目录
Numpy
import numpy as np
#类型转换
arr = np.array([3.7,-1.2,-2.6,0.5,12.9,10.1])
arr.astype(np.int32)
# 转置
arr.T
# 三元表达式的矢量运算
np.where(条件,值1,值2)
# 排序 sort() `也支持指定轴排序`
arr = np.random.randn(5, 3)
arr.sort(1) # 按 第二个维度排序
# 唯一值
arr.unique()
# 当前数组是否存在 值
values = np.array([6, 0, 0, 3, 2, 5, 6])
np.in1d(values, [2, 3, 6])
array([ True, False, False, True, True, False, True], dtype=bool)



数组统计方法
多维中,设置axis属性, 1相当于计算列, 0相当于计算行


数组的集合运算

线性代数

伪随机数


Pandas
import pandas as pd
import numpy as np
Index

Series
1.创建Series对象
# data参数表示数据,index参数表示数据的索引(标签)
# 如果没有指定index属性,默认使用数字索引
ser1 = pd.Series(data=[320, 180, 300, 405], index=['一季度', '二季度', '三季度', '四季度'])
# 字典中的键就是数据的索引(标签),字典中的值就是数据
ser2 = pd.Series({'一季度': 320, '二季度': 180, '三季度': 300, '四季度': 405})
2.Series对象的常用属性及方法
| 属性 | 说明 |
|---|---|
dtype / dtypes |
返回Series对象的数据类型 |
hasnans |
判断Series对象中有没有空值 |
at / iat |
通过索引访问Series对象中的单个值 |
loc / iloc |
通过一组索引访问Series对象中的一组值 |
index |
返回Series对象的索引 |
is_monotonic |
判断Series对象中的数据是否单调 |
is_monotonic_increasing |
判断Series对象中的数据是否单调递增 |
is_monotonic_decreasing |
判断Series对象中的数据是否单调递减 |
is_unique |
判断Series对象中的数据是否独一无二 |
size |
返回Series对象中元素的个数 |
values |
以ndarray的方式返回Series对象中的值 |
# 求和
ser2.sum()
# 求均值
ser2.mean()
# 求最大
ser2.max()
# 求最小
ser2.min()
# 计数
ser2.count()
# 求标准差
ser2.std()
# 求方差
ser2.var()
# 求中位数
ser2.median()
3.数据处理
# 排序
# ascending 升序(True)还是降序(False),默认True
# kind 排序的算法,quicksort,mergesort,heapsort 默认quicksort
# na_position 空值的展示位置,默认last
ser2.sort_index() # 按索引排序
ser2.sort_values() # 按值排序
# 获取最大/最小的前N个(无需排序) ,nlargest()和nsmallest()
order.nlargest(3) # 值最大的3个
order.nsmallest(2) # 值最小的2个
# 去重
ser2.unique() # 返回去重后的唯一的 Series 对象
ser2.duplicated() # 统计重复项,返回bool 的Series 对象
ser2.drop_duplicates() # 去重
# 统计不重复值的数量
ser2.nunique()
# 统计值出现的次数
ser2.value_counts()
# 判空
ser2.isnull()
ser2.notnull()
# 填充/删除空值
# inplace参数,默认False,是否修改原先的对象(否则返回新的对象,是则返回None)
ser2.dropna() # 删除空值
ser2.fillna(value=40) # 填充空值为40
# fillna(method='ffill') 表示用前一个元素的值填充空值
# fillna(method='bfill') 表示用后一个元素的值填充空值
# 替换
ser2.where(ser2 > 0,10) # 满足条件->替换成10
ser2.mask(ser2 > 0,10) # 不满足条件->替换成10
# 执行函数/数据处理
# `apply()`和`map()`
ser6 = pd.Series(['cat', 'dog', np.nan, 'rabbit'])
ser6.map({'cat': 'kitten', 'dog': 'puppy'}) # kitten,puppy,NaN,NaN
ser6.map('I am a {}'.format, na_action='ignore')
0 I am a cat
1 I am a dog
2 NaN
3 I am a rabbit
ser7 = pd.Series([20, 21, 12])
ser7.apply(np.square) # 400,441,144
