1、WordCount
Job类:
package com.simope.mr.wcFor; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; /** * @deprecated 统计文本单词个数 * @author JimLy * @see 20150127 * */ public class WcForJob { public static void main(String[] args) { Configuration conf = new Configuration(); try { Job job = new Job(conf); job.setJobName("myWC"); job.setJarByClass(WcForJob.class); job.setMapperClass(WcForMapper.class); job.setReducerClass(WcForReducer.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); FileInputFormat.addInputPath(job, new Path("/usr/input/myWc")); FileOutputFormat.setOutputPath(job, new Path("/usr/output/myWc")); System.exit(job.waitForCompletion(true) ? 0 : 1); } catch (Exception e) { System.out.println("错误信息:" + e); } } }
Mapper类:
package com.simope.mr.wcFor; import java.io.IOException; import java.util.StringTokenizer; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; public class WcForMapper extends Mapper<LongWritable, Text, Text, IntWritable> { @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString(); StringTokenizer st = new StringTokenizer(line); while (st.hasMoreElements()) { context.write(new Text(st.nextToken()), new IntWritable(1)); } } }
Reducer类:
package com.simope.mr.wcFor; import java.io.IOException; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; public class WcForReducer extends Reducer<Text, IntWritable, Text, IntWritable>{ @Override protected void reduce(Text key, Iterable<IntWritable> value, Context context) throws IOException, InterruptedException { int sum = 0; for (IntWritable i : value) { sum += i.get(); } context.write(key, new IntWritable(sum)); } }
文本输入:

统计输出:

2、单列排序
Job类:
package com.simope.mr.sort; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; /** * @deprecated 对数字进行排序 * @author JimLy * @see 20160127 * */ public class SortJob { public static void main(String[] args) { Configuration conf = new Configuration(); try { Job job = new Job(conf); job.setJobName("sortJob"); job.setJarByClass(SortJob.class); job.setMapperClass(SortMapper.class); job.setReducerClass(SortReducer.class); job.setMapOutputKeyClass(IntWritable.class); job.setMapOutputValueClass(IntWritable.class); FileInputFormat.addInputPath(job, new Path("/usr/input/sort")); FileOutputFormat.setOutputPath(job, new Path("/usr/output/sort")); System.exit(job.waitForCompletion(true) ? 0 : 1); } catch (Exception e) { System.out.println("错误信息:" + e); } } }
Mapper类:
package com.simope.mr.sort; import java.io.IOException; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; public class SortMapper extends Mapper<LongWritable, Text, IntWritable, IntWritable>{ @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString(); context.write(new IntWritable(Integer.parseInt(line)), new IntWritable(1)); } }
Reducer类:
package com.simope.mr.sort; import java.io.IOException; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.mapreduce.Reducer; public class SortReducer extends Reducer<IntWritable, IntWritable, IntWritable, IntWritable> { private static IntWritable lineNum = new IntWritable(1); @SuppressWarnings("unused") @Override protected void reduce(IntWritable key, Iterable<IntWritable> value, Context context) throws IOException, InterruptedException { //考虑到有相同的值 for (IntWritable val : value) { context.write(lineNum, key); lineNum = new IntWritable(lineNum.get() + 1); } } }
输入文本:
file1:  file2:
file2: file3:
file3: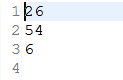
统计输出:

3、计算学科平均成绩
Job类:
