一次偶然,博主在浏览docs.oracle.com/javase的时候发现了《Hotspot虚拟机垃圾收集调优指南》这篇文档。内心百感交集,之前在看完了周志明的《深入理解Java虚拟机 JVM高级特性与最佳实践(第二版)》也有比较长篇的学习记录博客发表。不过那也是基于JDK7进行编写的。后续的8、9、10都没有找到好的关于JVM更加新的好的内容。由于性子懒惰加上本身英语不佳,一直都没上官网进行相关研究。本篇文章就是博主在研读这篇文档的时候所记录,也是基于现如今最流行的JDK8相关内容,欢迎指正。(原创内容,转载请注明出处...)
Introduction
在简介中文章指出垃圾收集器(GC)是一个内存管理工具,它通过了以下三点实现了内存管理:
1、将对象分配给新生代和晋升老的对象到老年代
2、并发标记阶段在老年代找到存活的对象。当Java堆占用率超过默认阈值时,Java Hotspot虚拟机会触发标记阶段。
3、通过并行复制压缩存活的对象来恢复空闲内存,
文中通过一个图展示了随着处理器的增多不同GC时间下吞吐量的变化(如图一),从此图中我们可以分析出的以下结论:
 (图一)
(图一)
1、在处理器比较少的情况下(少于10?),设置越高的GC占用时间百分比便越会导致吞吐量急剧下降。
2、在小型系统上可以忽略的速度问题会成为大型系统上面的瓶颈,选择合适的垃圾收集器和必要的调优是值得的
Ergonomics
Ergonomics就是JVM哈垃圾收集器调优的过程,比如基于行为的调优,提高应用程序的性能。JVM为垃圾收集器、堆大小和即时编译器提供平台相关的默认的配置。当你需要更少的命令行调优的时候,这些选项可以匹配不同类型的应用。另外,可以基于行为动态调整堆的大小以满足应用程序的特定行为。这一节描述了这些默认选择和基于行为的调优。
以下是GC、堆和运行时编译器的默认选择说明:
一个被定义为Server-Class所在机器的要求:
1、两个或以上的处理器
2、2GB或以上的物理内存
在Server-Class机器上,一下是默认选项:
1、吞吐量优先垃圾收集器
2、堆初始化大小为物理内存的1/64,最大为1GB
3、最大的堆大小范围为物理内存的1/4到1GB
4、Server模式的运行时编译器
上面的定义适用于除window 32位系统以外的其他所有平台。默认运行时编译器详情可以查看官方说明。
基于行为的调优:
对并行收集器来说,JavaSE基于特定行为的基础上提供了两个垃圾收集调优参数:最大暂停时间和应用程序的吞吐量。
最大暂停时间:暂停时间是垃圾收集器停止应用程序并恢复已不再使用的空间的持续时间。最大暂停时间目标的目的是限制这些暂停时间最长的时间。通过命令行 -XX:MaxGCPauseMillis=<nnn>来指定。通过这个参数的设置,垃圾收集器会调整堆的大小和其他相关参数让暂停时间尽量接近所设置的最大暂停时间。默认情况下,如果没有最大暂停时间这些调整可能导致频繁GC从而降低应用程序的吞吐量
吞吐量:吞吐量是由垃圾收集时间和应用程序时间来衡量的。通过-XX:GCTimeRatio=<nnn>来设置吞吐量的大小。比如 -XX:GCTimeRatio=19表示垃圾收集的时间占总应用时间的1/20或者5%。JVM为垃圾收集器、堆大小和即时编译器提供平台相关的默认的配置。当你需要更少的命令行调优的时候,这些选项可以匹配不同类型的应用。另外,可以基于行为动态调整堆的大小以满足应用程序的特定行为。这一节描述了这些默认选择和基于行为的调优。垃圾收集的时间是新生代和老年代GC时间的和。如果吞吐量目标没有实现的话,为了让应用程序运行时间在与垃圾收集时间所占比重增加,JVM会增大新生代和老年代的大小。
如果达到了吞吐量和最大暂停时间目标,那么垃圾收集器就会减少堆的大小,直到让一个目标(总是吞吐量目标)无法满足。没有达到的目标就会被解决(放弃?)
