1.需要安装Image 模块,安装时会自动帮我们安装:Installing collected packages: pytz, django, pillow, Image 关联的包
pip install Image
2.安装pytesseract
pip install pytesseract
3.安装tesseract-ocr识别引擎
Tesseract的OCR引擎最先由HP实验室于1985年开始研发,至1995年时已经成为OCR业内最准确的三款识别引擎之一。
下载地址:https://jaist.dl.sourceforge.net/project/tesseract-ocr-alt/tesseract-ocr-setup-3.02.02.exe
安装好后,需要在D:ToolsPython27Libsite-packagespytesseractpytesseract.py下将
tesseract_cmd = 'tesseract'
改为:
tesseract_cmd="D:\Tools\Tesseract-OCR\tesseract.exe"也就是Tesseract-OCR的安装路径,
或将该路径添加到环境变量中.要不然调用的时候,会报如下错误:

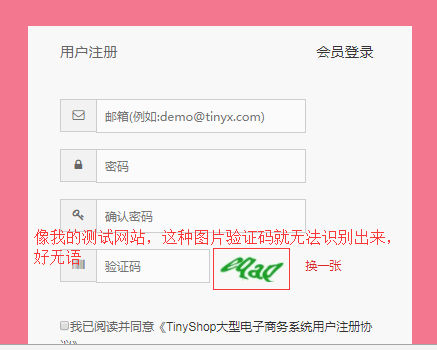
自己试了几次,这个pytesseract的识别率太低了。经常识别不出图片验证码的内容
第一种方法:
#-*-encoding:utf-8-*-
from selenium import webdriver
from PIL import Image,ImageGrab
from time import sleep
import pytesseract
driver=webdriver.Chrome()
driver.get("http://localhost:8081/tshop/index.php?con=simple&act=login")
def click_register_link():
driver.find_element_by_link_text(u"立即注册").click()
sleep(0.5)
verifyCode=driver.find_element_by_xpath('//*[@id="captcha_img"]').rect #获取二维码在页面的位置
start_x=int(verifyCode["x"])
start_y=int(verifyCode["y"])
end_x=verifyCode["width"]+start_x #开始坐标+结束坐标点
end_y=verifyCode["height"]+start_y #开始坐标+结束坐标点
cut_img=(start_x,start_y,end_x,end_y)
#截取注册页面图片,并保存到test目录下page.png
driver.get_screenshot_as_file("F:\testAndStudy\test\page.png")
#打开test目录下,注册页面的图片
im = Image.open("F:\testAndStudy\test\page.png")
#根据上面获取到的图片验证码在页面的坐标,将图片验证码剪切出来,保存为verifyCode.png
region = im.crop(cut_img)
region.save("F:\testAndStudy\test\verityCode.png")
#打开截取后的图片验证码
verityCode = Image.open("F:\testAndStudy\test\verityCode.png")
sleep(1)
#调用Pytesseract的image_to_string()方法识别二维码图片,并复制到code中
code = pytesseract.image_to_string(verityCode)
print code
if __name__=="__main__":
click_register_link()
第二种方法:
使用pytesser 模块也是可以对图片的内容进行识别,不过这个识别率会稍微好点,但是,识别的结果还是一样没有达到预期的结果。
下载地址:https://code.google.com/p/pytesser/downloads/detail?name=pytesser_v0.0.1.zip
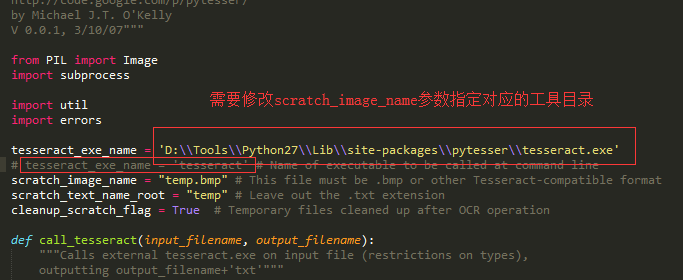
安装:下载好后,直接解压到Python27Libsite-packages下即可,不过由于这个模块本身没有带__init__.py文件,所以,在导入时
会报找不到pytesser模块错误,需要在pytesser下自己建一个__init__.py文件。另外也是要修改pytesser的tesseract_exe_name参数,具体如下
#-*-encoding:utf-8-*-
from pytesser import *
from selenium import webdriver
from PIL import Image,ImageGrab,ImageEnhance
from time import sleep
driver=webdriver.Chrome()
driver.get("http://localhost:8081/tshop/index.php?con=simple&act=login")
def click_register_link():
driver.find_element_by_link_text(u"立即注册").click()
sleep(0.5)
verifyCode=driver.find_element_by_xpath('//*[@id="captcha_img"]').rect #获取二维码在页面的位置
start_x=int(verifyCode["x"])
start_y=int(verifyCode["y"])
end_x=verifyCode["width"]+start_x #开始坐标+结束坐标点
end_y=verifyCode["height"]+start_y #开始坐标+结束坐标点
cut_img=(start_x,start_y,end_x,end_y)
#截取注册页面图片,并保存到test目录下page.png
driver.get_screenshot_as_file("F:\testAndStudy\test\page.png")
#打开test目录下,注册页面的图片
im = Image.open("F:\testAndStudy\test\page.png")
#根据上面获取到的图片验证码在页面的坐标,将图片验证码剪切出来,保存为verifyCode.png
region = im.crop(cut_img)
region.save("F:\testAndStudy\test\verityCode.png")
def print_verityCode():
#图片验证码处理及打印内容
sleep(1)
verityCode = Image.open("F:\testAndStudy\test\verityCode.png")
#图片处理
im=Image.open("F:\testAndStudy\test\verityCode.png")
imgry=im.convert("L")
# imgry.show()
threshold = 130
table=[]
for i in range(256):
if i < threshold:
table.append(0)
else:
table.append(1)
# print table
out = imgry.point(table,"1")
out.show()
#打印验证码内容
code1 = pytesser.image_file_to_string("F:\testAndStudy\test\verityCode.png")
code = pytesser.image_to_string(out)
print code1
print code
if __name__=="__main__":
click_register_link()
print_verityCode()
总结:这两种方法,都是识别图片内容,但是,拿来做图片验证码的识别率相对而言,效果不是很好,因为现在的图片验证码的内容不是大多字符是重叠或者相连的。
导致内容无法识别或者出现识别错误的情况,而且这种识别错误概率非常高(自己跑了好多次,偶尔只有一两次能识别正确的)。
后面在网上找了一些方法,据说可以提高识别的成功率,但目前没有试过也不敢说,有感兴趣的朋友可以去试试,地址:https://www.cnblogs.com/cnlian/p/5765871.html