ser7.apply(lambda x, value: x - value, args=(5, )) # 15,16,7
4.绘制图表
Series对象有一个名为plot的方法可以用来生成图表,如果选择生成折线图、饼图、柱状图等,默认会使用Series对象的索引作为横坐标,使用Series对象的数据作为纵坐标。
# kind 参数
- 'line' : line plot (default)
- 'bar' : vertical bar plot
- 'barh' : horizontal bar plot
- 'hist' : histogram
- 'box' : boxplot
- 'kde' : Kernel Density Estimation plot
- 'density' : same as 'kde'
- 'area' : area plot
- 'pie' : pie plot
- 'scatter' : scatter plot
- 'hexbin' : hexbin plot.
# 修改字体中文的默认配置
import matplotlib.pyplot as plt
# 配置支持中文的非衬线字体(默认的字体无法显示中文)
plt.rcParams['font.sans-serif'] = ['SimHei', ]
# 使用指定的中文字体时需要下面的配置来避免负号无法显示
plt.rcParams['axes.unicode_minus'] = False
# 柱状图
ser9 = pd.Series({'一季度': 400, '二季度': 520, '三季度': 180, '四季度': 380})
# 通过Series对象的plot方法绘图(kind='bar'表示绘制柱状图)
ser9.plot(kind='bar', color=['r', 'g', 'b', 'y'])
# x轴的坐标旋转到0度(中文水平显示)
plt.xticks(rotation=0)
# 在柱状图的柱子上绘制数字
for i in range(4):
plt.text(i, ser9[i] + 5, ser9[i], ha='center')
# 显示图像
plt.show()
# 饼状图
# autopct参数可以配置在饼图上显示每块饼的占比
ser9.plot(kind='pie', autopct='%.1f%%')
# 设置y轴的标签(显示在饼图左侧的文字)
plt.ylabel('各季度占比')
plt.show()
DataFrame
1.数据获取
# 创建 DataFrame对象
df1 = pd.DataFrame(data=np.random.randint(60, 101, (5, 3)), columns=['语文', '数学', '英语'], index=[1001, 1002, 1003, 1004, 1005])
scores = {
'语文': [62, 72, 93, 88, 93],
'数学': [95, 65, 86, 66, 87],
'英语': [66, 75, 82, 69, 82],
}
df2 = pd.DataFrame(data=scores, index=[1001, 1002, 1003, 1004, 1005])
# csv
read_csv()
- `sep` / `delimiter`:分隔符,默认是`,`。
- `header`:表头(列索引)的位置,默认值是`infer`,用第一行的内容作为表头(列索引)。
- `index_col`:用作行索引(标签)的列。
- `usecols`:需要加载的列,可以使用序号或者列名。
- `true_values` / `false_values`:哪些值被视为布尔值`True` / `False`。
- `skiprows`:通过行号、索引或函数指定需要跳过的行。
- `skipfooter`:要跳过的末尾行数。
- `nrows`:需要读取的行数。
- `na_values`:哪些值被视为空值。
df3 = pd.read_csv('2018年北京积分落户数据.csv', index_col='id')
# excel
- `sheet_name` : 数据表
- `header`:表头(列索引)的位置,默认值是`infer`,用第一行的内容作为表头(列索引)。
- `index_col`:用作行索引(标签)的列。
- `usecols`:需要加载的列,可以使用序号或者列名。
- `true_values` / `false_values`:哪些值被视为布尔值`True` / `False`。
- `skiprows`:通过行号、索引或函数指定需要跳过的行。
- `skipfooter`:要跳过的末尾行数。
- `nrows`:需要读取的行数。
- `na_values`:哪些值被视为空值。
df4 = pd.read_excel('小宝剑大药房2018年销售数据.xlsx',
usecols=['购药时间', '社保卡号', '商品名称', '销售数量', '应收金额', '实收金额'],
skiprows=lambda x: x > 0 and random.random() > 0.1
)
# sql中 ,con连接器,index_col索引行
sql = "SELECT confirmation_date,amount_total FROM sale_order WHERE state in ('done','sale')"
order = pd.read_sql_query(sql,con=self.env.cr._cnx,index_col ='confirmation_date')

