网上一直没有找到Kitti数据集,于是决定使用之前的安全帽数据集。
1.获取安全帽图片并且按顺序标号(之前的博客中已经说明详细步骤)
2.给图片中的安全帽打框,生成xml文件,其中的坐标对应每个安全帽的位置。
使用工具:labelImg
需安装的第三方库:
python,PyQt5 , lxml
1.Python的安装 (略)
2.pip安装PyQt5
进入cmd(win键+R键,输入cmd),输入:
pip install PyQt5
3.安装lxml
进入cmd(win键+R键,输入cmd),输入:
pip install lxml
4.安装labelImg
labelImg下载地址:
https://github.com/tzutalin/labelImg.git
进入cmd(win键+R键,输入cmd),进入labelImg文件夹,输入:
pyrcc5 -o resources.py resources.qrc
输入:python labelImg.py
即可打开labelImg。
1)打开界面如下:

(2)给图片打框,界面如下:
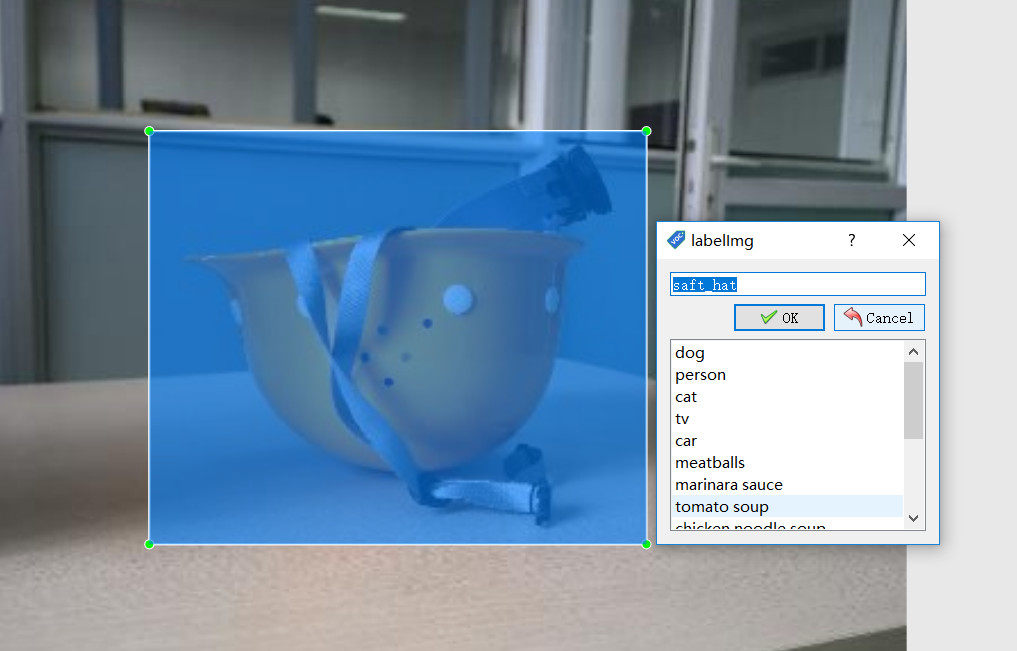
(3)生成xml文件,内容如下:

(4)将需要训练的所有图片进行该操作。
但是查看Fast R-CNN算法中,使用到的数据集格式并不是xml,而是txt格式,最前面为图片地址,中间为坐标,最后为检测物体的标签。Kitti数据集部分截图如下:

3.按照Kitti的格式,将已经生成的xml文件转化为txt
代码如下:
import xml.dom.minidom
import os
import os.path
i=0
for ii in range(1,500):
print('这是第',ii,'张图片')
s = '%05d' % ii # 补0
src = 'F:/ProPycharm/PyProject/XmlToTxt-master/data/train_val_00001-00499xlm/'+str(s)+''+'.xml'
# print(src)
# 保存生成的txt地址
save_dir = 'F:/ProPycharm/PyProject/XmlToTxt-master/data/train_val_00001-00499txt'
if not os.path.exists(save_dir):
os.mkdir(save_dir)
f = open(os.path.join(save_dir, 'name.txt'), 'a')
DOMTree = xml.dom.minidom.parse(src)
annotation = DOMTree.documentElement
filename = annotation.getElementsByTagName("filename")[0]
imgname = 'F:/ProPycharm/PyProject/XmlToTxt-master/data/train_val_00001-00499txt/'+filename.childNodes[0].data
# print(imgname)
objects = annotation.getElementsByTagName("object")
loc = [] # 文档保存格式:文件名 坐标
imaname00 =[]
for object in objects:
bbox = object.getElementsByTagName("bndbox")[0]
leftTopx = bbox.getElementsByTagName("xmin")[0]
lefttopx = leftTopx.childNodes[0].data
leftTopy = bbox.getElementsByTagName("ymin")[0]
lefttopy = leftTopy.childNodes[0].data
rightTopx = bbox.getElementsByTagName("xmax")[0]
righttopx = rightTopx.childNodes[0].data
rightTopy = bbox.getElementsByTagName("ymax")[0]
righttopy = rightTopy.childNodes[0].data
name = object.getElementsByTagName('name')[0]
# print(lefttopx, lefttopy, righttopx, righttopy, name.childNodes[0].data)
loc = loc + [imgname, lefttopx, lefttopy, righttopx, righttopy, name.childNodes[0].data]
# print(loc)
for num in range(len(loc)):
print(str(loc[num]))
if num % 6 == 5:
f.write(str(loc[num]))
f.write(' ')
else:
f.write(str(loc[num]) + ',')
# f.write(' ')
f.close()
注意:
1.最开始生成的txt中,全部以“,”为分隔符,导致标签后面依然有一个多余的“,”
解决方法:对每一行的数据长度进行取余操作,如果长度为6,就换行。因为每行保存的数据中,只有6个:一个地址,四个坐标。一个标签。如果不是这样,就以“,”为分隔符写进去。
2.在进行for循环时,虽然读取了500张图片的xml,但是保存的txt文件中只有最后一张图片的信息,前面499张图片的信息都没有保存。因为没for一次,保存的信息会自动刷新一次,所以前面499张图片的txt内容被覆盖了!
解决方法:将f = open(os.path.join(save_dir, 'name.txt'), 'w') 换为 f = open(os.path.join(save_dir, 'name.txt'), 'a')
最终生成了正确的txt,内容如下:
