最近有一门考试要用到部分相关姿势, 索性就把知识点完善和整理一下

如果你有一定基础, 只是分不清楚它们的区别可又不想看我逼逼赖赖的话可以直接跳到总结部分
进入正题, 众所周知, 人看文字计算机只看0和1, 那么为了解决人和计算机之间的信息交互问题, 就必须要把我们日常交流的文字转换成数字才能供计算机使用.
很久以前有一个程序员甲的幸运数字是48, 他就把48作为大写英文字母A所对应的编码, 而另一个程序员乙却说他的幸运数字是49, 他要把49作为大写英文字母A对应的编码, 所以当用甲的编码解码方式去读取乙写的程序就会出现乱码(乙写的A甲会读成B), 显然这样子的矛盾令程序员十分头大, 于是美国国家标准学会看不下去了, 推出了编码标准"ASCII" 里面规定了常用英文符号, 指令, 字母等所对应的数字, 从而解决了这个问题.
英语通过26个字母的组合变换构成单词, 可汉字却有成千上万个, 总不能就指望ASCII放弃汉字就打拼音吧? 于是中国国家标准总局通过扩编(借鉴)ASCII码颁布了信息交换用汉字编码字符集(GB2312).
但随着国家的发展, 文化水平的提高, 两万多个常用字渐渐显得不够用了, 于是BGK就诞生了, 它涵盖了GB2312的所有内容, 并在这个基础上进行了扩展.
再后来, 考虑到既然我们不能放弃汉字打拼音, 那么其他民族自然也不能放弃他们流传至今的文字统统改用汉字呀, 所以就有了GB18030, 这个字符集对其他民族的语言(如藏文)进行了扩充.
至此, 汉字和英语的文字信息数字化问题得到了解决, 可是世界上那么多种语言, 就有那么多种编码标准与字符集. 如果不作统一, 跨语言跨平台的交流, 信息传播都将面临巨大的问题.(网页乱码, 程序乱码等)
所以国际标准化组织(ISO)为了解决这个问题, 颁布了Unicode码.
而伴随而生的就是UTF-8和UTF-16, 它们两不同于上述的各种各样的编码, 比较特殊, 他们只是一种编码标准而非字符集, 它们所使用的字符集依旧是Unicode, 正如0013和13在十进制中表示的是同一个数一样; 它们比起使用Unicode直接表示信息更加的节省内存以及可以解决编码冲突等; 在这里不再展开叙述.
做个总结
ASCII - 解决英文数字化问题
GB2312 - 解决汉字数字化问题
GBK - 扩展了GB2312字符集
GB18030 - 扩展了GBK字符集(主要是少数民族语言)
Unicode - 解决了跨语言跨平台的编码问题
↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑它们既是字符集同时也是编码标准↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑
↓↓↓↓↓↓它们只是编码标准, 如果不依赖于字符集, 它们本身并不能表示任何信息↓↓↓↓↓↓
UTF-8
UTF-16
UTF-32
它们三者都是基于Unicode字符集的编码标准, 也就是换种方法表示同一个信息; 正因为如此, GB和UTF之间的转换必须依赖于Unicode
GB→Unicode→UTF
万国码 国标码 区位码 机内码
万国码就是Unicode, 叫法不同而已, 不再赘述
国标码就是GB18030(旧的可能是GB2312, 但GB18030基本向下兼容)
机内码就是国标码字符集最终给计算机使用的十六进制数
机内码是从A0A0H开始的(H表示十六进制, 后面不再赘述), 原因是不与ASCII码混淆.(同刚才甲和乙的问题)
(为什么是A0A0H? 下面有讲)
区位码就是国标码的十进制表示方式
Ps: 在输入法中按下v1~9所出现的特殊字符就是区位码01~09区内的特殊字符(智能ABC不行喔)
三者的换算
其实本质就是进制转换和加减法. (如果你不明白进制转换, 请务必先去学习它)
首先明确在4位数中, 分为高位(前两位)和低位(后两位), 在进制转换中需要分别转换.
其次, 国标码为了在计算机表示中(机内码)不与ASCII码混淆, 转为机内码时需要将前A0H位留空(目前ASCII占用80H位, 为防止未来继续扩展, 又冗余了20H位, 一共A0H)
所以结论就是 区位码 < 国标码 < 机内码, 这里引用一张图来说明三者之间的换算
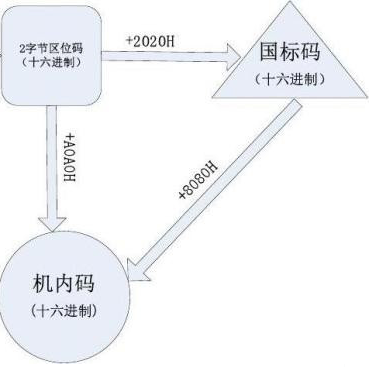

很感谢你能看到这里, 如果这篇文章对你有所帮助, 不妨点个赞吧?
2020年4月29日