小白的经典CNN复现系列(一):LeNet-1989
之前的浙大AI作业的那个系列,因为后面的NLP的东西我最近大概是不会接触到,所以我们先换一个系列开始更新博客,就是现在这个经典的CNN复现啦(。・ω・。)
在开始正式内容之前,还是有些小事情提一下,免得到时候评论区的dalao们对我进行严格的批评教育······
-
首先呢,我会尽可能地按照论文里面的模型参数进行复现,论文里面说的什么我就写什么。但是由于我本人还是个小白,对于有些算法(比如什么拟牛顿法什么的)实在是有点苦手,而且CNN也基本上就只使用一阶的优化方法,所以有些我感觉没有必要复现的东西我就直接用一些其他的办法替代啦,别介意哈
-
然后呢,因为我这边硬件设备有限,就只有一张1080Ti的卡,所以如果模型比较复杂并且数据集太大的话,我可能就只是把模型的结构复现一下,具体的训练就爱莫能助了呢,毕竟,穷是原罪┓( ´∀` )┏
-
另外,由于大部分论文实际上并没有将所有的处理手段全都写在论文里面,所以有的时候复现出来的结果和实际的论文里面说的结果可能会有一些差距,但是这个真的没有办法,除非去找作者把源代码搞过来,而且毕竟权重的初始化是随机的,也就是说即便拿到源代码,也不一定能跑出论文里面的最好结果,所以,大家就看看思路就好了呗
-
最后呢,因为我知识储备还不是很够,所以有些描述可能会不太正式,甚至有些小错误,所以如果出现这种情况,麻烦各位dalao在评论区温柔地指点一下,反正要是你喷我,我不理你就是了┓( ´∀` )┏
好啦好啦,开始正题吧。一般来说,大家认为的非常经典的打头的神经网络是由LeCun提出来的LeNet-5,而且这个网络在当时的MNIST数据集上的表现也不错。但是实际上这个网络也有他的初始版本,就是这篇博客要讲的LeNet-1989了,虽然实际这个网络并不叫LeNet,这个结构命名是我在看CSDN上的一篇博客的时候那个博主这么写的。在我看来为什么那个博主称这个网络叫LeNet-1989呢?实际上仔细看下这个网络的结构的话,大致的结构和后来的LeNet-5的结构已经十分相似了,只是深度、池化、输出形式、训练方法等小细节不太一样,为了能更好地了解后面的LeNet-5,我选择了这个网络作为一个入门参考(虽然复现的时候才发现全是坑(T▽T))。
具体的论文题目是《Backpropagation Applied to Handwritten Zip Code Recognition》,在网上应该是还能找得到这篇文章的,虽然这篇文章已经很老了(1989年比我老多了,emmmm我应该没有暴露年龄,大概)
这篇文章实际上算是LeCun相当早的关于卷积神经网络形式的论文了,而且在这篇文章中,权重初始化、权重共享理念都有涉及,虽然并没有在理论上给出严格的推导和证明,但是我们可以看出来的是,在这个阶段LeCun对于卷积神经网络的具体结构已经有了一个比较完善的概念了,而且这篇文章中指出的初始化方法、激活函数形式以及卷积核的尺寸等等也和之后的LeNet-5是基本一致的。
数据集部分:
在这篇文章中使用的实际数据集是当时美国的手写邮政编码,但是这个原始的数据集我是找不到了,所以我就使用了基于这个数据集进行调整以及再整理后得到的数据集MNIST了,这个数据集也是后来LeNet-5用的嘛,就当是和论文一样好咯┓( ´∀` )┏
实际上pytorch中是提供了MNIST数据集的下载以及加载,所以这个还是蛮方便的,但是还有一个问题,那就是论文里面提到,实际训练网络使用的图片是16 x 16,并且将灰度值的范围通过变换转换到了[-1, 1]的范围内,而Pytorch提供的MNIST数据集里面是尺寸为28 x 28,像素值为[0, 255]的图片,因此在实际进行网络训练之前,我们要对数据集中的数据进行简单的处理,这部分到后面的代码部分在说吧。
网络结构部分:
这篇文章使用的网络的基本结构和之后的LeNet-5除了深度以及一些小细节之外基本上是一模一样了,具体的结构直接看图啦: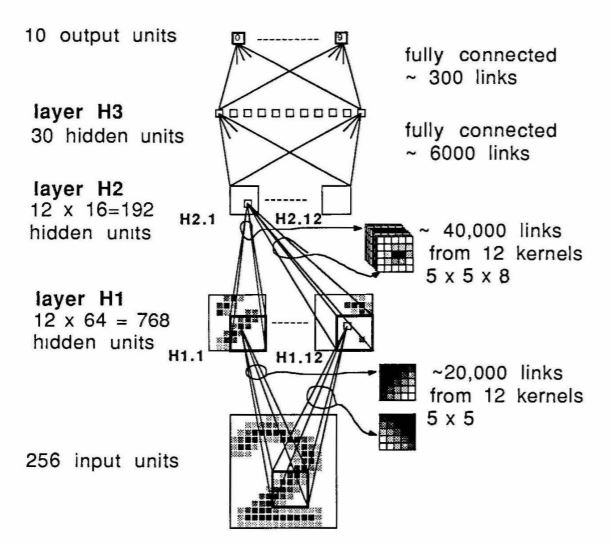
下面我们对这个网络结构进行一个简单地分析:
整个网络由H1、H2、H3以及output层构成,每一层的具体结构以及功能我下面会说啦:
-
H1层:由5 x 5的卷积核以及对应的偏置进行特征图的计算,输入的图片的尺寸如果写成Pytorch的默认的输入数据格式的话(在这里先不考虑batch_size这个维度),应该是[channels, height, width] = [1, 16, 16],卷积核会将这个输入数据输出成[12, 8, 8]的形式。但是这里就有问题了,因为原论文中并没有给出卷积运算时使用的stride以及padding,而根据这个数据并且考虑计算机进行整数运算时候的取整操作,这个是有无穷多的解的······,所以我在复现这里的时候,就选了最简单的参数,stride = (2,2),padding = (2,2),考虑到取整操作,这样是可以得到论文中所说的特征图的尺寸的。
-