调优策略:
1、不要设置堆的最大值除非你知道你需要一个比默认最大堆大小更大的堆。选择一个对你的应用来说足够了的吞吐量目标。
为了实现设定的吞吐量,堆将增大或缩减到一个大小。应用程序行为的改变会导致堆的增长或收缩。例如,如果应用程序开始以更高的速率分配,堆将会增长以保持相同的吞吐量。
2、如果堆增长到最大值且设置吞吐量目标没有达到,那么最大堆大小对于吞吐量目标来说太小了。将最大堆大小设置为接近于平台的总物理内存的值,但不会导致应用程序的交换。再次执行应用程序。如果吞吐量目标仍然没有满足,那么应用程序时间的目标对于平台上可用的内存来说太高了。
3、如果能够满足吞吐量目标,但是有一些暂停太长,然后选择一个最大的暂停时间目标。选择一个最大的暂停时间目标可能意味着您的吞吐量目标将无法满足,因此选择对于应用程序来说是可接受的折衷方案。
4、通常情况下,堆的大小会随着垃圾收集器试图满足相互竞争的目标而振荡。即使应用程序已经达到了稳定状态,这也是正确的。实现吞吐量目标(可能需要更大的堆)的压力与最大暂停时间和最小内存占用(两者都可能需要一个小堆)的目标竞争。
Generations
分代收集算法的依据便是:绝大部分新产生的对象应该要被回收。如下图二,所展示的对象生命周期的典型分布。
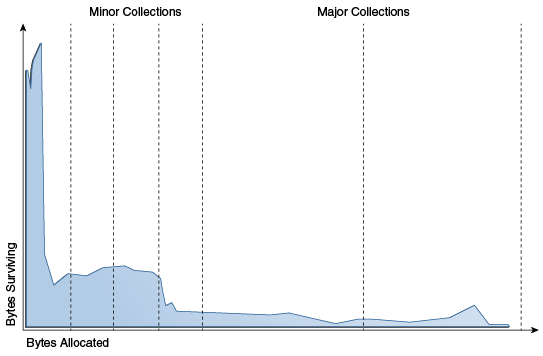
(图二)
注意:如果垃圾收集成为了瓶颈,你很可能不得不定制总的堆大小以及各个代的大小。检查详细的垃圾收集器输出,然后探索单个性能指标对垃圾收集器参数的敏感度
默认的分代排列图(除了Parallel Collector 和 G1)如下图三
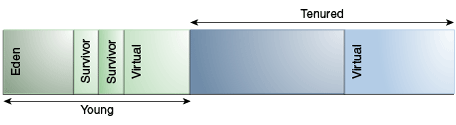
(图三)
打印GC日志:
使用命令行:-verbose:gc 打印示例如下
[GC 325407K->83000K(776768K), 0.2300771 secs] [GC 325816K->83372K(776768K), 0.2454258 secs] [Full GC 267628K->83769K(776768K), 1.8479984 secs]
前面两条显示的是minor GC,第三条显示的事major GC。箭头前后显示的是垃圾收集前后的活动对象的组合大小。括号里面是空闲空间大小。最后面的事垃圾收集执行的时间。
使用命令行:-XX:+PrintGCDetails 打印示例如下
[GC [DefNew: 64575K->959K(64576K), 0.0457646 secs] 196016K->133633K(261184K), 0.0459067 secs]
表明垃圾收集器在新生代将64575K的已用容量大小回收至959K容量大小。花费了0.0457646秒。整个堆的使用大小从196016K变成了133633K。
使用命令行:-XX:+PrintGCTimeStamps 打印示例如下
111.042: [GC 111.042: [DefNew: 8128K->8128K(8128K), 0.0000505 secs]111.042: [Tenured: 18154K->2311K(24576K), 0.1290354 secs] 26282K->2311K(32704K), 0.1293306 secs]
在前面添加了时间戳。这是一个老年代收集日志。
Sizing the Generations
很多参数影响新生代和老年代的大小,下图四体现了提交空间与虚拟空间的区别。预留空间的大小可以用-Xmx选项指定。

(图四)
Total Heap:
关于堆和默认堆大小的增长和收缩的讨论并不适用于并行收集器。然而,控制堆的总大小和几代的大小的参数确实适用于并行收集器。
影响垃圾收集性能的最重要的因素是可用内存总量,因为当各个”代“被填满产生GC的时候,吞吐量与可用的内存数量成反比。
默认情况下,虚拟机在每个垃圾收集操作中增加或收缩堆,以试图将每个垃圾收集操作后的活动对象和空闲空间的比例保持在一个特定范围内的。这个比例值由-XX:MinHeapFreeRatio=<minimum>和-XX:MaxHeapFreeRatio=<maximum>控制。总堆的大小范围在-Xms和-Xmx的之间。
