我们用训练集训练出一个初步的模型后,并不能直接使用该模型,而是要对该模型进行诊断,并不断对模型进行调整。
现以普林斯顿大学教授工资数据集为例,来说一下如何对模型进行诊断和对结果进行解读。数据集下载地址:http://data.princeton.edu/wws509/datasets/salary.dat。
数据集特征如下:
sx = Sex, female and male
rk = Rank, assistant professor, associate professor, full professor
yr = Number of years in current rank
dg = Highest degree, doctorate and masters
yd = Number of years since highest degree was earned
sl = Academic year salary, in dollars
假设我们通过特征选择,形成的一个初步的模型用了rk和yr这两个变量。用R进行拟合的模型为:fit1=lm(sl~factor(rk)+yr,data=salary)。
下面对这个初步的模型fit1进行诊断:
一,该线性回归模型是否满足基本假设条件?
1,x和y之间是否线性相关?(即:模型是否能很好地拟合数据?)
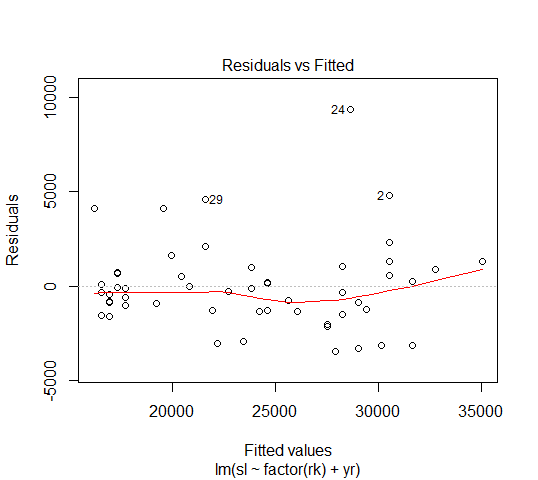
画残差图:可用R的plot(fit1, which=1)
画偏残差图:可用R的car包里的crPlots(fit1)
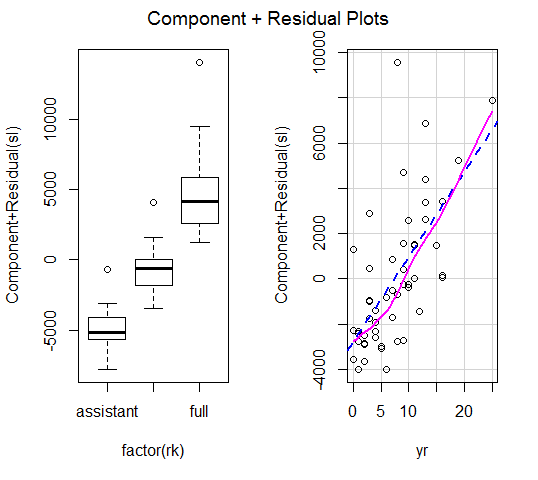
从残差图上看不出有什么规律,说明模型拟合数据较好。
2,特征之间是否存在相关关系?(即:是否有共线性问题?)
计算VIF:可用R的car包里的vif(fit1)
GVIF Df GVIF^(1/(2*Df)) factor(rk) 1.34824 2 1.077561 yr 1.34824 1 1.161138
特征的VIF都很小,可以认为不存在共线性的问题。
3,误差项之间是否相互独立?(即:是否有自相关问题?)
做杜宾-瓦特森检验:可用R的car包里的durbinWatsonTest(fit1)
lag Autocorrelation D-W Statistic p-value 1 0.06247094 1.808368 0.398 Alternative hypothesis: rho != 0
p值大于0.05,可以认为误差之间相互独立。
4,误差项是否服从正态分布?
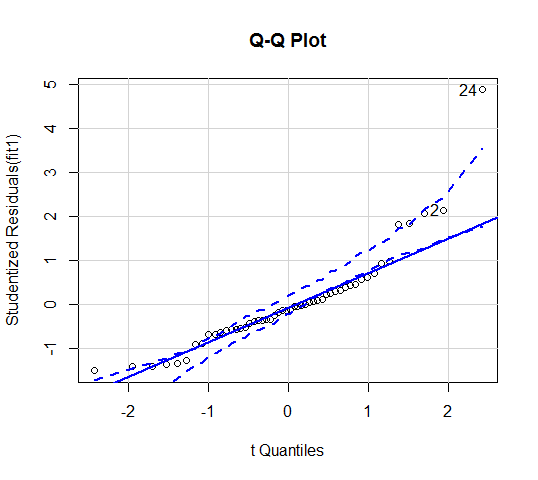
画Q-Q图:可用R的car包里的qqPlot(fit1, labels = row.names(data), id.method = "identify", simulate = TRUE, main = "Q-Q Plot")
也可用R的plot(fit1, which=2)
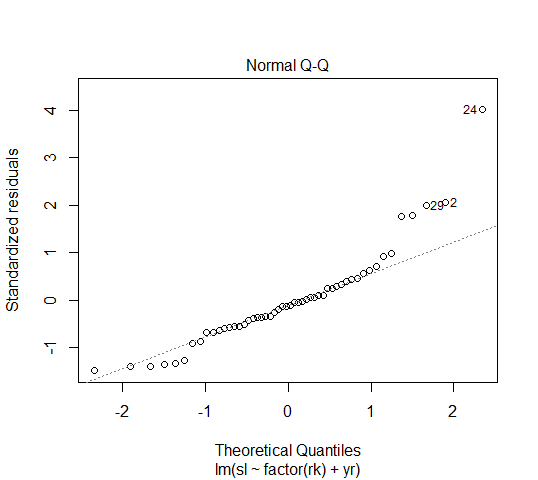
有些许点偏离了对角线,因此不完全服从正态分布。
5,误差项的方差是否基本不变?(即:是否有异方差问题?)