H2层:同样的,这里是由5 x 5的卷积核以及对应的偏置进行特征图的计算,输入的图片的尺寸是之前的H1层的[12, 8, 8],卷积核会将这个输入数据输出成[12, 4, 4]的尺寸。然后这里就出现了和上面一层同样的问题,他没给说明使用的stride和padding是多少,而且有无穷多组解······真的看到这里我已经打算放弃复现这个论文了,但是,没办法毕竟都看到这里了,自己作的死,跪着也要作完TAT。这里选取的参数也是stride = (2,2),padding = (2,2),大家可以计算一下,这个和给出的那个尺寸是一致的。并且这里和LeNet-5一样,用到了一个比较特别的计算方式,当我们计算特征图的时候,并没有直接拿所有的H1层的输出作为输入,而是每一次都从那12个特征图中调出8个来进行计算,但是,理由并没有说,而且很可气的就是里面有一句话
···according a scheme that will not be described here.
"我知道,但我就是不说,气不气"
我感觉我撕了论文的心都有了······,所以这里我们不理他,就直接用正常的卷积来做,反正相关的东西在后面的LeNet-5里面也有说到底怎么选,这里就先这样。
- H3层:到这一层卷积结束,进入到全连接层的范围。由于我们的输入特征图的尺寸是[12, 4, 4],将这个图片转换成向量以后的维度是12 x 4 x 4 = 192,并且要求输出的尺寸是30,因此这里的线性层的尺寸是192 x 30
- output层:在这一层要进行分类输出啦,所以我们的线性层理所当然的是30 x 10
网络结构就是这些啦,是不是很简单?而且和之后的LeNet-5也是很像呢。其实这篇文章我是觉得,如果他能把里面的一些东西说得更加清楚的话,其实蛮适合初学者进行复现的,然而就是因为一大堆东西没有说清楚,结果整出了一个月球表面来,到处都是坑。
训练相关参数部分:
在关于模型的训练上,主要有以下几件事需要注意:
-
使用的基本思路是随机梯度下降(SGD),注意这里的SGD不是那种有mini-batch的,而是就真的每次就使用一个样本进行参数的更新,这也是为什么之前我在说图片尺寸的时候让大家先不要考虑batch_size的问题,因为这个是1。
-
关于更新方法的问题,在这篇论文里面使用的是二阶精度的方法,具体的更新算法在LeCun的《Improving the Convergence of Back-Propagation Learning with Second-Order Methods》中有介绍,实际上就是对BFGS算法进行了一些改进,大家有兴趣可以看一下这篇文章。但是,实际上在后来的LeNet-5的这篇文章中,LeCun指出,在这种较大数据量的训练上面,用二阶方法的人都是吃饱了没事干的铁憨憨(我骂我自己.jpg),所以在这篇复现里面,我们就采用一阶方法的SGD。
-
使用的损失函数为MSELoss,但是这部分我没看懂他说的输出部分用place coding是个啥······所以这个部分我就假设他用的是one-hot编码啦,如果评论区有大佬能够指点一下这个place coding到底是啥的话,我到时候再抽时间把这个部分重新搞一下。
-
训练代数为23,因为原文使用的参数更新方法是二阶方法所以不用人为设置学习率(这一部分在2017年的CS231n中是有说明的,建议大家直接去看一下网课),但是我们这里用的是一阶的方法,所以需要设置学习率,并且训练代数也要相对地增加一些,因为一阶方法的收敛毕竟还是相对较慢。
各部分代码简析
我们先把需要用到的模块啥的全都搞到一起吧
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets
from torchvision import transforms as T
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
首先是关于数据的处理部分。相关的内容在我的浙大AI作业系列的口罩识别部分有详细说明,在这里就不具体解释原理了,直接贴代码
picProcessor = T.Compose([
T.Resize((16, 16)), #图片尺寸的重整
T.ToTensor(), #将图片转化为像素值为[0, 1]的tensor
T.Normalize(
mean = [0.5],
std = [0.5]
), #将图片的数据范围从[0, 1]转换为[-1, 1]
])
有了这个图片的转换器之后,我们要加载一下我们的数据集,并且用这个转换器进行图片的处理。由于Pytorch提供了自己的MNIST数据的加载方式,因此我们在这里直接就用Pytorch提供的方法就好了。
dataPath = "F:\Code_Set\Python\PaperExp\DataSetForPaper\" #在使用的时候请改成自己实际的MNIST数据集路径
mnistTrain = datasets.MNIST(dataPath, train = True, download = False, transform = picProcessor) #如果是第一次加载,请将download设置为True