package com.simope.mr.average; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; /** * @deprecated 计算学生的平均成绩 * @author JimLy * @see 20160127 * */ public class AveJob { public static void main(String[] args) { Configuration conf = new Configuration(); try { Job job = new Job(conf); job.setJobName("AveJob"); job.setJarByClass(AveJob.class); job.setMapperClass(AveMapper.class); job.setReducerClass(AveReducer.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); FileInputFormat.addInputPath(job, new Path("/usr/input/average")); FileOutputFormat.setOutputPath(job, new Path("/usr/output/average")); System.exit(job.waitForCompletion(true) ? 0 : 1); } catch (Exception e) { System.out.println("错误信息:" + e); } } }
Mapper类:
package com.simope.mr.average; import java.io.IOException; import java.io.UnsupportedEncodingException; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; public class AveMapper extends Mapper<LongWritable, Text, Text, IntWritable>{ String line; @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { line = changeTextToUTF8(value, "GBK").toString(); String[] stuArr = line.split(" "); context.write(new Text(stuArr[0]), new IntWritable(Integer.parseInt(stuArr[1]))); } public static Text changeTextToUTF8(Text text, String encoding) { String value = null; try { value = new String(text.getBytes(), 0, text.getLength(), encoding); } catch (UnsupportedEncodingException e) { e.printStackTrace(); } return new Text(value); } }
Reducer类:
package com.simope.mr.average; import java.io.IOException; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; public class AveReducer extends Reducer<Text, IntWritable, Text, IntWritable>{ int count, sum; @Override protected void reduce(Text key, Iterable<IntWritable> value, Context context) throws IOException, InterruptedException { sum = 0; count = 0; for (IntWritable i : value) { count++; sum += i.get(); } context.write(key, new IntWritable(sum/count)); } }
文本输入:
china: english:
english: math:
math:
统计输出:
 附:乱码问题由于hadoop中强制以UTF-8编码格式,而我用的是GBK,未进行转码。
附:乱码问题由于hadoop中强制以UTF-8编码格式,而我用的是GBK,未进行转码。
4、族谱:
Job类:
package com.simope.mr.grand; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; /** * @description 家族族谱 * @author JimLy * @see 20160128 * */ public class GrandJob { public static void main(String[] args) { Configuration conf = new Configuration(); try { Job job = new Job(conf); job.setJobName("GrandJob"); job.setJarByClass(GrandJob.class); job.setMapperClass(GrandMapper.class); job.setReducerClass(GrandReducer.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(Text.class); FileInputFormat.addInputPath(job, new Path("/usr/input/grand")); FileOutputFormat.setOutputPath(job, new Path("/usr/output/grand")); System.exit(job.waitForCompletion(true) ? 0 : 1); } catch (Exception e) { System.out.println("错误信息:" + e); } } }
Mapper类:
package com.simope.mr.grand; import java.io.IOException; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; public class GrandMapper extends Mapper<LongWritable, Text, Text, Text>{ @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString(); String[] faArr = line.split(" "); if (faArr.length == 2) { if (!faArr[0].equals("parent")) { context.write(new Text(faArr[0]), new Text(faArr[0] + "_" + faArr[1])); context.write(new Text(faArr[1]), new Text(faArr[0] + "_" + faArr[1])); } } } }
Reducer类:
package com.simope.mr.grand; import java.io.IOException; import java.util.ArrayList; import java.util.List; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; public class GrandReducer extends Reducer<Text, Text, Text, Text>{ private static int time = 0; @Override protected void reduce(Text key, Iterable<Text> value, Context context) throws IOException, InterruptedException { List<String> paList = new ArrayList<String>(); List<String> chList = new ArrayList<String>(); String info; String[] arr; for (Text i : value) { info = i.toString(); arr = info.split("_"); if (arr.length == 2) { paList.add(arr[0]); chList.add(arr[1]); } } if (time == 0) { context.write(new Text("grandParent"), new Text("grandChild")); time++; } for (int i = 0; i < paList.size(); i++) { for (int j = 0; j < chList.size(); j++) { if (paList.get(i).equals(chList.get(j))) { context.write(new Text(paList.get(j)), new Text(chList.get(i))); time++; } } } } }
输入文本:
file1: file2:
file2:
统计输出:
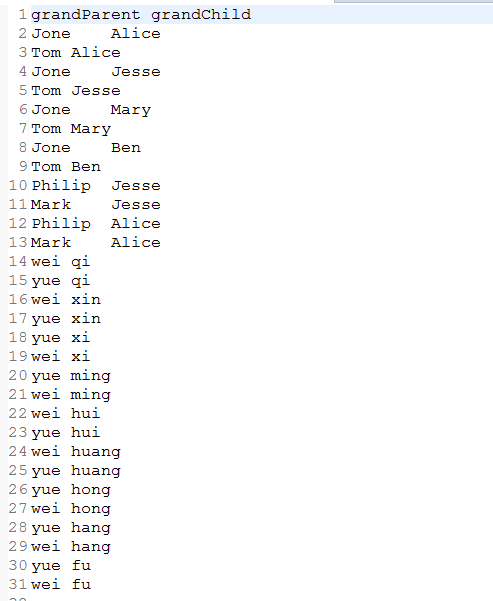 、
、
5、二次排序:
Job类:
package com.simope.mr.secOrder; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; /** * @deprecated 二次排序 * @author JimLy * @see 20160129 * */ public class SecOrderJob { public static void main(String[] args) { Configuration conf = new Configuration(); try { Job job = new Job(conf); job.setJobName("SecOrderJob"); job.setJarByClass(SecOrderJob.class); job.setMapperClass(SecOrderMapper.class); job.setReducerClass(SecOrderReducer.class); job.setMapOutputKeyClass(IntWritable.class); job.setMapOutputValueClass(IntWritable.class); FileInputFormat.addInputPath(job, new Path("/usr/input/secOrder")); FileOutputFormat.setOutputPath(job, new Path("/usr/output/secOrder")); System.exit(job.waitForCompletion(true) ? 0 : 1); } catch (Exception e) { System.out.println("错误信息:" + e); } } }
Mapper类:
package com.simope.mr.secOrder; import java.io.IOException; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; public class SecOrderMapper extends Mapper<LongWritable, Text, IntWritable, IntWritable>{ @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString(); String[] numArr = line.split(" "); if (numArr.length == 2) { context.write(new IntWritable(Integer.parseInt(numArr[0])), new IntWritable(Integer.parseInt(numArr[1]))); } } }
Reducer类:
package com.simope.mr.secOrder; import java.io.IOException; import java.util.ArrayList; import java.util.List; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; public class SecOrderReducer extends Reducer<IntWritable, IntWritable, IntWritable, Text>{ @Override protected void reduce(IntWritable key, Iterable<IntWritable> value, Context context) throws IOException, InterruptedException { String str = ""; for (IntWritable i : value) { str = str + "#" + i.get(); } str = str.substring(1, str.length()); String[] numArr = str.split("#"); String temp; for (int i = 0; i < numArr.length; i++) { for (int j = 0; j < numArr.length; j++) { if (Integer.parseInt(numArr[j]) > Integer.parseInt(numArr[i])) { temp = numArr[i]; numArr[i] = numArr[j]; numArr[j] = temp; } } } for (int i = 0; i < numArr.length; i++) { context.write(key, new Text(numArr[i])); } } }
输入文本:

统计输出:

6、计算1949-1955年中每年温度最高前10天
RunJob类:
package com.simope.mr; import java.io.IOException; import java.text.SimpleDateFormat; import java.util.Calendar; import java.util.Date; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class RunJob { public static SimpleDateFormat SDF = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"); static class HotMapper extends Mapper<LongWritable, Text, KeyPari, Text> { @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString(); String[] ss = line.split(" "); if (ss.length == 2) { try { Date date = SDF.parse(ss[0]); Calendar c = Calendar.getInstance(); c.setTime(date); int year = c.get(1); String hot = ss[1].substring(0, ss[1].indexOf("C")); KeyPari kp = new KeyPari(); kp.setYear(year); kp.setHot(Integer.parseInt(hot)); context.write(kp, value); } catch (Exception e) { e.printStackTrace(); } } } } static class HotReduce extends