画残差图:可用R的car包里的spreadLevelPlot(fit1)
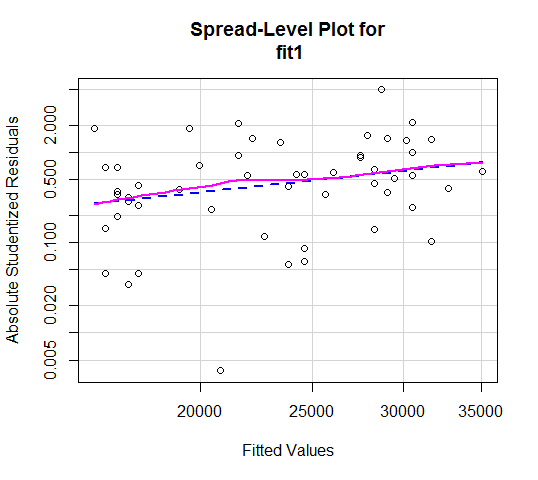
也可用R的plot(fit1, which=3)
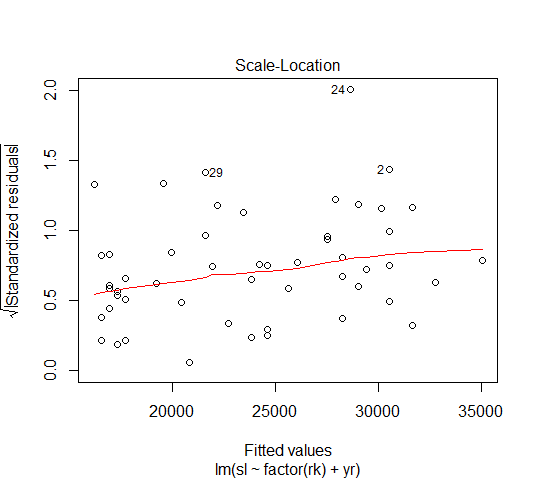
从残差图上看不出有什么规律,说明没有异方差问题。
二,其他诊断
1,是否有异常点和强影响点?
异常点:计算学生化残差,可用R的outlierTest(fit1)
rstudent unadjusted p-value Bonferroni p
24 4.883852 1.2445e-05 0.00064712
p<0.05,说明24是异常点。但是一次只能测一个点,因此还可用R的rstudent(fit1)计算删除学生化残差,如删除学生化残差的绝对值大于3,可认定为异常值。
强影响点:计算Cook's D,可用R的plot(fit1, which=4)
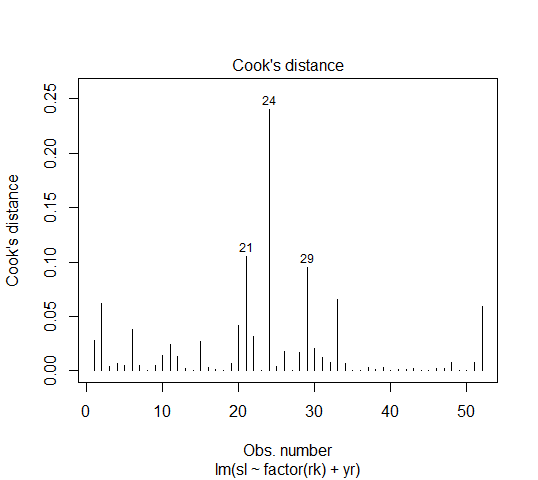
没有Cook's D大于0.5的点,可以认为没有强影响点。
也可用R的car包里的influencePlot(fit1, main="Influence Plot")把异常点,高杠杆点和强影响点一网打尽:
StudRes Hat CookD
1 0.6123891 0.22946768 0.02828899
2 2.1335846 0.05481303 0.06144973
21 -1.4094468 0.17759400 0.10508576
24 4.8838522 0.05612032 0.24019148
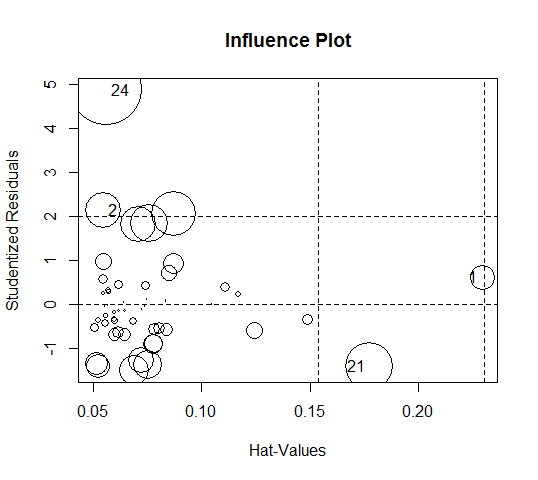
可以看出,其中1和21是高杠杆点。24是异常点。
2,是不是至少有一个自变量对于预测因变量是有用的?