read_csv/read_table



2.基本操作
DataFrame对象的属性
| 属性名 | 说明 |
|---|---|
at / iat |
通过标签获取DataFrame中的单个值。 |
columns |
DataFrame对象列的索引 |
dtypes |
DataFrame对象每一列的数据类型 |
empty |
DataFrame对象是否为空 |
loc / iloc |
通过标签获取DataFrame中的一组值。 |
ndim |
DataFrame对象的维度 |
shape |
DataFrame对象的形状(行数和列数) |
size |
DataFrame对象中元素的个数 |
values |
DataFrame对象的数据对应的二维数组 |
order.info() # 数据类型,内存消耗等信息
order.describe() # 统计特征,均值方差等
order.count() # 返回每一列的有效值个数
order.head(n=5) # 可以添加参数n,表示显示几行
order.tail()
# 选取索引的范围的行
order[(order.index>=td)&(order.index<nd)]
# 求和
order.sum()
# 保留小数位数
order.round(2)
np.around(order,0) # 也可以使用 np 中的保留位数
# 设置索引
order.set_index(keys=['confirmation_date'])
# 重设索引(可以将分组后的数据恢复为dataframe)
order.reset_index()
# 查找
df[df['Name']=='Squirtle']
# 查看所有Type1为Fire的数据
df[df['Type1'].isin(['Fire'])]
# 查看Generation为1并且攻击力大于100的宝可梦
df[(df['Generation']==1)&(df['Attack’]>=100)]
#数据访问方式(单行索引)
df.loc[3] # 访问行索引为3的数据
df.iloc[3] # 访问第4行数据,两行代码结果相同
#访问第1,2,6,9,10行
result.iloc[:, np.r_[0:1,5,8:9]]
算术运算
# 相加
df1 = pd.DataFrame(np.arange(12.).reshape((3, 4)), columns=list('abcd'))
df2 = pd.DataFrame(np.arange(20.).reshape((4, 5)), columns=list('abcde'))
df1+df2 # 缺失值填充NaN
df1.add(df2, fill_value=0) # 缺失值默认为0,
# r开头,默认翻转参数 --> 1/df1 == df1.rdiv(1)
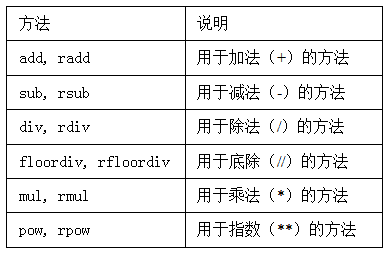
汇总运算

3.删除
# 删除 (~ 取反符号)
# axis=0 行 , 1 列
order[~order['product_uom_qty'].isin([0])] # 找到product_uom_qty不为0的 不影响之前的
order.drop(['product_uom_qty'],axis=1,inplace=True) # 删除列,在原DataFrame上改变
order.drop([1,2,3],axis=0) # 删除行索引为1、2、3的行,不在原DataFrame上改变
4.合并
# 合并
order.merge(invoice) # 可能出现NaN
#on="key" 以key关键字作为连接键。
#how = ['left','right','outer','inner'] 仅使用左边表的关键字,右边,交集,并集
#left : 仅考虑左边组合键的值
#right : 仅考虑右边组合键的值
#outer : 所有组合键的值,空值为NaN
#inner : 默认 ,所有组合键的有效值
5.排序
# 排序
order.sort_index(ascending=False) # 索引的倒序
6.去重
# subset 根据某一列(可以为多列相互比较),
#keep 保留方式(first(保留第一个)/last(保留最后一个)/False(都删除)) ,
#inplace直接删除重复行
order.drop_duplicates(subset=['product_id'],keep='first',inplace=True)
7.分组
df.groupby(['Generation']).count()
# 统计每一代的数目
df.groupby(['Generation']).mean()
# 查看每一代的数据均值
8.数据填充
# 统计NaN的个数
order.isnull().sum().sum()
# 将NaN 填充为 0
order.fillna(0)
# 去除所有包含空值的行
df.dropna(how='any')

9.数据转换
# 转化为 行 字典
order.to_dict('records')
10.匿名函数应用
#apply 通过匿名函数将所有数据HP值增加1
df['HP']=df['HP'].apply(lambda x:x+1)