mnistTest = datasets.MNIST(dataPath, train = False, download = False, transform = picProcessor)
详细的关于datasets.MNIST的使用方法,建议大家查一下官方文档以及自行百度,这里就不多做解释了。
在介绍下一步分的代码之前,我们必须要先来看看我们之后要用的被加载进来的数据长什么鬼样子,那我们就来拿出一个数据来看一下数据长啥样好了。
img, label = mnistTrain[0]
print(type(img)) #tensor
print(img) #图片对应的像素值矩阵
print(type(label)) #int
print(label) #5,图片的标签
也就是说,数据集里面图片给的是一个tensor,但是标签给的是int,所以之后我们要自己把读出来的标签转化成我们想要one-hot向量。
由于我们训练集有60000张图片,所以如果用cpu进行训练的话可能要花很长的时间,能用GPU的话还是用GPU进行训练吧,这里给出一个通用代码,有没有GPU都可以的。
device = torch.device('cuda:0') if torch.cuda.is_available() else torch.device('cpu') #如果电脑有N卡的GPU,就可以把模型放GPU上,否则就放CPU上
接下来终于到我们的重点啦啊啊啊啊啊!现在呢我们要开始构建我们的神经网络了。为了让小伙伴们都能看懂,所以这部分我们就老老实实地一步一步构造,也不写什么用Sequential全都包起来的骚操作,就一层一层地来:
H1:in_channel = 1, out_channel = 12, kernel_size = (5, 5), stride = (2, 2), padding = 2
激活函数:1.7159Tanh(2/3 * x)
self.conv1 = nn.Conv2d(1, 12, 5, stride = 2, padding = 2)
self.act1 = nn.Tanh() #这一部分先用着Tanh(),等到后面写forward函数的时候再把系数乘上去
H2:in_channel = 12, out_channel = 12, kernel_size = (5, 5), stride = (2, 2), padding = 2
激活函数:同上
self.conv2 = nn.Conv2d(12, 12, 5, stride = 2, padding = 2)
self.act2 = nn.Tanh()
H3:全连接层: 192 * 30
激活函数:同上
self.fc1 = nn.Linear(192, 30)
self.act3 = nn.Tanh()
output:全连接层:30 * 10
激活函数:同上
self.fc2 = nn.Linear(192, 30)
self.act4 = nn.Tanh()
我们需要把刚刚的这一堆全都放在自定义的LeNet1989类的构造函数里面,到时候所有的代码我会全部在最下面整理一下的,所以先别急吖。
在构造完基本构造以后,别忘了论文里面还说了,我们要对权重做一个基本的初始化,所以我们还要敲下面的代码:
for m in self.modules():
if isinstance(m, nn.Conv2d):
F_in = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data = torch.rand(m.weight.data.size()) * 4.8 / F_in - 2.4 / F_in
if isinstance(m, nn.Linear):
F_in = m.out_features
m.weight.data = torch.rand(m.weight.data.size()) * 4.8 / F_in - 2.4 / F_in
关于这段代码,有一些需要注意的事情:
-
首先,当我们自定义的网络结构中有很多的基本结构的时候(比如说这个例子我们有两个卷积还有两个全连接),为了能够访问全部的基本结构,我们可以用Module的成员函数modules(),会返回一个包括自身内部所有基本结构的可迭代结构
-
在我们基本的结构,比如卷积层中,通过查看源码我们可以知道,里面是有weight成员和bias成员分别表示权重和偏置的
-
对于我们的所有的神经网络的基本模型(卷积层以及线性层),参数本来应该会直接存在tensor里面,但是为了在模型中进行一些中间结果的暂存(比如RNN的隐藏层输出),所有的参数会被打包放进一个叫做Parameter的类里面,Paramter里面有data成员用来存储tensor的数据,而还有一个成员requires_grad用来确定是否该参数可以求梯度,不过因为没用到所以先不提,感兴趣的小伙伴可以去看一下官方网站上的关于torch.nn.Module以及torch.nn.parameter.Parameter的源码。(说这么多主要是为了解释 m.weight.data的含义)
-