看F-test结果:可用R的summary(fit1)
Call:
lm(formula = sl ~ factor(rk) + yr, data = salary)
Residuals:
Min 1Q Median 3Q Max
-3462.0 -1302.8 -299.2 783.5 9381.6
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 16203.27 638.68 25.370 < 2e-16 ***
factor(rk)associate 4262.28 882.89 4.828 1.45e-05 ***
factor(rk)full 9454.52 905.83 10.437 6.12e-14 ***
yr 375.70 70.92 5.298 2.90e-06 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 2402 on 48 degrees of freedom
Multiple R-squared: 0.8449, Adjusted R-squared: 0.8352
F-statistic: 87.15 on 3 and 48 DF, p-value: < 2.2e-16
p<0.05,说明至少有一个自变量对于预测因变量是有用的。
3,是所有的自变量都有用还是只有一部分自变量有用?
看t-test结果:可用R的summary(fit1)
Call:
lm(formula = sl ~ factor(rk) + yr, data = salary)
Residuals:
Min 1Q Median 3Q Max
-3462.0 -1302.8 -299.2 783.5 9381.6
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 16203.27 638.68 25.370 < 2e-16 ***
factor(rk)associate 4262.28 882.89 4.828 1.45e-05 ***
factor(rk)full 9454.52 905.83 10.437 6.12e-14 ***
yr 375.70 70.92 5.298 2.90e-06 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 2402 on 48 degrees of freedom
Multiple R-squared: 0.8449, Adjusted R-squared: 0.8352
F-statistic: 87.15 on 3 and 48 DF, p-value: < 2.2e-16
所有自变量参数估计值的p<0.05,说明所有的自变量都有用。
4,是否需要增加交互项?
从业务角度分析,有可能产生协同效应的变量间才考虑交互项。(此处略过)
5,是否需要增加特征?
需从业务角度考虑。(此处略过)
从上述的诊断中可以看出,除了误差项不服从正态分布以及有一个点是异常点之外,其他都没有问题。而误差项不服从正态分布的原因很可能是由于异常点的缘故。通过查看异常点,发现应该不是记录有误,因此在此保留该异常点。
假设现在我们通过交叉验证选择出了最好的模型(假设还是模型fit1),现对这个模型的结果进行解读:
一,预测
1,对于给定的自变量的值,对因变量进行预测,预测的准确度有多少?
点估计: 可用R的predict(fit1,data.frame(rk=c('assistant','full'), yr=c(8,15)))
1 2 19296.83 30896.11
区间估计:
置信区间(Cofidence Interval):模型平均的预测准确度,可用R的predict(fit1,data.frame(rk=c('assistant','full'), yr=c(8,15)), interval = "confidence")
fit lwr upr
1 19296.83 18256.19 20337.47
2 30896.11 29857.47 31934.76
预测区间(Prediction Interval):对单个样本预测的准确度,可用R的predict(fit1,data.frame(rk=c('assistant','full'), yr=c(8,15)), interval = "prediction")
fit lwr upr
1 19296.83 15185.27 23408.39
2 30896.11 26785.06 35007.16
这里提供两个全新的点供模型来预测,并且分别用interval指定返回置信区间或者预测区间。预测区间一定比置信区间要宽。
二,推断
1,哪个自变量对模型最重要?
用自变量的参数估计值除以标准误差(注:不能直接用参数估计值进行衡量,因为各个变量的单位不一样,需要消除量纲的影响)
Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 16107.62 526.05 30.620 < 2e-16 *** factor(rk)associate 4192.32 726.84 5.768 6.03e-07 *** factor(rk)full 8808.72 757.21 11.633 1.95e-15 *** yr 398.65 58.56 6.808 1.60e-08 ***
可以看出,计算出的结果就是t值。也就是说t值越大,该特征能提供更多的信息,也就是对模型来说越重要。
参考: