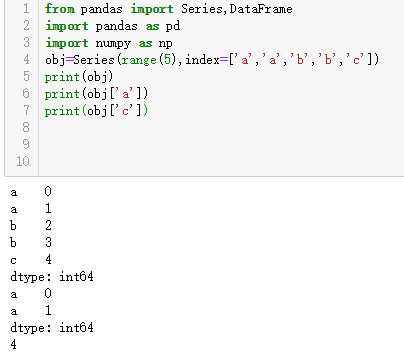
pandas入门—基本功能
138页
排序和排名
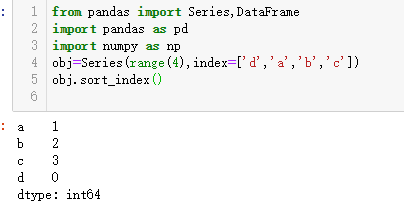
根据条件对数据集排序也是一种重要的内置运算。要对行或列索引进行排序(按字典顺序)(a,b,c,d),可使用sort_index()方法,它将返回一个已排序的新对象:
而对于DataFrame,则可以根据任意一个轴上的索引进行排序:
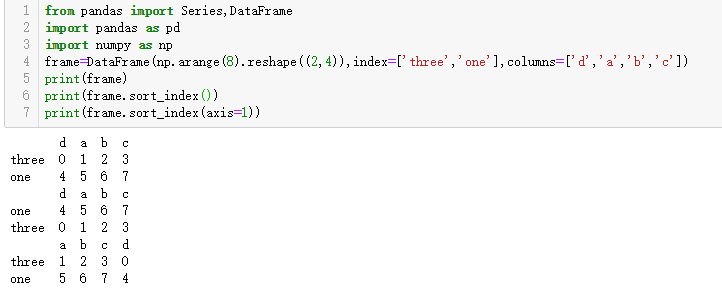
数据默认是按升序排序的,但也可以降序排序:

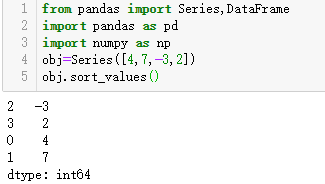
若要按值对Series进行排序,可使用其sort_values方法(大概就是Seris对象没有order属性的意思,然后我百度是没有了一下,说是Python3.6之后的版本已经没有order属性了,尝试使用sort_values()方法就好了。)
在排序时,任何缺失值默认都会被放到Series的末尾:
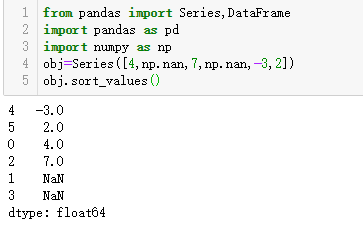
在DataFrame上,你可能希望根据一个或多个列中的值进行排序。将一个或多个列的名字传递给by选项即可达到该目的
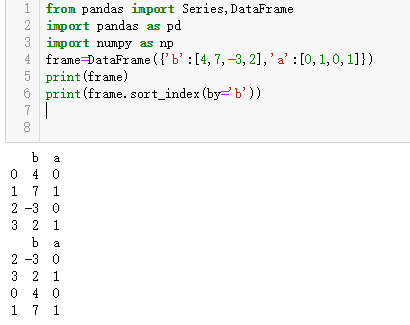
排名(ranking)跟排序关系密切,且它会增设一个排名值(从1开始,一直到数组中有效数据的数量)。
接下来介绍Series和DataFrame的rank方法。默认情况下,rank是通过“为各组分配一个平均排名”的方式破坏平级关系的

按降序进行排名:
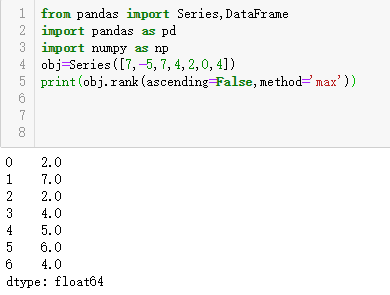
DataFrame可以在行或列上计算排名:
表5—8 排名时用于破坏平级关系的metho选项:
‘average’:默认:在相等分组中,为各个值分配平均排名
‘min’:使用整个分组的最小排名
‘max’:使用整个分组的最大排名
‘first’:按值在原始数据中的出现顺序分配排名
带有重复值的轴索引
虽然许多pandas函数(如reindex)都要求标签唯一,但这并不是强制性的。我们来看看下面这个简单的带有重复索引值的Series:
索引的is_unique属性可以告诉你它的值是否是唯一的
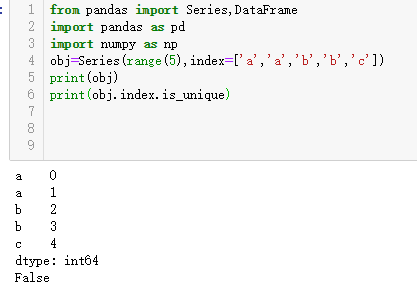
对于带有重复值的索引,数据选取的行为将会有些不同。如果索引对应多个值,则返回一个Series,而对应单个值的,则返回一个标量
对DataFrame的行进行索引时也是如此