===========第2周 优化算法================
===2.1 Mini-batch 梯度下降===
epoch: 完整地遍历了一遍整个训练集
===2.2 理解Mini-batch 梯度下降===
Mini-batch=N,Batch GD。训练集小(<=2000),选Bath;
Mini-batch=1,Stochastic GD。不会收敛,而是一直在最小值附近“波动”。噪声可以通过减小学习率在一定程度上得到减缓,但每次只处理一个样本,失去了向量化带来的好处
考虑到计算机存储方式,通常选择mini-batch为2的指数,使得代码运行更快,最常见的是64,128,512。 In practice,mini-bacth的大小也是一个超参,做一个快速check,看哪一个可以最有效地降低代价函数值
注意使你的Bath大小与你的CPU/GPU内存相符
===2.3 指数加权平均===
Exponentially weighted averages: Vt = beta * Vt-1 + (1-beta) Zt, 比如 beta=0.9
可以review video中Andrew对beta取下面三个不同值时,温度曲线的不同
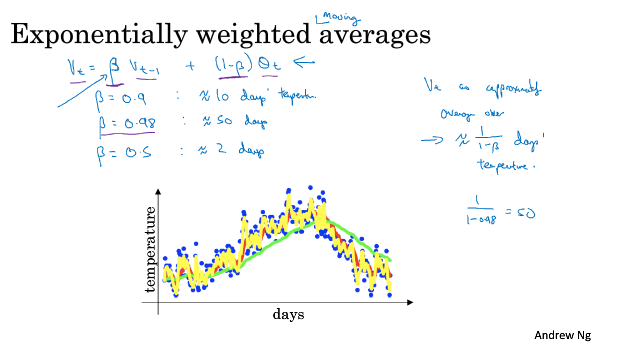
===2.4 理解指数加权平均===
【维基百科】https://en.wikipedia.org/wiki/Moving_average
===2.5 指数加权平均的偏差估计===
在机器学习中,在实现指数加权平均的时候,大家不在乎执行偏差修正,因为大部分人would rather just 熬过初始。但如果你关心初始时期的偏差,那么你在刚计算的时候就要使用偏差修正。

===2.6 动量梯度下降===
Momentum:对梯度做指数加权平均。Momentum总是好于简单的梯度下降。
我们总是希望在梯度较缓的地方走长一点,在梯度很陡的地方走慢一点。
通常取beta=0.9是一个很鲁棒的值,当然也可以调参。实践中人们通常不进行偏差修正,因为10次之后基本就不会有明显偏差了。
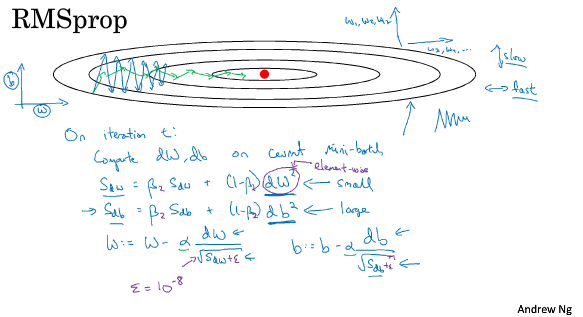
===2.7 RMSprop===
Root Mean Square prop
跟Mmomentum类似,RMSprop也可以消除梯度下降中的摆动,并允许你使用一个更大的学习率。
===2.8 Adam===
Adaptive Moment Estimation
通常学习率alpha需要调参,而默认beta_1=0.9, beta_2=0.99,

===2.9 学习率衰减===
learning rate decay, 有好几个可选的形式
比如随着epco衰减 1/(1+decay_rate*epoch_num),decay_rate是超参,其他的还有 指数衰减 decay_rate^epoch_num, k / sqrt(epoch_num) ,离散下降等等
when training only a small number of models,有些人也会手动调整学习率
For me, I would say that learning rate decay usually lower down on the list of things I try,Setting alpha, just a fixed value of alpha, and getting that to be well tuned, has a huge impact. Learning rate decay does help. Sometimes it can really help speed up training, but it is a little bit lower down my list in terms of the things I would try.(但这并不会是我率先尝试的内容)
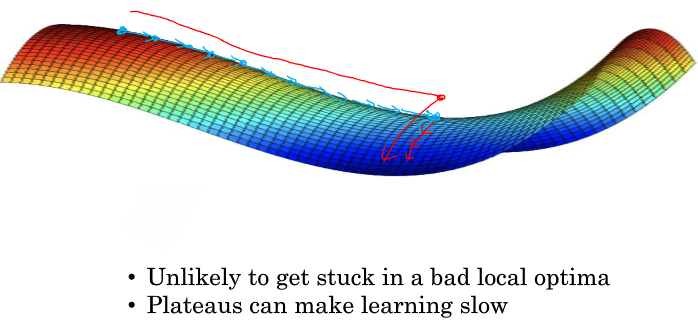
===2.10 局部最优的问题===
想象一幅我们关于有多个局部最优值的三维直觉图,第三维是代价函数值,事实证明,当维数低的时候(权重是2维),很容易出现这样的图。
但这样的直觉对高维来说并不是正确的,我们发现most梯度为零的点通常是“鞍点”,而不是我们所想象的局部极小值。可以很容易理解,比如一个有20,000权重的模型,画出代价函数关于权重的图,局部极小值意味着,关于20,000每个权重的方向,该点都是碗状的,这样的点其实非常少。
在深度学习的历史中,我们学到的一课时我们对低维空间的大部分直觉并不能应用到高维空间中。
Problem of plateaus. It turns out that 平稳段 can really slow down the learning。And and a plateau is a region where the derivative is close to zero for a long time.
Momentum,RMSprop,Adam这些优化算法对处理Plateanus有一定的好处