survivor size:
在总堆大小设置之后,影响垃圾收集性能的第二大影响因素是用于新生代的堆的比例。新生代越大,minor GC发生的次数就越少。然而,对于一个有限的堆来说,越大的新生代意味着越小的老年代。这将导致频繁的major GC。最佳的选择取决于应用程序分配的对象的生命周期分布。
默认情况下,新生代大小由-XX:NewRatio=<n>控制。如果n=3,则意味着新生代与老年代的比例为1:3。通过NewSize和MaxNewSize可以设置新生代大小的范围,对缩小调优粒度来说是非常有效的。
我们可以通过-XX:SurvivorRatio=<n>来设置 survivor区的大小。例如n=6,则意味着survivor区与Eden区的比例为1:6,因为有两个survivor区,所以survivor的大小占新生代总大小的1/8。如果survivor区太小,复制垃圾收集器溢出便会直接将该对象放入老年代。如果survivor太大,他们将毫无用处。虚拟机会设置一个阀值,对象达到了相应复制(垃圾回收)的次数便会升级到老年代。命令行-XX:+PrintTenuringDistribution 可以用来显示新生代的阈值和对象的年龄。它对于观察应用程序的生命周期分布也很有用。
Available Collectors
这里讨论的是serial collector。Java HotSpot VM包含三种不同类型的收集器,每种类型都具有不同的性能特征。
1、串行收集器使用单个线程来执行所有垃圾收集工作,这使得它相对高效,因为线程之间没有通信开销。它最适合于单处理器机器,因为它不能利用多处理器硬件,尽管它对于具有小数据集的应用程序的多处理器非常有用(高达大约100 MB)。串行收集器在某些硬件和操作系统配置上默认选择,或者可以显式地启用选项-XX:+UseSerialGC。
2、并行收集器(也称为吞吐量收集器)并行执行minor GC,这可以显著减少垃圾收集开销。它适用于在多处理器或多线程硬件上运行的中型到大型数据集的应用程序。并行收集器在某些硬件和操作系统配置上默认选择,也可以通过选项-XX:+UseParallelGC显式启用。
3、大多数并发收集器可以并行的执行大部分工作(例如,当应用程序仍在运行时),以防止垃圾收集暂停。它是为具有中型到大型数据集的应用程序设计的,其中它响应时间比总体吞吐量更重要,因为用于最小化停顿的技术可以降低应用程序的性能。Java HotSpot VM提供了两个主要并发收集器之间的选择。使用选项-XX:+UseConcMarkSweepGC启用CMS收集器或-XX:+UseG1GC启用G1 收集器。
除非你的应用程序有相当严格的暂停时间需求,首先运行您的应用程序,并允许VM选择一个收集器。如果有必要,调整堆大小以提高性能。如果性能仍然不能满足您的目标,那么使用下面的指导方针作为选择收集器的依据:
1、如果你的应用有一个小的数据集(通常小于100MB),那么你就利用下面的命令行选用串行收集器:-XX:+UseSerialGC.
2、如果你的应用在一个单处理器上运行,且没有暂停时间需求,那就让虚拟机自动选择垃圾收集器或者用下面的命令行选用串行收集器:-XX:+UseSerialGC.
3、如果你的peak应用程序性能是第一优先级,且没有暂停时间要求或1秒或更长时间的暂停可以接受,那就让虚拟机自动选择垃圾收集器或者用下面命令行选用并行垃圾收集器:-XX:+UseParallelGC.
4、如果响应时间比总体吞吐量更重要,垃圾收集暂停必须保持在大约1秒的时间内,那么就选用并发收集器:-XX:+UseConcMarkSweepGC 或者 -XX:+UseG1GC.
因为性能依赖于堆的大小、应用程序维护的实时数据量以及可用处理器的数量和速度,上面这些指导原则只提供了选择收集器的依据。暂停时间对这些因素特别敏感,因此前面提到的1秒的阈值仅是近似的:在许多数据大小和硬件组合上,并行收集器将经历超过1秒的暂停时间;相反,在某些组合上,并发收集器可能无法保持小于1秒的暂停。
如果推荐的收集器没有达到预期的性能,首先尝试调整堆和生成大小以满足期望的目标。如果性能仍然不够,那么尝试一个不同的收集器:使用并发收集器来减少暂停时间,并使用并行收集器来提高多处理器硬件的总体吞吐量。