数量差不多.
使用其他机器学习方法
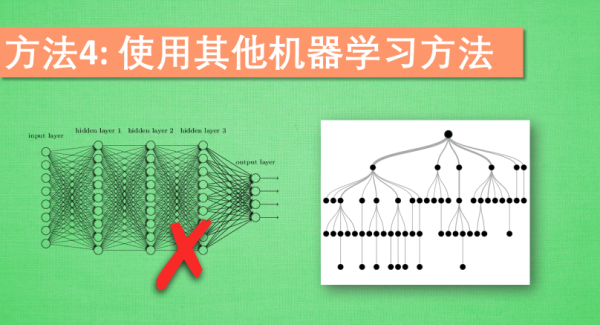
如果使用的机器学习方法像神经网络等, 在面对不均衡数据时, 通常是束手无策.
不过有些机器学习方法,像决策树, decision trees 就不会受到不均很数据的影响.
修改算法
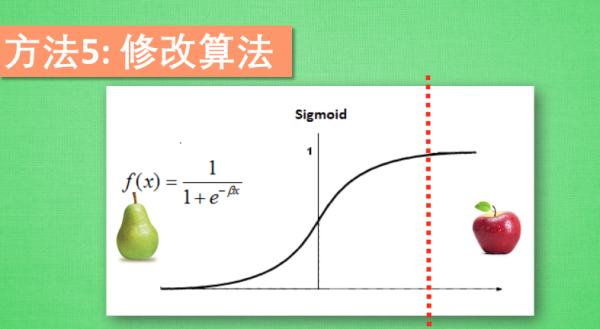
最后一种方法是让自己变得有创造力, 尝试修改算法. 如果你用的是 Sigmoid 的激励函数,
activation function, 他会有一个预测门槛, 一般如果输出结果落在门槛的这一段,预测结果为梨, 如果落在这一段,
预测结果为苹果, 不过因为现在的梨是多数派, 我们得调整一下门槛的位置, 使得门槛偏向苹果这边, 只有很自
信的时候, 模型才会预测这是苹果. 让机器学习,学习到更好的效果.