tensor在进行rand()初始化的时候,生成的随机数满足以[0, 1)为区间的均匀分布,想要转换成我们想要的分布的话就要自己做一些简单的变换。具体来说,假设我们要转换为[a, b),就需要进行下面的转换:x * (b-a) + a,这样的话就从[0, 1)转换为[a, b)了
上面的一大坨的代码就是我们定义的神经网络的构造以及初始化部分了。对于我们自行构造的神经网络结构来说,下面一个很重要的函数就是forward函数了,没有这个函数我们的网络就没得跑。但是由于我们前面结构已经定义好了,并且里面根本没有什么复杂的东西,所以这个模型的forward函数其实蛮好写的。(关于为什么一定要有forward函数,我在关于浙大AI的口罩识别作业里有简单的说明,或者大家可以读一下我之前推荐的《Deep Learning with Pytorch》)
def forward(self, x):
x = self.conv1(x)
x = 1.7159 * self.act1(2.0 * x / 3.0) #这里就是我们之前说的,实际论文用的激活函数并不是简单的Tanh
x = self.conv2(x)
x = 1.7159 * self.act2(2.0 * x / 3.0)
x = x.view(-1, 192) #这一步是由于我们实际上在上面的一层中输出的x的维度为[12, 4, 4]
#我们必须把它变成[1, 192]的形式才能输入到全连接层。
#详细的原因我在之前的浙大AI口罩作业的博客里有提到的
x = self.fc1(x)
x = 1.7159 * self.act3(2.0 * x / 3.0)
x = self.fc2(x)
out = 1.7159 * self.act4(2.0 * x / 3.0)
return out
现在数据、模型结构都已经搞定了,接下来我们要做的就是训练我们的模型啦,大家鼓掌庆祝下呗(๑¯∀¯๑)
实际上训练函数部分没有什么难点,大致的内容我在浙大AI口罩作业里面基本都说得比较详细了,所以基本没什么难点呢。总之我们来一点点看一下我们的代码吧。
lossList = []
testError = []
这一部分主要是设置全局变量,来保存我们在训练过程中得到的损失函数值以及在测试集上的错误率,其实看一眼变量名就能猜出来是干啥的了嘛
接下来使我们的训练函数:
def train(epochs, model, optimizer, scheduler:bool, loss_fn, trainSet, testSet):
···
epochs:训练的代数
model:我们定义的模型对象
optimizer:定义的优化器对象
scheduler:这就是和之前内容不太一样的东西啦,确定是否进行学习率的变化
loss_fn:lossfunction,损失函数
trainSet:训练集
testSet:测试集
在训练函数部分,我们需要做的就是一下几点:
- 训练:
- 将数据从训练集里面取出来
- 将标签转换为one-hot格式
- 将数据放到之前指定的device中,GPU优先,没有就放CPU
- 计算输出、损失并进行梯度下降
- 测试:
- 暂时取消梯度更新
- 在测试集上数据处理、设备指定
- 输出,和标签进行比较
- 学习率的改变:这一部分主要是为了之后的LeNet-5的复现做准备,因为在LeNet-5中,使用的学习率是和当前的训练轮数相关的,具体的代码内容我会放在这里,但是我不会解释,等到后面的LeNet-5再进行详细地说明
好了我们来吧代码放上来吧:
trainNum = len(trainSet)
testNum = len(testSet)
for epoch in range(epochs):
lossSum = 0.0
#训练部分
for idx, (img, label) in enumerate(trainSet):
x = img.unsqueeze(0).to(device)
#将标签转化为one-hot向量
y = torch.zeros(1, 10)
y[0][label] = 1.0
y = y.to(device)
#梯度下降与参数更新
out = model(x)
optimizer.zero_grad()
loss = loss_fn(out, y)
loss.backward()
optimizer.step()
lossSum += loss.item()
lossList.append(lossSum / trainNum)
#测试部分,每一个epoch训练完毕后就对测试集进行一下测试,保存一个正确率
with torch.no_grad():
errorNum = 0
for img, label in testSet:
x = img.unsqueeze(0).to(device)
out = model(x)
_, pred_y = out.max(dim = 1)
if(pred_y != label): errorNum += 1
testError.append(errorNum / testNum)
#这一段的代码就是用来改变学习率的,但是先放着,这里还不讲,因为里面涉及到判断,如果觉得会影响性能可以把这里全都注释掉