Reducer<KeyPari, Text, KeyPari, Text> { @Override protected void reduce(KeyPari kp, Iterable<Text> value, Context context) throws IOException, InterruptedException { for (Text v :value) { context.write(kp, v); } } } public static void main(String[] args) { Configuration conf = new Configuration(); try { Job job = new Job(conf); job.setJobName("hot"); job.setJarByClass(RunJob.class); job.setMapperClass(HotMapper.class); job.setReducerClass(HotReduce.class); job.setMapOutputKeyClass(KeyPari.class); job.setMapOutputValueClass(Text.class); job.setNumReduceTasks(2); job.setPartitionerClass(FirstPartition.class); job.setSortComparatorClass(SortHot.class); job.setGroupingComparatorClass(GroupHot.class); //mapreduce输入数据所在的目录或者文件 FileInputFormat.addInputPath(job, new Path("/usr/input/hot")); //mr执行之后的输出数据的目录 FileOutputFormat.setOutputPath(job, new Path("/usr/output/hot")); System.exit(job.waitForCompletion(true) ? 0 : 1); } catch (Exception e) { e.printStackTrace(); } } }
FirstPartition类:
package com.simope.mr; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Partitioner; /** * 实现分区 * */ public class FirstPartition extends Partitioner<KeyPari, Text> { /** * num:reduce数量 * getPartition()方法的 * 输入参数:键/值对<key,value>与reducer数量num * 输出参数:分配的Reducer编号,这里是result * */ public int getPartition(KeyPari key, Text value, int num) { return (key.getYear()) * 127 % num; //按照年份分区 } }
SortHot类:
package com.simope.mr; import org.apache.hadoop.io.WritableComparable; import org.apache.hadoop.io.WritableComparator; /** * 排序 * 因为hadoop对数据分组后默认是按照key升序排序的,所以需要自定义排序函数将分组数据降序排序 * 对于一般的键,只需要key值相同,则对应的value就会分配至同一个 reduce中; * 对于复合键,形式为TextPair<key1,key2>,通过控制 key1来进行分区,则具有相同的 key1的值会被划分至同一个分区中,但此时如果 key2不相同,则不同的key2会被划分至不同的分组 * */ public class SortHot extends WritableComparator { public SortHot() { super(KeyPari.class, true); } @SuppressWarnings("rawtypes") public int compare(WritableComparable a, WritableComparable b) { KeyPari o1 = (KeyPari)a; KeyPari o2 = (KeyPari)b; int res = Integer.compare(o1.getYear(), o2.getYear()); //升序排序 if (res != 0) { return res; } return -Integer.compare(o1.getHot(), o2.getHot()); //降序排序 } }
KeyPari类:
package com.simope.mr; import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; import org.apache.hadoop.io.WritableComparable; /** * 封装key对象 * */ public class KeyPari implements WritableComparable<KeyPari>{ private int year; private int hot; public int getYear() { return year; } public void setYear(int year) { this.year = year; } public int getHot() { return hot; } public void setHot(int hot) { this.hot = hot; } public void readFields(DataInput in) throws IOException { this.year = in.readInt(); this.hot = in.readInt(); } public void write(DataOutput out) throws IOException { out.writeInt(year); out.writeInt(hot); } public int compareTo(KeyPari keyPari) { int res = Integer.compare(year, keyPari.getYear()); if (res != 0) { return res; } return Integer.compare(hot, keyPari.getHot()); } public String toString() { return year + " " + hot; } public int hashCode() { return new Integer(year + hot).hashCode(); } }
GroupHot类:
package com.simope.mr; import org.apache.hadoop.io.WritableComparable; import org.apache.hadoop.io.WritableComparator; /** * 排序 * */ public class GroupHot extends WritableComparator { public GroupHot() { super(KeyPari.class, true); } @SuppressWarnings("rawtypes") public int compare(WritableComparable a, WritableComparable b) { KeyPari o1 = (KeyPari)a; KeyPari o2 = (KeyPari)b; return Integer.compare(o1.getYear(), o2.getYear()); //升序排序 } }
初次接触Hadoop,可能代码不是最简,存在可优化的地方还请大家指教。经过第一周无聊的环境部署,终于在这周可以写代码了。。。
如需转载的请注明出处:http://www.cnblogs.com/JimLy-BUG/