:一、安装jdk环境(前提)
二、安装hadoop(hadoop-2.7.7.tar.gz)
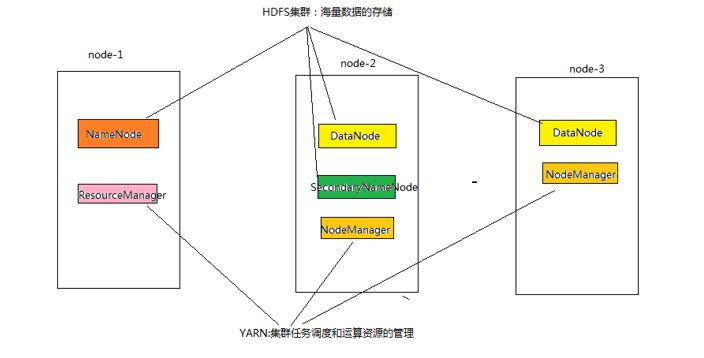
1. 角色分配(3节点搭建)
node-1 NameNode DataNode ResourceManager
node-2 DataNode NodeManager SecondaryNameNode
node-3 DataNode NodeManager

在三台服务器中配置主机名映射
注意:要保证三个节点时间同步,node-1,node-2,node-3为各个主机名,node-1为主服务器,其余为从服务器,可配置主服务器到从服务器之间免密登录
ssh-keygen -t rsa(四个回车) ssh-copy-id node-2(ssh-copy-id node-3)
2. 上传并解压hadoop-2.7.7.tar.gz(本人解压在/usr/local/java目录下),目录结构如下:

bin:Hadoop最基本的管理脚本和使用脚本的目录
etc:Hadoop配置文件的目录
include:对外提供的编程库头文件(通常用于c++程序访问HDFS或者编写MapReduce程序)
lib:包含了Hadoop对外提供的编程动态库和静态库,与include结合使用
libexec:各个服务用的shell配置文件所在目录,可用于配置日志输出,启动参数等信息
sbin:Hadoop管理脚本所在的目录,主要包含HDFS和yarn中各类服务的启动/关闭脚本
share:Hadoop各个模块编译后的jar包所在目录
3. 修改配置文件
3.1、hadoop-env.sh

修改此配置项,改为本机jdk的安装路径,本人为/usr/local/java/jdk

3.2、core-site.xml

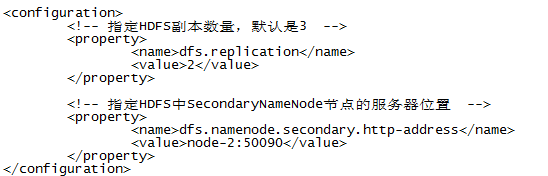
3.3、hdfs-site.xml
3.4、mapred-site.xml
mv mapred-site.xml.template mapred-site.xml

3.5、yarn-site.xml

3.6、slaves
将该文件中的内容替换成三个节点的主机名

4. 将hadoop添加到环境变量中

5. 将配置好的hadoop文件复制到其余从节点上(本人是从node-1复制到node-2和node-3上)
scp -r /usr/local/java/hadoop root@node-2:/usr/local/java/
scp -r /usr/local/java/hadoop root@node-3:/usr/local/java/
每个服务器上添加hadoop的环境变量
三、启动
首次启动HDFS,需要在主节点(namenode)上对其进行格式化(格式化只能进行一次) hdfs namenode -format或者hadoop namenode -format
如果使用一键启动,需要配置免密登录和修改slaves文件

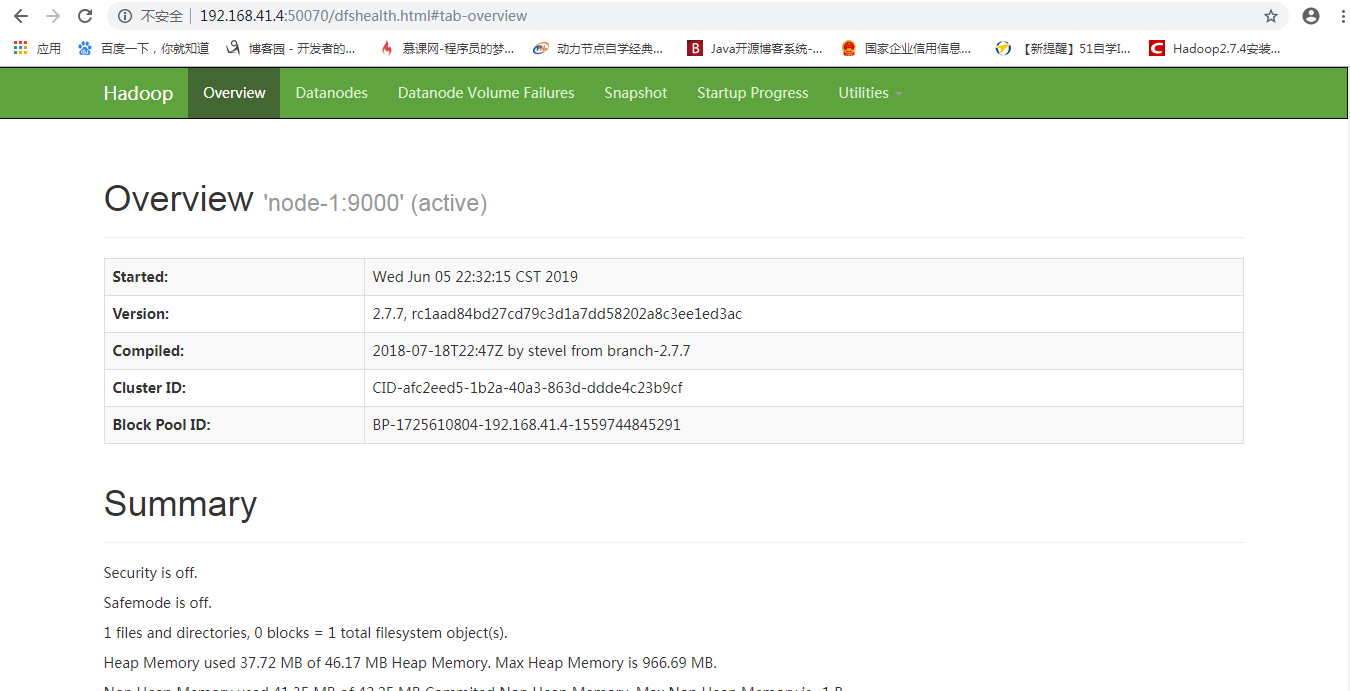
四、UI界面
NameNode` 访问NameNode所在服务器的50070端口
ResourceManager 访问ResourceManager所在服务器的8088端口