if scheduler == True:
if epoch < 2:
for param_group in optimizer.param_groups:
param_group['lr'] = 5.0e-4
elif epoch < 5:
for param_group in optimizer.param_groups:
param_group['lr'] = 2.0e-4
elif epoch < 8:
for param_group in optimizer.param_groups:
param_group['lr'] = 1.0e-4
elif epoch < 12:
for param_group in optimizer.param_groups:
param_group['lr'] = 5.0e-5
else:
for param_group in optimizer.param_groups:
param_group['lr'] = 1.0e-5
和之前的浙大AI口罩识别作业的博客里面有明显区别的地方出现啦,不知道细心的小伙伴们有没有发现呢?好啦好啦不卖关子了,出现差异的代码是在训练部分里面:
x = img.unsqueeze(0).to(device)
回顾一下之前的代码,我们会发现我们当时就直接写的to(device),根本没有出现这个unsqueeze(0)吖,这啥意思啊?别急别急,马上就说呀。
在之前的口罩识别的作业里面,我们提到Pytorch接收数据的格式是有要求的,并且我们当时还介绍了一下view的原理,事实上unsqueeze这个函数也是用于改变数据的维度的。
我们曾经提到,Pytorch的接收的数据维度中,第0维一定是batch_size,然后后面才是我们每一个样本的真实数据维度。之前的口罩作业中,我们使用了DataLoader,并且设置了batch_size = 32,在进行处理之后我们输入网络的维度就是[batch_size = 32, channel, height, width],但是这一次由于我们并没有采用DataLoader,而是直接从trainSet里面取的数据,此时取出的数据就是[channel = 1, height = 16, width = 16]的img以及int类型的label,img中根本没有batch_size的维度。
我们来看一下这个函数unsqueeze的名字,大概意思就是解压,实际上就是在指定的维度上进行展开。在不考虑其他的参数的时候,这个函数大概长下面这个样子:
unsqueeze(dim)
这个函数的实际意义是,在指定的维度dim的位置,增加一个 ‘1’,使得整个tensor被提高一个维度。对于我们的训练部分中的img.unsqueeze(0),含义就是在第0维的位置前添加上一个 '1',这样我们的图片的维度就被强制转换为[1, channel = 1, height = 16, width = 16]的形式了,正好1就代表我们batch_size = 1,就是只有一张图片。与这个函数对应的还有一个函数squeeze(dim),这个函数的功能就刚好相反了,暂时我们还用不到,等到之后用到了再说咯(我记得好像NLP作业里面就用到了)
放下学习率变化的那部分代码不谈,我们的训练函数部分基本结束······那是不可能的,我们辛辛苦苦训练的模型,还没保存呢。那就保存一下呗┓( ´∀` )┏
torch.save(model.state_dict(), 'F:\Code_Set\Python\PaperExp\LeNet-1989\epoch-{:d}_loss-{:.6f}_error-{:.2%}.pth'.format(epochs, lossList[-1], testError[-1])) #路径自己指定哟,我这个只是我自己的路径
接下来我们要做的,就是把代码全都放在一起,并且添加一些可以做的简单的可视化工作咯:
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets
from torchvision import transforms as T
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
'''
定义数据的初始化方法:
1. 将图片的尺寸强制转化为 16 * 16
2. 将数据转化成tensor
3. 将数据的灰度值范围从[0, 1]转化为[-1, 1]
'''
picProcessor = T.Compose([
T.Resize((16, 16)),
T.ToTensor(),
T.Normalize(
mean = [0.5],
std = [0.5]
),
])
'''
数据的读取和处理:
1. 从官网下载太慢了,所以先重新指定路径,并且在mnist.py文件里把url改掉,这部分可以百度,很容易找到的
2. 使用上面的处理器进行MNIST数据的处理,并加载
'''
dataPath = "F:\Code_Set\Python\PaperExp\DataSetForPaper\" #在使用的时候请改成自己实际的MNIST数据集路径
