集成学习,又称为“多分类器系统”(multi-classifier system)、“基于委员会的学习”(committee-based learning)等。基本的想法是结合多个学习器,获得比单一学习器泛化性能更好的学习器。
根据个体学习器的生成方式,目前集成学习大致可分为两大类:
- 序列化方法:个体学习器间存在强依赖关系、必须串行生成,代表是Boosting;
- 并行化方法:个体学习器间不存在强依赖关系、可同时生成,代表是Bagging和“随机森林”(Random Forest)。
一、利用Hoeffding不等式估算集成学习的错误率上界
考虑二分类问题y∈{-1, +1},真实函数f,并假定基分类器错误率为ε。假设集成通过简单投票结合T个基分类器,i.e.若超过半数的基分类器正确,则集成分类器正确:
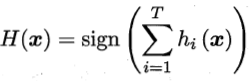
接下来估算集成的错误率 。首先,有下式
。首先,有下式
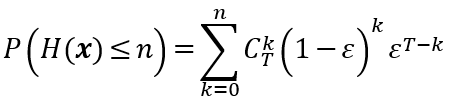
设基分类器正确率为p,由Hoeffding不等式,当n=(p -  )T时,成立下述不等式
)T时,成立下述不等式
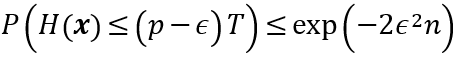
由n = T/2, p = 1-ε 得=1/2 - ε, 于是

上式估算出了集成学习错误率的上界,且从中可以看出,随着集成中个体分类器数目T的增大,集成的错误率将指数级下降,最终趋于零。
值得注意的是,以上分析基于的假设是基学习器相互独立。然而,在现实问题中,个体学习器为解决同一问题而训练,并不相互独立。因此上述分析只是理论层面,实际问题的解决,还需要深入了解前文提到的序列化与并行化方法。
二、Boosting族算法
Boosting是一族可将弱学习器提升为强学习器的算法,工作机制类似:先由初始训练集训练出基学习器,再根据其表现调整样本分布,赋予未被准确分类的样本更高的权重,然后根据调整后的样本分布再训练接下来的基分类器;重复进行,直至全部T个基学习器训练完成,再对T个基学习器加权结合。
Boosting族算法中以AdaBoost(Adapative Boosting)最为著名。设yi∈{-1, +1}, f是真实函数,AdaBoost的描述如下:
输入:训练集D = {(x1, y1), (x2, y2), ..., (xm, ym)}; 基学习算法
; 训练轮数T.
过程:
1: D1 = 1/m. //初始化训练数据的权值分布,每个训练样本被赋予相同的权重
2: for t = 1 to T do
3: ht =
4: εt = Px~Dt(ht(x) ≠ f(x));
5: if εt > 0.5 then break //检查基学习器是否比随机猜测好;不满足则学习器被抛弃,学习终止。重采样(re-sampling)后重新训练。
6: αt = (1/2) * ln((1 - εt) / εt); //确定分类器ht的权重,被误分的样本的权值会增大,被正确分类的权值减小,推导过程见p.175
7: Dt+1(x) =

= (Dt(x) * exp(-αt * f(x) * ht(x))) / Zt; //”重赋权法“(re-weighting)更新样本分布,其中Zt是规范化因子,推倒见p.176
8: end for
输出: H(x) = sign(∑Tt=1αtht(x)) //输出最终的强分类器
在该算法过程中,用的是“加性模型”(additive model)推导,即根据基学习器的线性组合来最小化指数损失函数(exponential loss function)

