纹理特征,材料分类(Material Classification),在MINC-2500、Flickr Material Database、KTH-TIPS-2b、4D-Light-Field-Material、GTOS上state-of-the-art(2017年)。
思想主要来源是:传统图片分类方法都是提取人工设计的特征(SIFT等)然后使用BOW进行编码,再用SVM进行分类,后面BOW被VLAD、Fisher Vector编码替换并融合CNN特征可以达到sota的效果。然而这样的方法有缺点,就是编码和特征的学习并不是end-to-end的,所以作者设计了一个learnable residual encoding layer。作者还提到一般的CNN的方法虽然在图片分类和物体识别上有比较好的效果,但是在纹理识别上表现并不理想,给出的理由是:
``` recognizing textures needs for a spatially invariant representation describing the feature distributions instead of concatenation ```
这篇论文的主要贡献:
1. learnable residual encoding layer。能够生成鲁棒的残差编码例如(VLAD和Fisher Vector),能接收任意的输入分辨率,并且生成固定长度的特征表示,这种编码方式非常适合pretrained feature的迁移。关于该层的一个后向传播可以看论文的附录A,给了很清楚的推导。一个前向计算如下公式:
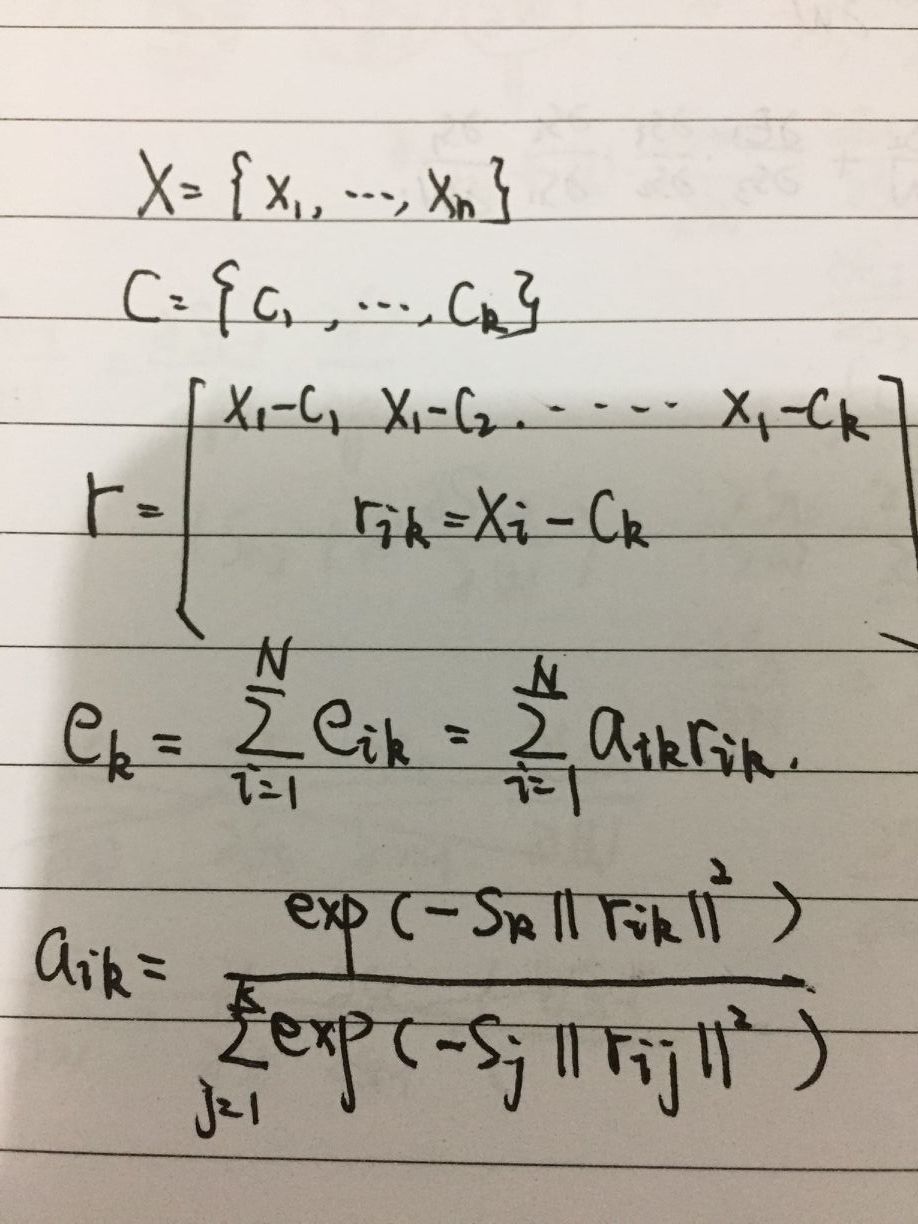
2.将feature extraction, dictionary learning, encoding 融合成一个end-to-end的形式。
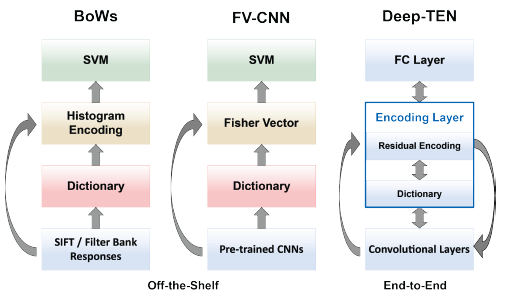
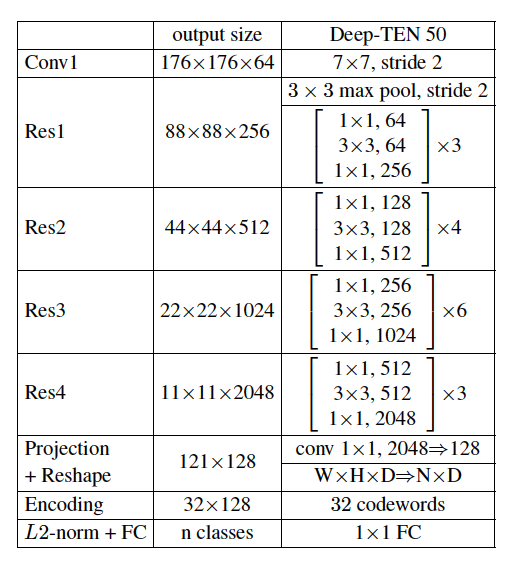
整个网络模型结构:
开源代码:
Pytorch:https://github.com/zhanghang1989/PyTorch-Encoding-Layer
FisherVector的教程:http://www.vlfeat.org/api/fisher-fundamentals.html
VLAD的教程:http://www.vlfeat.org/api/vlad-fundamentals.html