mnistTrain = datasets.MNIST(dataPath, train = True, download = False, transform = picProcessor) #首次使用的时候,把download改成True,之后再改成False
mnistTest = datasets.MNIST(dataPath, train = False, download = False, transform = picProcessor)
# 因为如果在CPU上,模型的训练速度还是相对来说较慢的,所以如果有条件的话就在GPU上跑吧(一般的N卡基本都支持)
device = torch.device("cuda:0") if torch.cuda.is_available() else torch.device("cpu")
'''
神经网络类的定义
1. 输入卷积: in_channel = 1, out_channel = 12, kernel_size = (5, 5), stride = (2, 2), padding = 2
2. 激活函数: 1.7159Tanh(2/3*x)
3. 第二层卷积: in_channel = 12, out_channel = 12, kernel_size = (5, 5), stride = (2, 2), padding = 2
4. 激活函数同上
5. 全连接层: 192 * 30
6. 激活函数同上
7. 全连接层:30 * 10
8. 激活函数同上
按照论文的说明,需要对网络的权重进行一个[-2.4/F_in, 2.4/F_in]的均匀分布的初始化
'''
class LeNet1989(nn.Module):
def __init__(self):
super(LeNet1989, self).__init__()
self.conv1 = nn.Conv2d(1, 12, 5, stride = 2, padding = 2)
self.act1 = nn.Tanh()
self.conv2 = nn.Conv2d(12, 12, 5, stride = 2, padding = 2)
self.act2 = nn.Tanh()
self.fc1 = nn.Linear(192, 30)
self.act3 = nn.Tanh()
self.fc2 = nn.Linear(30, 10)
self.act4 = nn.Tanh()
for m in self.modules():
if isinstance(m, nn.Conv2d):
F_in = m.kernel_size[0] * m.kernel_size[1] * m.in_channels
m.weight.data = torch.rand(m.weight.data.size()) * 4.8 / F_in - 2.4 / F_in
if isinstance(m, nn.Linear):
F_in = m.in_features
m.weight.data = torch.rand(m.weight.data.size()) * 4.8 / F_in - 2.4 / F_in
def forward(self, x):
x = self.conv1(x)
x = 1.7159 * self.act1(2.0 * x / 3.0)
x = self.conv2(x)
x = 1.7159 * self.act2(2.0 * x / 3.0)
x = x.view(-1, 192)
x = self.fc1(x)
x = 1.7159 * self.act3(2.0 * x / 3.0)
x = self.fc2(x)
out = 1.7159 * self.act4(2.0 * x / 3.0)
return out
lossList = []
testError = []
def train(epochs, model, optimizer, scheduler: bool, loss_fn, trainSet, testSet):
trainNum = len(trainSet)
testNum = len(testSet)
for epoch in range(epochs):
lossSum = 0.0
print("epoch: {:02d} / {:d}".format(epoch+1, epochs)) #这段主要是显示点东西,免得因为硬件问题训练半天没动静还以为电脑死机了┓( ´∀` )┏
#训练部分
for idx, (img, label) in enumerate(trainSet):
x = img.unsqueeze(0).to(device)
#将标签转化为one-hot向量
y = torch.zeros(1, 10)
y[0][label] = 1.0
y = y.to(device)
#梯度下降与参数更新
out = model(x)
optimizer.zero_grad()