sign(H(x))可以达到贝叶斯最优错误率。这是因为,由损失函数对H(x)的偏导
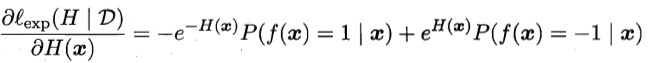
为零可以解得
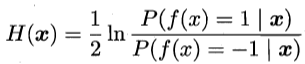
于是
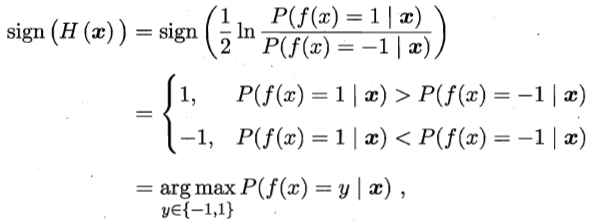
即,若H(x)可以让损失函数最小化,则分类错误率也将最小化。
三、Bagging与随机森林
Bagging(Bootstrap AGGregatING)是并行集成学习最著名的代表。它直接基于自主采样法(bootstrap sampling): 采样出T个含m个训练样本的采样集,然后基于每个采样集训练出一个基学习器,再将这些基学习器结合。对预测输出进行结合时,对分类任务采取简单投票法,对回归任务使用简单平均法。
Bagging的算法描述如下:
输入:训练集D = {(x1, y1), (x2, y2), ..., (xm, ym)}; 基学习算法
过程:
1. for t = 1 to T do
2. ht =
3. end for
输出:H(x) =
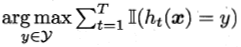
算法的复杂度为T(O(m) + O(s)),其中O(m)为基学习器的计算复杂度,O(s)为采样与投票/平均过程的计算复杂度。由于O(s)与T很小,因此算法复杂度可看作O(m)。可见Bagging是比较高效的。此外,与AdaBoost只适用于二分类任务不同,Bagging可以直接用于多分类、回归等任务。
此外,由于每个基学习器只用了初始训练集中约63.2%的样本,剩下的样本可用作验证集来对泛化能力进行“包外估计”(out-of-bag estimate)。
Bagging关注降低方差,在不剪枝决策树、神经网络等易受样本扰动的学习器上效果更佳明显。
随机森林(Random Forest, RF)在以决策树为基学习器构建Bagging集成的基础上,进一步在决策树的训练过程中引入随机属性选择。
四、结合策略
学习器结合可能的优点:
- 提升泛化性能
- 降低陷入局部极小的风险
- 假设空间有所扩大,有可能学得更好的近似
接下来总结几种常见的结合策略。
4.1 平均法
对数值型输出,常用平均法(averaging):
- 简单平均法(simple averaging)
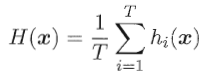
- 加权平均法(weighted averaging)
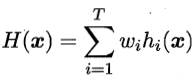
其中,加权平均法的权重一般从训练数据中学习得到。但由于噪声干扰和过拟合问题,加权平均法也未必优于简单平均法。一般而言,个体学习器性能相差较大时,宜用加权平均法,否则宜用简单平均法。
4.2 投票法
对分类任务,最常见的是用投票法(voting)。将hi在样本x上的预测输出表示为一个N维向量(h1i(x), h2i(x), ..., hNi(x)),其中hji(x)是hi在类别标记cj上的输出。则投票法包括:
- 绝对多数投票法(majority voting)

- 相对多数投票法(plurality voting)
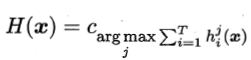
- 加权投票法(weighted voting)

在不允许绝对预测的任务中,绝对多数、相对多数投票法被统称为“多数投票法”。
现实任务中,不同类型学习器可能产生不同的hji(x)值,常见的包括类标记和类概率。
值得注意的是,不同类型的预测值hji(x)不能混用。对一些能在预测出类别标记的同时产生分类置信度的学习器,其分类置信度可转化为类概率使用。若此类值为进行规范化,如支持向量机的分类间隔值,则需要采用Platt缩放(Platt scaling)、等分回归(isotonic regression)等技术对结果进行“校准”(calibration)后才能作为类概率使用。
4.3 学习法
训练数据很多时,可采用学习法:通过另一个学习器进行结合。Sacking是学习法的典型代表。这里将个体学习器称为初级学习器,用于结合的学习器称为次级学习器,或元学习器(meta-learner)。
Stacking算法描述如下:
输入:训练集D = {(x1, y1), (x2, y2), ..., (xm, ym)}; 初级学习算法
; 次学习算法
过程:
1: for t = 1 to T do
2: ht =
; //使用初级学习算法
产生初级学习器ht
3: end for
4: D' = Ø; //生成次级训练集
5: for i = 1 to m do
6: for t = 1 to T do
7: zit = ht(xi);
8: end for
9: D' = D' ∪ ((zi1, zi2, ..., ziT), yi);
10: end for
11: h' =
; //在D'上用次级学习算法
产生次级学习器h'
输出:H(x) = h'(h1(x), h2(x), ..., hT(x))
次级学习器的输入属性和算法对集成的泛化能力有很大影响。具体见书pp.184-185。