loss = loss_fn(out, y)
loss.backward()
optimizer.step()
lossSum += loss.item()
if (idx + 1) % 5000 == 0: print("sample: {:05d} / {:d} --> loss: {:.4f}".format(idx+1, trainNum, loss.item())) #同样的,免得你以为电脑死了,顺便看看损失函数,看看是不是在下降,如果电脑性能比较差,可以改成100,这样每隔几秒就有个显示,起码心里踏实┓( ´∀` )┏
lossList.append(lossSum / trainNum)
#测试部分,每训练一个epoch就在测试集上进行错误率的求解与保存
with torch.no_grad():
errorNum = 0
for img, label in testSet:
x = img.unsqueeze(0).to(device)
out = model(x)
_, pred_y = out.max(dim = 1)
if(pred_y != label): errorNum += 1
testError.append(errorNum / testNum)
#这段代码是用来改变学习率的,现在先不用看,如果觉得影响性能,可以全都注释掉
if scheduler == True:
if epoch < 2:
for param_group in optimizer.param_groups:
param_group['lr'] = 5.0e-4
elif epoch < 5:
for param_group in optimizer.param_groups:
param_group['lr'] = 2.0e-4
elif epoch < 8:
for param_group in optimizer.param_groups:
param_group['lr'] = 1.0e-4
elif epoch < 12:
for param_group in optimizer.param_groups:
param_group['lr'] = 5.0e-5
else:
for param_group in optimizer.param_groups:
param_group['lr'] = 1.0e-5
torch.save(model.state_dict(), 'F:\Code_Set\Python\PaperExp\LeNet-1989\epoch-{:d}_loss-{:.6f}_error-{:.2%}.pth'.format(epochs, lossList[-1], testError[-1])) #模型的保存路径记得改成自己想要的哟
if __name__ == '__main__':
model = LeNet1989().to(device)
loss_fn = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr = 1.0e-3)
scheduler = False #因为我们还不用设置学习率改变,所以设置False
#当然啦,如果想要试试效果也可以改一下,但是我测试过要训练很多代才能达到论文中的提到的结果
epochs = 40
train(epochs, model, optimizer, scheduler, loss_fn, mnistTrain, mnistTest)
plt.subplot(1, 2, 1)
plt.plot(lossList)
plt.subplot(1, 2, 2)
testError = [num * 100 for num in testError]
plt.plot(testError)
plt.show()
训练及结果
我这边使用的是Windows10系统,显卡是1080Ti,实际上这部分的代码实测也是可以在Linux上运行的(Ubuntu可以,CentOS没试过,不过这个代码不涉及到跨平台的问题,所以应该没问题),只是需要把各部分涉及到文件路径的地方全都改成Linux的对应路径以及格式就行了。然后我是用notepad++写的,如果是用Pycharm或者VScode的,把项目结构和路径自己搞定就行啦。
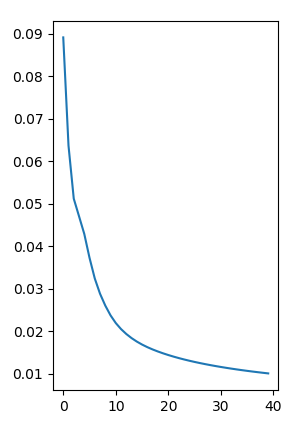
经过漫——长——地等待之后,我们的模型终于训练结束了。训练结果看下面啦:
损失函数曲线:
在测试集上的错误率曲线(%):
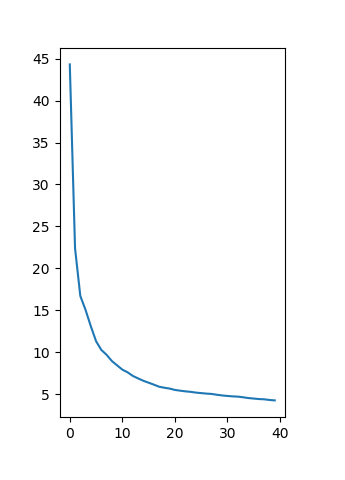
可以发现,损失函数基本收敛,到最后一轮损失函数值为0.010078,然后在测试集上的错误率是4.24%,这两个结果和论文上对应的结果······好吧毕竟在训练方式和数据集上有一些差距,所以结果上有点区别是很正常的。(论文上训练集损失函数值为2.5e-3,测试集错误率为5.0%,而且从曲线趋势上讲,我们的复现工作如果降低学习率再多跑几个epoch可能还能继续优化,但是实在是没必要┓( ´∀` )┏)
然后呢为了验证一下我们的模型到底行不行,我们可以从测试集里面随机挑几个数送到模型里面,看一看输出的结果和实际结果。如果还想验证一下模型的真实性能,也可以自己手写几张图片然后传输到模型里面,看看能输出个什么鬼东西。如果要自己手写几张图片传输到模型里面,那需要注意下面的几个问题:
- 自己拍摄或者是在画图里面画的图片,实际上是三通道的RGB图片,而模型接收的参数是单通道的灰度图,所以你需要用PIL库把图片转化为单通道灰度图,相关的方法可以百度一下啦(convert('L'),搜这个函数哟)
- 你可以从MNIST的数据集里面随便找出一个输出一下,发现里面所有的图片都是黑底白字的,你可以尝试一下如果你把自己写的白底黑字的灰度图传进去,基本正确率是0吧(大概只有0,1,8能够正确识别出来)。所以要想正确的得到识别结果,你需要把上一步转化的白底黑字的灰度图转化成黑底白字的灰度图,具体做法你可以先将PIL图(假设变量名为image)转化为numpy数组,用255 - image之后(numpy的广播操作),再转回成PIL图,这样就是黑底白字了(别问我为啥知道要这么搞,问就是这坑我掉进去过)
- 经过上面的处理之后,反正我随便手写了几十个数,因为字不算丑,所以都识别对了,大家也可以试试。草书大师们先往后稍稍,让字好看的人先来
这一部分因为实际上和训练部分非常像,我们就不贴代码了,就在这里简单说一下思路:
- 定义模型:创建一个LeNet1989的对象
- 加载模型:将之前保存的模型使用load_state_dict()函数进行加载,这部分不清楚的查一下资料吧
- 读入数据并进行处理:将数据读进来,并且按照训练的时候的那种格式进行处理,注意一下上面提到的坑
- 送入模型获得结果:这个就和训练函数里面的with torch.no_grad()后面的部分基本一样
结果反思
关于这篇论文的复现基本上就这些东西了,但是里面还是有一些东西有待思考和解决:
-
权重的初始化方法为什么是这样的,这样做合理吗?(事实上不是很合理,这部分可以参考Xavier初始化以及Hecaiming初始化的论文,因为我还没看,所以不好说什么)
-
激活函数选取这样的形式的原因是什么?(这部分我记得好像在LeNet-5的论文附录里有,到时候复现那篇文章的时候再细说好了)
-
输出的place coding没看懂,所以先拿one-hot凑合用的,如果有大佬知道这到底是啥的麻烦评论区指点一下
-
使用了一阶方法来进行参数更新,这一部分和原论文是不一致的,并且需要引入学习率这一超参数。虽然也训练出一个差不多的模型,损失函数和错误率基本收敛,但是这个收敛到底是因为真的收敛到了局部最优值附近,还是因为学习率有点大导致在一个对称区间反复横跳?(事实上学习率确实是有一点大,我们可以考虑使用那个学习率的调整部分,让学习率在训练后期下降到一个较小值)
-
每训练一个样本就进行一次参数更新,没有使用mini-batch。事实上mini-batch的思想有一点像参数估计,也就是使用样本均值来估计整体的期望(回忆一下梯度下降的公式形式,就是对所有样本的梯度取均值嘛),然而如果对每一个样本都进行参数更新,就相当于随机抽个样本用来取代期望,怎么想都不太合理嘛,虽然LeNet-5也是这么干的,但是从统计上讲这是不对的吖,这也是后面的大多数论文都使用mini-batch的原因吧,并且这也涉及到batch_size怎么选取的问题,反正挺麻烦的
-
训练的时候使用的SGD方法,但是实际上这个方法对于损失函数的“鞍点”以及“局部最优值”的表现会比较差,尤其是“鞍点”问题,这部分的原因大家可以去看一下斯坦福的CS231N,讲得还是比较清楚的,解决方案就是使用比如动量、Adam等优化的方法,不过这里因为是复现,所以就先这样用(而且Pytorch里面有现成的包,就把那个optimizer的部分改改就好咯)
-
关于那个“我就不告诉你”的那个部分没有实现,不过这一部分在后面的LeNet-5里面有说,所以等到那个时候再说好了
整体去看代码的话,其实大佬可能会对这个代码结构嗤之以鼻,因为很多可以复用的地方并没有复用,可以写到一块的地方非要分开,matplotlib画图既没有轴标题也没有图标题,连图例、颜色都没有。怎么说呢,这些东西要是真的写要发表的论文和代码,我肯定不这么写,我也是知道该怎么写的,只是我这个复现系列的博客的目的就是为了让和我一样转专业搞DL的小白萌新伙伴们能够很清晰的看到复现思路与代码结构,至于美观性和性能问题,emmmmm······大家懂了原理之后自己自然知道该怎么搞定咯。
到这里,这篇论文的复现就基本结束了。论文本身写的相当简单,但事实上复现的时候就会发现里面一大堆的坑······不过在复现过程中对每一部分的机理进行一些简单的思考,其实也是能有一些自己的理解与收获的,其实好多发文章的想法(idea)就是在复现论文的时候突发奇想,然后搞搞理论写写模型然后整出来的。我也还就是一个转专业刚刚入行的小白,看着桌子上摆的“待看论文”的小山······emmmmm,其实我内心是崩溃的TAT,总之先慢慢学习吧。那这篇就先这样,我们之后LeNet-5再见吧( ̄▽ ̄)